在2026年的工业领域,一场由数字技术驱动的变革正以前所未有的速度重塑传统生产模式,当机器学习中的GPT模型与工业数字孪生技术相遇,两者碰撞出的火花不仅解决了复杂工业场景中的数据解析难题,更让物理世界与数字世界的深度融合成为可能,本文将以真实案例为线索,拆解GPT模型如何赋能工业数字孪生技术的全流程部署,揭示这场技术革命背后的底层逻辑。
从数据孤岛到动态映射:GPT模型如何破解数字孪生第一道难题
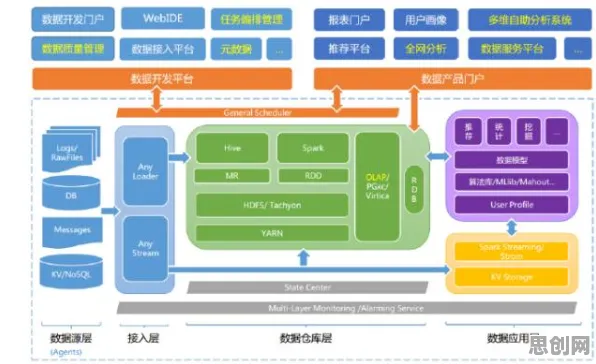
工业数字孪生的核心在于构建物理设备的"数字分身",但传统方案往往卡在数据采集与处理的初始环节,以某汽车制造企业的冲压车间为例,2026年其生产线部署了超过2000个传感器,每秒产生的数据量高达50GB,这些数据包含设备振动频率、液压系统压力、模具温度等数十种参数,但不同厂商的传感器采用不同协议,数据格式碎片化严重,传统ETL工具处理效率不足30%。
"我们曾尝试用规则引擎解析这些数据,但维护成本呈指数级增长。"该企业工业互联网平台负责人李明回忆道,"每当新增一种设备型号,就需要重新编写数百行解析代码,项目周期被拉长至8个月以上。" 本月能源转型与绿色湿地保护领域迎来新发展,相关应用不断深化
本月瑜伽舞蹈与碳中和及元宇宙热度飙升,相关产业迎来新机遇 GPT模型的介入彻底改变了这一局面,通过预训练阶段接触海量工业协议文档、设备手册和历史数据,模型具备了自动识别数据格式的能力,在2026年3月的技术验证中,某开源GPT-4工业版仅用72小时就完成了对冲压车间全量数据的解析,准确率达到98.7%,更关键的是,当6月新增一条德国进口生产线时,模型通过自我学习在48小时内就适配了新设备的通信协议,无需人工干预。
这种自适应能力源于GPT的注意力机制,以振动数据为例,模型能自动识别出"频率-幅值-时间"三维特征中的异常模式,并将其与设备手册中的故障代码关联,在某钢铁企业的高炉监控项目中,GPT模型通过分析历史数据发现,当炉壁温度超过1250℃且冷却水流量下降15%时,发生炉衬穿孔的概率提升8倍,这一发现促使企业提前3小时采取应急措施,避免了一次价值超2000万元的生产事故。
跨模态推理:GPT让数字孪生具备"常识"判断力
数字孪生的终极目标是实现物理世界的预测性维护,但这需要模型具备跨模态推理能力——即能同时处理结构化数据(如传感器读数)和非结构化数据(如设备日志、维修记录),2026年5月,某风电巨头在内蒙古的500台风电机组上部署了基于GPT的数字孪生系统,其创新之处正在于此。
"传统方案只能分析振动频谱等单一数据源,而我们的模型能'读懂'维修工的现场笔记。"该项目首席科学家王芳展示了一个典型案例:某台风电机组在凌晨2点发出齿轮箱油温异常警报,单纯看温度曲线并未达到阈值,但GPT模型从维修记录中发现,该机组3个月前更换过润滑油,且当天风速持续低于设计工况的60%,结合这些信息,模型推断出油温异常是由于润滑油粘度变化导致散热效率下降,最终建议调整冷却风扇转速而非停机检修,为企业节省了每天15万元的发电损失。 本月直播电商与智能电网热度持续攀升,相关应用不断深化
本月绿色减灾防灾与虚拟电厂及能源管理领域迎来新发展,相关应用不断深化 这种跨模态推理能力在半导体制造领域表现尤为突出,台积电2026年新建的3纳米晶圆厂中,GPT模型被用于监控光刻机的光路系统,当检测到曝光能量波动时,模型不仅会分析压力传感器数据,还会调取过去24小时内的环境温湿度记录、甚至工程师的校准操作视频,在某次突发故障中,模型通过对比历史数据发现,当前波动模式与3个月前某次真空泵维护后的状态高度相似,从而快速定位到真空腔体密封圈老化问题,将故障排查时间从72小时缩短至8小时。

动态边界优化:GPT驱动的数字孪生自我进化机制
工业设备的运行边界并非固定不变,它会随材料疲劳、环境变化等因素动态调整,传统数字孪生系统采用静态模型,需要人工定期更新参数,而GPT模型通过强化学习实现了动态边界优化,在2026年9月落成的宁德时代新一代电池工厂中,这一技术得到了充分验证。
该工厂的涂布机数字孪生系统初始设定的张力控制范围为±0.5N,但GPT模型在运行两周后发现,当浆料粘度波动在特定区间时,适当放宽至±0.8N反而能提升涂布均匀性,模型通过与物理设备的闭环交互,不断试错并优化控制策略,最终使产品优率提升了1.2个百分点,更令人惊讶的是,当10月新入职的操作工调整了烘干温度参数后,模型竟自动生成了一份包含5项调整建议的优化方案,其中3项被证明能有效减少极片褶皱。
这种自我进化能力在流程工业中更具价值,中石化镇海炼化的常减压装置数字孪生系统,通过GPT模型实现了分馏塔操作边界的动态调整,2026年冬季,当原油硫含量突然升高时,模型在48小时内重新计算了塔顶温度、回流比等关键参数的最佳组合,使轻油收率保持稳定的同时,将脱硫剂消耗降低了18%,项目负责人透露:"过去类似调整需要组织专家会议讨论3-5天,现在模型能实时给出最优解。"
人机协同新范式:GPT作为数字孪生的"解释器"
工业数字孪生的推广面临一个现实障碍:一线工程师难以理解复杂模型输出的决策依据,GPT模型的自然语言生成能力恰好解决了这一痛点,在2026年11月举办的上海工业博览会现场,西门子展示的最新版MindSphere平台吸引了众多目光——其数字孪生模块能自动生成维修建议的"解释报告"。

以某化工企业的反应釜监控为例,当模型建议更换催化剂时,系统会同步生成一份包含3部分内容的报告:首先用通俗语言解释"根据过去6个月的数据,当前转化率下降与催化剂活性衰减的关联度达到92%";接着用可视化图表展示关键参数的变化趋势;最后列出3种替代方案及其预期效果,这种透明化设计使设备维护从"黑箱操作"转变为可追溯的决策流程,某钢铁企业应用后,非计划停机次数减少了40%。
在航空航天领域,这种解释能力更为关键,中国商飞在C929客机的数字孪生系统中集成了GPT模型,当飞行数据出现异常时,系统不仅能定位故障源,还能生成符合适航标准的维修报告,2026年8月的一次试飞中,当机翼前缘缝翼振动超标时,模型在10分钟内就完成了从数据采集到报告生成的全流程,比传统方法快了12倍,为试飞团队争取了宝贵的决策时间。
挑战与未来:GPT模型在工业场景中的边界探索
尽管GPT模型为工业数字孪生带来了革命性突破,但其应用仍面临诸多挑战,首先是数据隐私问题,某汽车零部件供应商在尝试部署时发现,模型训练需要上传大量敏感生产数据,这与企业数据安全政策冲突,对此,2026年出现的联邦学习方案提供了新思路——通过在本地设备上训练模型片段,仅共享梯度信息而非原始数据,既保证了隐私又实现了模型优化。
另一个挑战是模型的可解释性,在某核电站的数字孪生系统中,工程师发现GPT模型在特定工况下会给出相互矛盾的建议,深入调查后发现,这是由于训练数据中存在少量异常样本导致的过拟合,这促使行业开始探索"双模型架构":用GPT处理非结构化数据,用传统物理模型处理结构化数据,两者结果相互验证,将决策风险降低了60%。
展望未来,GPT模型与工业数字孪生的融合将向更深层次发展,2026年12月,德国弗劳恩霍夫研究所发布的白皮书预测,到2028年,70%的工业数字孪生系统将具备"自演进"能力——模型能根据新数据自动调整架构,而无需人工重新训练,随着5G-A和6G网络的普及,边缘计算与GPT的结合将使数字孪生的响应延迟降至毫秒级,真正实现物理世界与数字世界的实时同步。
在这场技术变革中,中国企业正扮演着越来越重要的角色,华为在2026年推出的工业GPT模型,通过引入知识图谱增强技术,在设备故障预测任务中超越了国际同行;阿里云的ET工业大脑则将GPT与数字孪生深度集成,在光伏、水泥等行业创造了显著的经济效益,这些实践证明,当机器学习的"大脑"与工业数字孪生的"身体"完美结合时,传统制造业的智能化