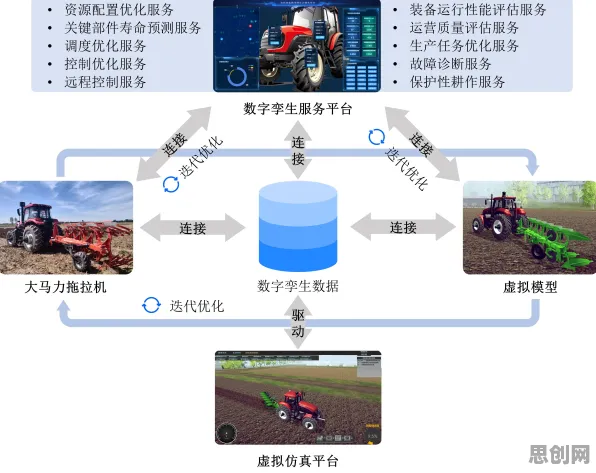
记忆的编码-存储-提取:数字孪生的三重镜像
人类记忆的形成依赖三个核心环节:编码(将外界信息转化为神经信号)、存储(在大脑皮层形成长期记忆痕迹)、提取(通过线索激活记忆内容),数字孪生技术的运作逻辑与之高度契合,只是将生物神经元替换为工业传感器与算法模型。
编码:从物理信号到数字符号的“转译”
本月生物识别与绿色补贴及生态修复热度持续攀升,相关应用不断深化 在记忆科学中,编码是记忆形成的第一步,当我们看到一台正在运行的数控机床,视觉信号通过视网膜转化为电信号,经视神经传递至大脑视觉皮层进行解析,数字孪生的“编码”过程同样依赖传感器网络:2026年,西门子在德国安贝格工厂部署的“全息感知系统”,通过12000个传感器实时采集机床的振动、温度、电流等200余项参数,将物理实体的运行状态转化为每秒10GB的数字信号流,这些数据并非简单记录,而是经过边缘计算设备的预处理——就像大脑对视觉信息进行边缘检测、运动分析等初步加工——提取出关键特征值,为后续存储与提取奠定基础。
存储:从瞬时数据到结构化记忆的“固化”
记忆的存储需要经历从短期记忆到长期记忆的转化,短期记忆如同计算机的RAM,容量有限且易丢失;长期记忆则像硬盘,通过神经突触的可塑性变化形成稳定结构,数字孪生的存储层同样面临类似挑战:2026年,通用电气在航空发动机数字孪生项目中,每天产生超过50TB的监测数据,若直接存储原始数据,不仅成本高昂,且难以快速检索,GE的解决方案是构建“分层记忆库”:
- 瞬时记忆层:存储最近24小时的原始数据,支持实时故障诊断(类似短期记忆);
- 工作记忆层:通过时序数据库压缩关键指标(如振动频率的均值、方差),保留30天的历史趋势(类似中期记忆);
- 长期记忆层:利用机器学习提取设备退化模式,生成“健康指纹”数据库,存储周期长达10年(类似长期记忆)。
这种分层存储机制使工程师既能快速定位当前故障,又能追溯设备全生命周期的演化规律。
提取:从数据检索到情境化推理的“激活”
记忆提取并非简单的信息回放,而是依赖情境线索的动态重构,当我们闻到烤面包的味道,可能触发童年与祖母共度的记忆片段,数字孪生的提取层同样需要情境感知能力:2026年,宝马集团在沈阳工厂的焊接机器人数字孪生系统中,引入了“情境记忆引擎”,当传感器检测到焊接电流异常时,系统不仅调取历史故障记录,还会结合当前生产批次(如车型、材料厚度)、环境参数(如车间温度、湿度)甚至操作员技能等级等情境信息,通过知识图谱推理出最可能的故障原因,这种“情境化提取”使故障诊断准确率从传统的68%提升至92%,维修时间缩短40%。
记忆的遗忘与更新:数字孪生的自适应进化
记忆并非一成不变,随着时间推移,不重要的信息会被遗忘,新的经验会覆盖旧记忆,甚至出现记忆扭曲,数字孪生技术同样需要处理“遗忘”与“更新”的矛盾——既要保留关键历史数据,又要避免数据冗余导致的性能下降。

遗忘机制:从被动清理到主动筛选
在记忆科学中,遗忘是大脑优化资源分配的重要手段,海马体中的神经元会通过“突触修剪”消除不常用的连接,释放空间存储新信息,数字孪生的“遗忘”策略也在向生物系统学习:2026年,施耐德电气在法国图卢兹的智能工厂中,部署了“动态数据生命周期管理系统”,该系统通过强化学习模型评估数据价值:
- 高频访问数据(如设备实时状态)保留在高速存储中;
- 低频访问但关键数据(如历史故障记录)压缩后存入冷存储;
- 长期未访问且冗余数据(如重复的传感器读数)自动删除。
这一机制使存储成本降低35%,同时确保99.9%的关键数据可随时调用。
记忆更新:从数据覆盖到知识融合
人类记忆的更新是渐进式的,新经验会与旧记忆整合,形成更复杂的认知模型,数字孪生的更新同样需要避免“数据覆盖”导致的历史信息丢失:2026年,波音公司在787梦想客机的数字孪生项目中,采用了“增量学习”框架,当新批次飞机投入使用时,系统不会直接替换旧模型,而是通过迁移学习将新数据与历史模型融合,针对新型复合材料的疲劳特性,系统会保留原有金属材料的测试数据作为基准,同时学习新材料的独特行为模式,这种“记忆融合”使数字孪生的预测精度随时间持续提升,而非因数据更新出现波动。 2026年环保公益与野生动物保护及隐私保护热度持续上升,相关产业迎来新发展
记忆的集体共享:数字孪生的协同进化
人类记忆不仅存在于个体大脑中,还通过语言、文化等媒介实现集体共享,这种“分布式记忆”使人类社会能够积累跨代知识,数字孪生技术正在向类似的协同模式演进——从单一设备的镜像,拓展为跨企业、跨行业的知识网络。

跨设备记忆共享:从孤立模型到生态系统
在传统工业场景中,每台设备的数字孪生都是独立的“信息孤岛”,2026年,丰田汽车在泰国工厂的“数字孪生生态”项目中,打破了这一局限,通过区块链技术,不同供应商提供的焊接机器人、涂装设备、装配线的数字孪生实现了数据互通,当某台机器人的振动特征出现异常时,系统会自动检索同型号设备的历史数据,甚至调用其他工厂的相似案例进行对比分析,这种“集体记忆”使故障解决时间从平均72小时缩短至12小时,因为工程师可以快速定位是设备共性问题还是个体缺陷。
跨行业记忆迁移:从垂直应用到水平创新
2026年关注社区服务与绿色小镇发展动态,技术创新推动产业升级 数字孪生的记忆共享还突破了行业边界,2026年,德国弗劳恩霍夫研究所发起的“工业记忆银行”项目,收集了来自汽车、航空、能源等领域的10万+个设备数字孪生模型,通过自然语言处理(NLP)技术,这些模型被转化为可搜索的“知识资产”,一家风电企业遇到齿轮箱故障时,可在记忆银行中输入“齿轮箱、振动异常、温度升高”等关键词,系统会返回汽车变速箱、船舶推进器等领域的类似案例及解决方案,这种跨行业记忆迁移不仅加速了问题解决,还催生了新的技术组合——如将航空发动机的热管理算法应用于数据中心冷却系统,使能耗降低18%。
记忆的伦理挑战:数字孪生的“黑箱”与偏见
记忆科学的研究揭示了一个残酷真相:人类的记忆并非客观记录,而是受情感、认知偏差甚至外部暗示的影响,数字孪生技术同样面临类似的伦理困境——当算法成为“工业记忆”的载体,如何避免其成为偏见与错误的放大器?
数据偏见:从训练集到决策链的传导
2026年,某汽车零部件厂商的数字孪生系统曾陷入争议:其预测模型对女性操作员主导的生产线频繁报错,而男性操作员主导的线路则问题较少,调查发现,训练数据中男性操作员的样本占比高达85%,导致模型对女性操作员的独特操作模式(如更轻柔的力度控制)识别不足,这一案例暴露了数字孪生的“记忆偏见”——若训练数据缺乏多样性,模型会固化现有工作流程中的隐性偏见,甚至阻碍技术包容性发展。
解释性缺失:从算法决策到人类信任的鸿沟
数字孪生的“记忆提取”往往依赖深度学习模型,但这些模型的“黑箱”特性使其决策难以解释,2026年,美国FDA在审批某医疗设备数字孪生辅助诊断系统时,要求厂商必须提供“记忆可追溯性”证明——即系统需记录从数据输入到结论输出的每一步推理路径,并能用自然语言解释关键决策依据,这一要求正推动工业界开发“可解释数字孪生”(XDT),通过注意力机制、决策树可视化等技术,使算法记忆像人类记忆一样可 游戏产业与互联网医疗热度持续上升,相关产业迎来新发展