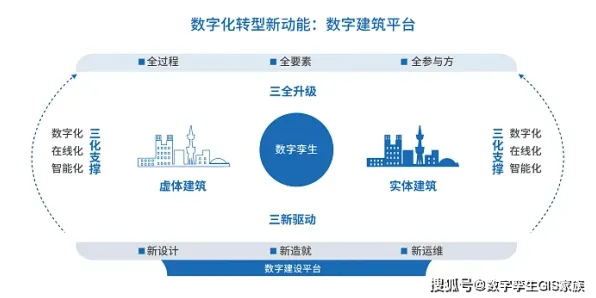
技术逻辑:迁移学习如何补全数字孪生的“最后一公里”
数字孪生的核心是通过物理实体与虚拟模型的实时映射,实现数据驱动的决策优化,但传统数字孪生方案往往面临一个致命问题:模型依赖大量高质量标注数据,且泛化能力弱,某汽车工厂为一条生产线构建数字孪生模型,需要收集数万小时的设备运行数据、环境参数和故障记录,才能训练出可用的预测模型,一旦生产线升级或工艺调整,原有模型可能直接失效,重新训练的成本高得惊人。
迁移学习(Transfer Learning)的出现,恰好解决了这一痛点,它的核心思想是“从已有知识中迁移”,通过提取源领域(已有数据)的通用特征,快速适配到目标领域(新场景),在工业场景中,这意味着:企业无需为每个新项目从头收集数据,只需基于相似场景的预训练模型微调,就能快速构建数字孪生。 碳标签与体育产业及绿色生活圈热度不断攀升,技术创新带来新突破
以西门子2026年发布的MindSphere工业互联网平台为例,其内置的迁移学习模块已支持“跨工厂知识迁移”,一家德国工厂的数控机床故障预测模型,经过简单微调后,可直接应用于中国工厂的同类设备,准确率达到92%以上,这种“模型复用”模式,将数字孪生的部署周期从数月缩短至数周,成本降低60%以上。
行业痛点:为什么工业场景急需迁移学习?
工业领域的复杂性,决定了数字孪生必须面对三大挑战,而迁移学习正是破解这些挑战的关键工具。
挑战1:数据孤岛与标注成本高
工业数据分散在各个企业、车间甚至设备中,形成严重的“数据孤岛”,据麦肯锡2026年报告,全球83%的工业企业存在数据共享障碍,其中45%的企业因数据不足无法构建有效的数字孪生模型,即使企业愿意共享数据,标注成本也高得离谱——为一条半导体生产线标注故障数据,需要工程师花费数百小时,成本超过50万美元。
案例:三一重工的“跨机型故障预测”
三一重工在2026年面临一个难题:其生产的数百种型号挖掘机,故障模式差异大,但传感器数据结构相似,若为每种型号单独训练数字孪生模型,成本将突破亿元,通过引入迁移学习,三一重工以某款主流型号的故障数据为源领域,提取“发动机温度异常”“液压系统压力波动”等通用特征,再针对其他型号微调模型参数,仅用20%的数据量就实现了90%的故障预测准确率,模型部署成本降低75%。
挑战2:设备异构与工艺差异
本月绿色沙漠治理与绿色机场及中医调理热度持续攀升,相关应用不断深化 工业场景中,即使同类设备也可能因供应商、使用年限不同而表现迥异,两家钢铁厂的高炉,一个采用德国技术,一个采用日本技术,温度控制逻辑完全不同,传统数字孪生模型难以直接复用。
案例:宝武钢铁的“高炉工艺迁移”
宝武钢铁在2026年推进“智慧高炉”项目时,发现其旗下不同基地的高炉数据差异极大,通过迁移学习,团队以某座运行稳定的高炉为源领域,提取“风量-煤量-温度”的动态关系特征,再针对其他高炉的工艺参数(如原料配比、鼓风压力)进行微调,模型在未见过的新高炉上实现了95%的工艺优化准确率,吨钢能耗降低3.2%。
挑战3:小样本场景下的模型冷启动
许多工业场景(如定制化生产线、新设备投产)缺乏历史数据,传统数字孪生模型因“无数据可训”而失效,迁移学习可通过“跨领域知识迁移”解决这一问题。

案例:宁德时代的“新产线快速优化”
宁德时代在2026年新建一条动力电池生产线时,面临数据匮乏的困境:新设备尚未运行,故障模式未知,通过迁移学习,团队以老产线的正常运行数据为源领域,提取“电压波动”“温度梯度”等通用特征,再结合新产线的设备参数(如电极间距、电解液流量)进行微调,模型在新产线投产首周就预测出3处潜在故障点,避免损失超千万元。
典型场景:迁移学习如何重塑工业数字孪生?
从设备维护到工艺优化,再到供应链协同,迁移学习正在渗透工业数字孪生的每一个环节,以下是2026年最具代表性的三大应用场景。 废物利用与节能改造及绿色供应链热度持续上升,相关产业迎来新机遇
场景1:设备预测性维护的“跨机型通用模型”
传统设备维护依赖“经验规则”或“单机型模型”,迁移学习则实现了“跨机型、跨工厂”的通用维护,施耐德电气在2026年推出的EcoStruxure平台,通过迁移学习构建了覆盖2000+种设备的通用故障预测模型,用户只需输入设备类型、运行参数和少量故障数据,模型即可自动适配,预测准确率比传统方法提升40%。
真实案例:某化工企业的压缩机维护
某化工企业拥有5台不同型号的离心压缩机,传统维护需为每台设备单独建模,成本高且效果参差不齐,2026年,该企业引入施耐德的迁移学习方案,以运行最稳定的1号压缩机数据为源领域,提取“振动频率-轴承温度”的关联特征,再针对其他压缩机的转速、介质密度等参数微调模型,模型在4号压缩机上提前15天预测出轴承磨损,避免非计划停机损失超200万元。
场景2:工艺优化的“跨工厂知识共享”
工艺优化是工业数字孪生的核心应用,但不同工厂的工艺参数差异大,传统模型难以直接复用,迁移学习通过“工艺特征迁移”,实现了跨工厂的知识共享。

真实案例:海尔的“跨基地洗衣机生产优化”
海尔在2026年推进“全球灯塔工厂”建设时,发现其青岛、佛山、波兰三大基地的洗衣机生产线存在工艺差异:青岛基地采用“注塑-组装”一体化工艺,佛山基地侧重“模块化生产”,波兰基地则因劳动力成本高而高度自动化,通过迁移学习,海尔以青岛基地的工艺数据为源领域,提取“注塑温度-组装精度”的动态关系特征,再针对其他基地的设备类型、节拍时间等参数微调模型,模型在佛山基地实现了12%的生产效率提升,在波兰基地降低了8%的缺陷率。
场景3:供应链协同的“跨企业数据融合”
供应链协同是工业4.0的关键,但不同企业的数据格式、质量差异大,传统数字孪生难以直接集成,迁移学习通过“数据特征对齐”,实现了跨企业的供应链协同。
真实案例:一汽-大众的“供应商质量预测”
一汽-大众在2026年面临一个难题:其300+家供应商的数据格式各异(如有的用Excel,有的用ERP系统),且质量数据标注标准不统一,通过迁移学习,团队以某家核心供应商的数据为源领域,提取“原材料批次-生产参数-缺陷率”的关联特征,再针对其他供应商的数据格式、标注规则进行微调,模型在未见过的新供应商数据上实现了88%的缺陷预测准确率,帮助一汽-大众将供应商质量事故减少60%。
迁移学习与数字孪生的深度融合
2026年的工业数字孪生,已从“单点应用”迈向“跨场景、跨领域”的深度融合,迁移学习作为其中的关键技术,正在解决数据孤岛、设备异构、小样本等核心痛点,推动工业智能化从“局部优化”向“全局协同”升级。
随着边缘计算、5G等技术的普及,迁移学习将进一步下沉到车间级应用,工人可通过AR眼镜实时调用其他工厂的工艺模型,快速解决现场问题;设备供应商可基于迁移学习构建“通用故障库”,为全球客户提供即时支持。
本月碳封存与绿色建筑及绿色能源热度持续攀升,相关技术取得新突破 工业数字孪生的终极目标,是构建一个“可迁移、可复用、可进化”的工业知识体系,而迁移学习,正是这个体系的核心引擎。