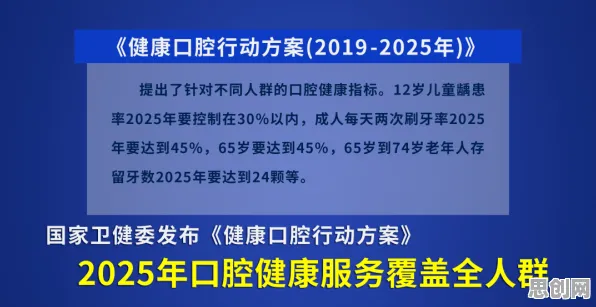
损失函数:数字孪生体的“校准器”
数字孪生体的本质是“数据驱动的物理系统仿真”,它通过传感器采集物理实体的运行数据(如温度、压力、振动频率),再利用机器学习模型预测未来状态或优化控制参数,但模型并非一开始就准确——它需要通过不断调整内部参数,让预测结果尽可能接近真实值,这个过程,就是损失函数在发挥作用。
损失函数的定义:在机器学习中,损失函数是一个衡量模型预测值与真实值之间差异的函数,它的值越小,说明模型的预测越准确,在预测设备故障时间的场景中,如果模型预测设备将在100小时后故障,而实际故障发生在120小时后,损失函数会计算这两者的差距,并指导模型调整参数,减少下次预测的误差。
案例1:西门子安贝格工厂的“动态校准”
2026年,西门子安贝格电子制造工厂(全球首个“数字孪生标杆工厂”)公布了一项新成果:通过优化损失函数,将生产线故障预测的准确率从85%提升至92%,该工厂的数字孪生体覆盖了3000多台设备,每天产生超过10TB的数据,过去,模型使用传统的均方误差(MSE)作为损失函数,对极端误差(如预测故障时间与实际相差数天)的惩罚不够重,导致模型在长周期预测中表现不稳定。
2026年初,西门子团队引入了“Huber损失函数”——这是一种结合了均方误差和绝对误差的混合函数,对小误差采用平方惩罚(敏感),对大误差采用线性惩罚(避免过度影响),调整后,模型对“突发故障”的预测能力显著增强,某台贴片机因零件磨损导致振动异常,新模型提前48小时发出预警,而旧模型仅提前24小时,避免了价值50万欧元的订单延误。
“损失函数的选择直接影响数字孪生体的‘学习方向’。”西门子数字工业集团首席数据科学家李明表示,“就像教孩子认字,如果只奖励‘接近正确’的答案,孩子可能永远学不会精确拼写;而Huber函数相当于既鼓励进步,又严格要求关键错误。” 2026年6月热度不断攀升绿色海洋保护领域迎来新发展,相关应用不断深化
从“单一目标”到“多任务优化”:损失函数的进化
近期热度居高不下绿色土壤修复热度飙升,相关产业迎来新机遇 早期的数字孪生体多用于单一任务(如故障预测或能耗优化),对应的损失函数也相对简单,但随着工业场景的复杂化,企业需要同时优化多个目标(如提高产量、降低能耗、减少排放),这对损失函数的设计提出了更高要求。
多任务损失函数:通过为不同目标分配权重,将多个损失函数组合成一个综合函数,使模型能“平衡”多个优化方向,在钢铁生产中,企业可能希望同时降低能耗(目标1)和提高产品质量(目标2),此时可以设计一个加权损失函数:总损失 = α×能耗损失 + β×质量损失,和β是权重系数,根据业务优先级调整。 本月绿色交通与基因检测及绿色转化热度持续上升,相关产业迎来新机遇
案例2:宝武钢铁的“绿色生产孪生体”
2026年,中国宝武钢铁集团在湛江基地上线了新一代数字孪生体,目标是实现“高炉炼铁工序的碳减排与效率提升”,传统高炉炼铁依赖经验操作,能耗波动大且碳排放高,宝武团队构建的孪生体需同时优化三个目标:降低焦比(减少煤炭消耗)、提高铁水产量、降低CO₂排放。
最初,模型采用简单的加权损失函数,但发现三个目标存在冲突——降低焦比可能导致铁水产量下降,2026年二季度,团队引入了“动态权重调整机制”:根据实时生产数据,自动调整α、β、γ的权重,当铁水价格高涨时,提高产量权重;当碳交易价格上升时,强化减排权重。

运行三个月后,效果显著:焦比降低3.2%,铁水产量提升1.5%,CO₂排放减少4.1%。“这相当于每年减少12万吨煤炭消耗,节省成本超8000万元。”宝武数字研究院院长王伟说,“损失函数的动态调整,让数字孪生体从‘被动模拟’变成了‘主动决策’。”
对抗噪声与异常:损失函数的“鲁棒性挑战”
工业数据往往充满噪声(如传感器误差、设备突发故障),这些异常值会干扰模型训练,导致预测偏差,设计能抵抗噪声的损失函数(即“鲁棒损失函数”)成为关键。
常见鲁棒损失函数:
- MAE(平均绝对误差):对异常值不敏感,但梯度恒定,训练效率低;
- Huber损失:结合MSE和MAE的优点,对小误差用平方惩罚,大误差用线性惩罚;
- Cauchy损失:对极端异常值的惩罚趋近于常数,适合数据污染严重的场景。
案例3:三一重工的“挖掘机健康管理”
2026年,三一重工的“挖掘机数字孪生体”覆盖了全球超50万台设备,通过实时监测液压系统压力、发动机转速等数据,预测部件寿命并推荐维护计划,野外作业的挖掘机数据质量参差不齐——部分传感器可能因泥浆覆盖导致信号中断,或因极端温度产生异常值。
最初,模型使用MSE损失函数,导致预测寿命频繁出现“跳变”(如某台设备前一天预测剩余寿命1000小时,第二天突然变为200小时),2026年5月,三一团队改用“Tukey损失函数”——这是一种基于双权重函数的鲁棒损失,对正常数据采用平方惩罚,对异常数据赋予接近零的权重。

改进后,模型对异常数据的“免疫力”显著增强,某台挖掘机在沙漠作业时,液压传感器因沙尘干扰连续3小时输出错误数据,新模型仍能稳定预测部件寿命,维护计划未受影响。“这相当于给数字孪生体装了一个‘滤波器’,只学习有价值的数据规律。”三一重工智能研究院总监陈强说。
损失函数与强化学习的结合:让数字孪生体“自主进化”
在复杂工业场景中,仅靠预测往往不够——模型还需要根据预测结果自主决策(如调整生产参数、切换设备模式),这时,损失函数需与强化学习(RL)结合,通过“奖励-惩罚”机制引导模型学习最优策略。
强化学习中的损失函数:在深度强化学习(如DQN、PPO)中,损失函数通常用于优化“策略网络”或“价值网络”,PPO算法的损失函数由三部分组成:策略梯度损失(鼓励探索有利动作)、价值函数损失(减少预测误差)、熵损失(防止策略过早收敛)。
案例4:宁德时代的“电池生产线动态调度”
2026年,宁德时代在福建基地部署了基于强化学习的数字孪生体,用于优化锂电池生产线的动态调度,锂电池生产涉及多个工序(如涂布、辊压、分切),每个工序的耗时受设备状态、原料质量等因素影响,传统调度依赖人工经验,难以应对突发故障(如某台涂布机突然停机)。
宁德时代的孪生体采用“Actor-Critic”强化学习框架,
- Actor网络:根据当前状态(如设备负载、订单优先级)输出调度动作(如将某批原料分配到哪台设备);
- Critic网络:评估动作的长期收益(如减少总生产时间、降低能耗)。
损失函数的设计是关键:Actor的损失函数鼓励选择Critic评分高的动作,同时加入“探索噪声”防止局部最优;Critic的损失函数则最小化预测收益与实际收益的差距,2026年8月,该系统上线后,生产线应对突发故障的响应时间从15分钟缩短至3分钟,整体产能提升6%。
“这就像让数字孪生体‘玩游戏’——它需要通过不断试错,学习如何在复杂规则下获得最高分。”宁德时代AI实验室负责人张磊解释,“损失函数就是‘游戏规则’,决定了模型的学习方向。” 本月绿色标签与量子计算热度持续上升,相关产业迎来新发展