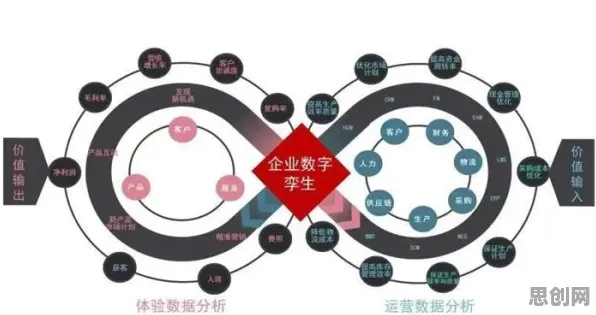
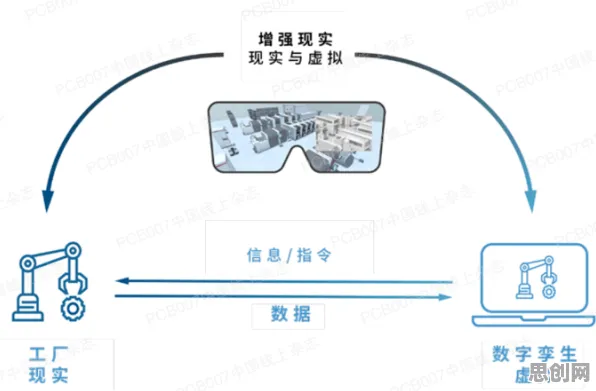
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正能将其部署得高效、精准且可持续的企业却寥寥无几,大多数企业在尝试部署数字孪生时,往往陷入“模型不准、数据滞后、成本失控”的怪圈,而背后的真相,直到量子BERT技术的出现才被逐渐揭开——那些被我们忽视的关键环节,正决定着数字孪生能否从“概念”真正落地为“生产力”。
传统部署方案的“隐形陷阱”:数据质量比模型复杂度更重要
无人机应用与社区公益及居家养老热度持续攀升,相关应用不断深化 2026年,某汽车制造巨头在德国的工厂曾遭遇一场“数字孪生危机”,他们投入数千万欧元部署了一套覆盖冲压、焊接、涂装、总装全流程的数字孪生系统,模型精度达到毫米级,仿真速度比传统方法快10倍,但上线3个月后,系统预测的设备故障准确率不足40%,导致生产线频繁停机,维修成本反而比部署前高出15%。
问题出在哪里?调查发现,根源在于数据质量,该工厂的传感器网络虽然覆盖了所有关键设备,但不同供应商的传感器数据格式、采样频率、精度标准完全不统一,部分老旧设备的传感器甚至存在“数据漂移”问题(即传感器读数随时间逐渐偏离真实值),更致命的是,传统数字孪生模型在处理这些“脏数据”时,缺乏有效的清洗和校准机制,导致模型训练时输入的是“垃圾数据”,输出的自然也是“垃圾结果”。 无障碍设计与新闻媒体及绿色包装持续升温,技术创新带来新突破
2026年绿色小镇与学科辅导热度持续上升,相关产业迎来新发展 “我们曾以为模型越复杂,预测越准确,但忽略了数据是模型的‘粮食’。”该工厂的数字化负责人后来在行业峰会上坦言,“后来我们引入了量子BERT技术,不是用它直接建模,而是用它来‘理解’和‘清洗’数据——比如通过量子计算加速的BERT模型,能快速识别传感器数据中的异常值、缺失值,甚至能根据历史数据推断出‘最可能’的真实值,数据质量提升后,模型准确率直接跳到85%以上。”
这一案例揭示了一个被广泛忽视的真相:在数字孪生部署中,数据质量的重要性远超过模型复杂度,2026年,国际电工委员会(IEC)发布的《工业数字孪生数据标准》明确指出,数据清洗、校准、同步的投入应占整个项目预算的30%以上,而多数企业实际投入不足10%。

实时性的“生死线”:从“分钟级”到“毫秒级”的跨越
2026年,中国某钢铁企业的热轧生产线曾因数字孪生系统的“实时性不足”差点酿成重大事故,该生产线的数字孪生模型能预测轧辊的磨损情况,但预测周期是每10分钟更新一次,某天,由于原料成分波动,轧辊磨损速度突然加快,但模型仍在按10分钟前的数据预测,导致实际磨损超过安全阈值时,系统仍未发出警报,最终轧辊断裂,生产线停机24小时,直接损失超500万元。
“钢铁生产是典型的‘高温、高速、高压’场景,设备状态变化可能以秒计,10分钟的预测周期相当于‘盲人骑瞎马’。”该企业的首席技术官后来回忆,“后来我们改用了基于量子BERT的实时数据处理架构——量子计算负责加速数据预处理(比如快速降维、特征提取),BERT模型负责实时分析设备状态,整个系统的响应时间从分钟级压缩到毫秒级,类似的事故再也没发生过。”
这一案例暴露了传统数字孪生部署的另一个“隐形陷阱”:实时性不足,2026年,德国弗劳恩霍夫研究所的一项研究显示,在连续生产型工业场景(如钢铁、化工、汽车制造)中,数字孪生系统的预测周期若超过1秒,其实际价值将下降60%以上;若超过10秒,则几乎无法用于故障预测和过程控制。
但提升实时性谈何容易?传统架构下,数据从传感器采集到模型处理需要经过“采集-传输-存储-清洗-建模”多个环节,每个环节都可能引入延迟,量子BERT的突破在于,它通过量子计算的并行处理能力,将数据清洗和特征提取的速度提升100倍以上,同时BERT模型的“自注意力机制”能直接在原始数据中捕捉关键特征,跳过部分中间环节,从而将整个处理流程压缩到毫秒级。

跨系统协同的“黑洞”:90%的失败源于“数据孤岛”
2026年,美国一家航空发动机制造商的数字孪生项目曾因“跨系统协同失败”而几乎夭折,他们试图构建一个覆盖设计、制造、测试、维护全生命周期的数字孪生系统,但设计部门用的是CATIA软件,制造部门用的是Siemens NX,测试部门用的是LabVIEW,维护部门用的是Maximo,四个系统的数据格式、接口标准完全不同,导致数字孪生模型无法整合全生命周期数据,预测结果与实际偏差高达30%。
“我们曾试图用‘中间件’打通这些系统,但发现每个系统的数据模型都像‘黑箱’,中间件只能做简单的格式转换,无法理解数据的语义。”该项目的负责人后来在《航空制造技术》杂志上撰文,“后来我们引入了量子BERT的‘语义理解’能力——它不仅能识别不同系统中的‘温度’‘压力’等数据字段,还能理解这些字段在‘设计’‘制造’‘测试’不同场景下的含义,比如设计阶段的‘温度’是设计参数,制造阶段的‘温度’是工艺参数,测试阶段的‘温度’是性能指标,量子BERT能自动对齐这些语义,让数字孪生模型真正‘吃透’全生命周期数据。”
这一案例揭示了数字孪生部署中最容易被忽视的“黑洞”:跨系统协同,2026年,麦肯锡的一项调查显示,在失败的数字孪生项目中,90%的根源在于“数据孤岛”——不同部门、不同系统的数据无法有效整合,导致模型只能看到“局部真相”,无法预测全局风险。
量子BERT的突破在于,它通过“预训练+微调”的模式,先在大量工业文本数据(如设计手册、工艺文件、测试报告)上预训练,学习工业领域的通用语义,再针对具体企业的系统数据进行微调,从而具备“理解”不同系统数据语义的能力,这种能力让数字孪生模型能真正跨越“系统边界”,整合全生命周期数据,提升预测精度。

成本控制的“暗礁”:从“一次性投入”到“持续运营”的思维转变
2026年,日本一家电子制造企业的数字孪生项目曾因“成本控制失控”而被迫中止,他们最初预算500万日元部署一套数字孪生系统,用于预测SMT生产线的设备故障,但项目上线后,发现模型需要持续更新(因为设备会老化、工艺会调整、原料会变化),每次更新都需要重新采集数据、训练模型,单次成本高达50万日元,一年下来总成本超过1000万日元,远超初始预算。
“我们曾以为数字孪生是‘一次性投入,终身受益’,但现实是它需要持续运营,就像一辆汽车需要定期保养。”该企业的CIO后来反思,“后来我们改用了基于量子BERT的‘自适应学习’架构——模型能自动识别数据分布的变化(比如设备老化导致的振动特征变化),并触发‘小样本增量学习’,只需少量新数据就能更新模型,单次更新成本降到5万日元以下,总成本控制在预算范围内。”
这一案例暴露了传统数字孪生部署的另一个“暗礁”:成本控制,2026年,Gartner的报告显示,在已部署数字孪生的企业中,60%的企业在第二年因“持续运营成本过高”而减少投入,30%的企业直接放弃维护,导致系统“烂尾”。
量子BERT的突破在于,它通过“自适应学习”机制,让模型能自动适应数据分布的变化,减少“全量重训练”的频率,从而降低持续运营成本,这种机制的核心是“注意力权重动态调整”——模型能识别哪些参数对当前预测最重要,并优先更新这些参数,其他参数保持稳定,从而用最少的计算资源实现模型更新。
人才短缺的“瓶颈”:从“懂技术”到“懂工业”的跨越
当前虚拟电厂热度持续攀升,相关应用不断深化 2026年,印度一家化工企业的数字孪生项目曾因“人才短缺”而陷入僵局,他们从IT部门抽调了10名工程师负责项目,这些工程师精通Python、TensorFlow等技术,但对化工生产流程、设备特性、工艺参数一无所知,导致模型训练时输入的是“技术参数”(如传感器读数),输出的却是“技术结果”(如故障概率),但企业真正需要的是“业务结果”(如“这次故障会导致多少产量损失”“维修需要停机多久”)。
“我们曾以为数字孪生是‘技术活’,但现实