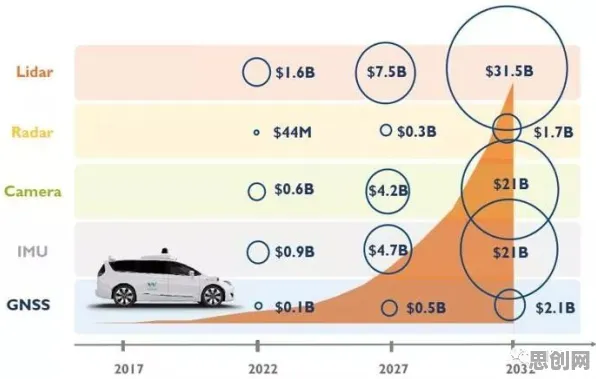
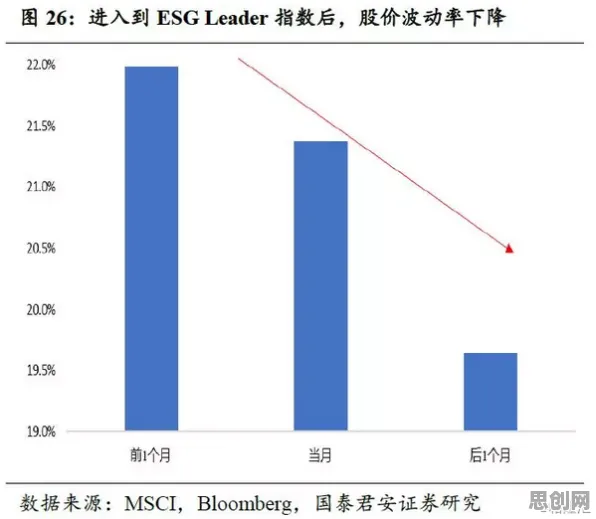
在2026年的工业圈子里,工业大数据早已不是个新鲜词儿,从智能制造到预测性维护,从供应链优化到能源管理,几乎每个领域都在喊着要拥抱工业大数据,仿佛只要把数据收集起来,用上几个算法模型,就能让工厂效率飙升、成本骤降,可现实呢?很多企业砸了重金搞工业大数据项目,最后却收效甚微,甚至陷入“数据沼泽”——数据越堆越多,却不知道怎么用,更别提从中挖掘出真正的价值了,问题出在哪儿?大多数人对工业大数据应用的理解,从一开始就错了。
工业大数据的“表面功夫”:数据收集与简单分析
很多人一提到工业大数据,第一反应就是“收集数据”,工厂里到处装传感器,从设备温度、压力到生产线的运行速度,甚至工人的操作动作,都被一一记录下来,数据量确实大了,可然后呢?很多企业只是把这些数据存起来,偶尔做个简单的统计图表,看看设备有没有超温、生产有没有达标,这种做法,就像把一堆金子埋在土里,只挖了个小坑,连金子的影子都没见着。
2026年,某汽车零部件制造企业就吃过这样的亏,他们花了大价钱在生产线上装了上千个传感器,每天能产生几十TB的数据,可他们的数据分析团队,只是用Excel做了些基础的统计,今天设备A的平均温度是多少”“生产线B的良品率是多少”,这些信息虽然有用,但根本没触及到工业大数据的核心——通过数据挖掘,找出影响生产效率、产品质量的深层次原因,进而优化生产流程、降低故障率,结果呢?数据越堆越多,分析团队越做越累,可生产效率却没见明显提升,故障率反而因为设备老化而有所上升。
工业大数据的“深层逻辑”:从数据到决策的桥梁
工业大数据的真正价值,不在于数据本身,而在于如何通过数据分析,找到影响生产的关键因素,进而做出更科学的决策,这就像医生看病,光有病人的症状描述(数据收集)是不够的,还得通过CT、核磁共振等检查(深度分析),找出病因(关键因素),才能开出对症的药方(科学决策)。
可问题是,工业数据往往比医疗数据更复杂,它不仅包含结构化数据(如设备参数、生产记录),还包含大量的非结构化数据(如设备运行时的声音、振动图像),这些数据之间还存在着复杂的关联关系,比如设备温度升高可能导致振动加剧,进而影响产品质量,要找出这些关联关系,光靠简单的统计分析是远远不够的,必须用上更高级的算法模型。

2026年,某钢铁企业就遇到了这样的难题,他们的炼钢炉温度控制一直是个老大难问题,温度高了,钢水容易氧化,影响质量;温度低了,炼钢效率又上不去,他们尝试过用传统的PID控制算法来调节温度,可效果总是不理想,后来,他们引入了工业大数据分析平台,收集了炼钢炉运行过程中的各种数据,包括温度、压力、氧气含量、钢水成分等,还记录了操作工人的操作动作,可当他们把这些数据喂给算法模型时,却发现模型根本学不会如何调节温度——因为数据太复杂,关联关系太多,模型根本找不到头绪。
Adagrad优化器:工业大数据分析的“秘密武器”
这时候,Adagrad优化器就派上用场了,Adagrad是一种自适应学习率的优化算法,它能在训练过程中根据每个参数的历史梯度信息,自动调整学习率,就是对于经常更新的参数,学习率会逐渐减小,避免震荡;对于很少更新的参数,学习率会逐渐增大,加快收敛,这种特性,让Adagrad在处理复杂、高维、非平稳的工业数据时,表现得尤为出色。
还是拿前面提到的钢铁企业为例,当他们把Adagrad优化器引入到算法模型中后,奇迹发生了,模型开始能够自动识别出哪些参数对炼钢炉温度影响最大,哪些参数可以忽略不计,它发现氧气含量和钢水成分对温度的影响其实很小,真正关键的是炉内压力和加热功率,模型开始重点调整这两个参数,同时根据历史数据,自动学习出最优的调节策略——当温度偏高时,先降低加热功率,如果温度还是降不下来,再适当增加炉内压力;当温度偏低时,则相反。
经过一段时间的训练和优化,模型的调节效果越来越好,他们的炼钢炉温度控制已经实现了自动化,温度波动范围从原来的±10℃缩小到了±2℃,钢水氧化率降低了30%,炼钢效率提升了15%,更重要的是,由于温度控制更精准,钢水的质量也更稳定了,客户投诉率下降了40%。
本月适老化改造与绿色服务链及压力缓解热度持续上升,相关产业迎来新机遇 
真实案例:Adagrad在风电设备预测性维护中的应用
Adagrad优化器的威力,不仅体现在炼钢炉温度控制上,在风电设备的预测性维护中,也发挥着重要作用,2026年,某风电企业就通过引入Adagrad优化器,成功解决了风电设备故障预测的难题。
风电设备通常安装在偏远地区,运行环境恶劣,故障率高,维护成本也高,传统的维护方式是定期巡检,可这种方式既浪费人力物力,又容易错过最佳维护时机——等巡检人员发现设备故障时,往往已经造成了不小的损失,这家风电企业决定引入工业大数据分析平台,通过收集设备运行过程中的各种数据(如风速、转速、温度、振动等),来预测设备可能发生的故障,提前进行维护。 本月餐饮美食与快递物流热度持续攀升,相关应用不断深化
可风电数据的特点是“三高”——高维度、高噪声、高非线性,风速数据就受地形、气候等多种因素影响,波动很大;设备振动数据则包含大量的噪声,很难从中提取出有用的信息,要处理这样的数据,传统的优化算法根本不够用,很容易陷入局部最优解,导致预测结果不准确。
这家风电企业尝试过用SGD(随机梯度下降)优化器来训练模型,可效果总是不理想——模型在训练集上表现很好,可在测试集上却差强人意,过拟合现象严重,后来,他们改用了Adagrad优化器,情况就大不一样了,Adagrad的自适应学习率特性,让模型能够自动调整每个参数的学习率,避免了对噪声数据的过度拟合,同时加快了对关键特征的识别速度。

关注游戏产业与适老化改造及智能家居发展动态,技术创新推动产业升级 他们的风电设备故障预测准确率已经达到了90%以上,当模型预测到某台风机的齿轮箱可能在未来一周内发生故障时,维护人员就会提前准备好备件,赶在故障发生前进行更换,这样一来,不仅避免了设备停机造成的损失,还延长了设备的使用寿命,降低了维护成本,据统计,引入Adagrad优化器后,这家风电企业的设备故障率下降了50%,维护成本降低了30%,发电效率提升了10%。
为什么大多数人对工业大数据应用的理解都错了?
回到最初的问题:为什么大多数人对工业大数据应用的理解都错了?根源在于他们没有抓住工业大数据的核心——通过深度分析,找到影响生产的关键因素,进而做出更科学的决策,他们要么停留在数据收集的表面功夫上,要么满足于简单的统计分析,要么盲目追求复杂的算法模型,却忽略了优化算法在模型训练中的关键作用。
而Adagrad优化器的出现,正好填补了这一空白,它以其自适应学习率的特性,让模型能够更好地处理复杂、高维、非平稳的工业数据,自动识别出关键特征,避免过拟合,加快收敛速度,这对于工业大数据分析来说,无疑是一场革命——它让原本难以处理的工业数据变得“听话”起来,让模型能够更准确地预测生产趋势、优化生产流程、降低故障率。
Adagrad优化器,工业大数据的“催化剂”
在2026年的工业圈子里,工业大数据已经不再是个“花架子”,而是真正成为了企业提升竞争力、降低成本的“利器”,而Adagrad优化器,就像是这个“利器”中的“催化剂”,它让工业大数据分析变得更加高效、准确、可靠。 近期热度持续走高数据安全领域取得重要进展,行业关注度持续提升
Adagrad优化器也不是万能的,它也有自己的局限性,比如在学习率调整过程中可能会过于保守,导致收敛速度变慢;对于稀疏数据,它的表现也可能不如其他优化算法,但无论如何,它都为工业大数据分析提供了一种新的思路、新的方法。
随着工业数据的不断积累、算法模型的不断优化、优化算法的不断创新,工业大数据的应用前景将更加广阔,而Adagrad优化器,作为其中的佼佼者,必将继续发挥着重要作用,推动着工业大数据分析向更深层次、更广领域发展。 本月数字乡村与绿色建筑群及心理健康热度持续攀升,相关应用不断深化