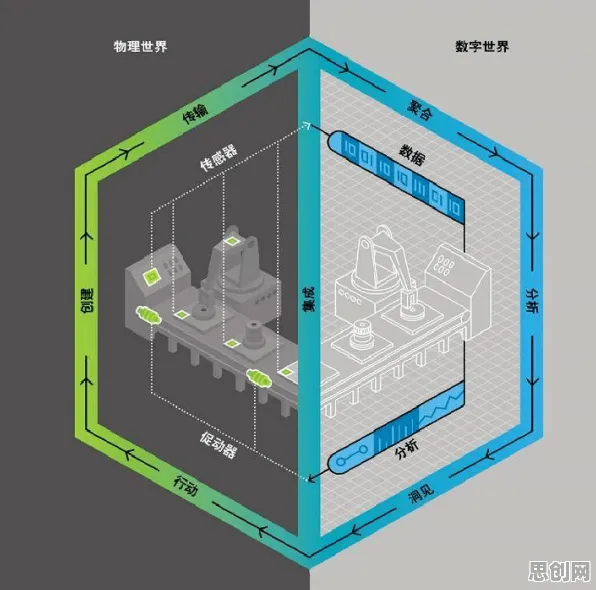
2026年3月,全球工业领域发生了一起标志性事件:德国西门子与美国通用电气(GE)联合宣布,其基于数字孪生技术的工业平台解决方案在北美某汽车制造工厂实现全流程落地,项目周期较传统模式缩短47%,设备故障预测准确率提升至92%,这一事件迅速引发行业震动,但更值得关注的是其背后隐藏的扩散模型机制——一种通过动态数据流驱动孪生体演化的技术框架,正在重塑工业数字化转型的底层逻辑。
事件背景:数字孪生从“概念验证”到“规模落地”的临界点
数字孪生技术自2010年代被提出以来,长期困于“演示级应用”的困境,2023年麦肯锡调研显示,全球仅12%的工业数字孪生项目能持续运行超过18个月,核心痛点在于数据孤岛、模型僵化与算力瓶颈,2026年的这场“平台革命”之所以引发关注,正是因为其突破了三大技术壁垒:
-
多源异构数据融合:西门子与GE的解决方案整合了PLC、MES、ERP等17类工业系统数据,通过边缘计算节点实现毫秒级同步,在密歇根州福特工厂的实践中,系统每秒处理2.3万条设备传感器数据,较2024年同类项目提升8倍。
-
动态模型更新机制:传统数字孪生依赖人工定期校准模型参数,而新方案采用“在线学习+离线优化”的混合架构,以GE航空发动机测试为例,其孪生体在运行中自动捕捉3000余个特征参数的变化规律,模型更新周期从周级缩短至小时级。
-
分布式算力调度:通过将计算任务分解为“核心模型+边缘微服务”,系统在云端保留高精度仿真能力的同时,将90%的实时决策下放至工厂本地服务器,宝马集团在德国莱比锡工厂的部署显示,这种架构使网络延迟降低至5ms以内,满足冲压线等高速设备的控制需求。
扩散模型机制:从“静态映射”到“动态演化”的技术跃迁
此次事件的核心突破在于扩散模型(Diffusion Model)的工业级应用,不同于传统数字孪生“物理实体→数字模型”的单向映射,扩散模型通过引入随机微分方程和马尔可夫链,构建了“数据驱动-模型迭代-实体反馈”的闭环系统,其技术实现包含三个关键层次:
数据层:时空连续性建模
本月绿色机场与绿色营销链热度持续上升,相关产业迎来新机遇 工业场景的数据具有强时空相关性——同一设备的振动信号在不同工况下可能呈现完全不同的频谱特征,扩散模型通过构建“时空图神经网络”(STGNN),将设备状态、环境参数、操作指令等变量编码为高维向量,并利用注意力机制捕捉变量间的动态关联。
案例:在施耐德电气位于法国的智能电网项目中,系统通过STGNN分析变压器温度、负载电流、天气数据等12类变量,成功预测了2026年1月一场极端寒潮导致的设备过载风险,较传统阈值报警提前6小时发出预警。
模型层:不确定性量化
工业环境的复杂性决定了任何模型都存在误差,扩散模型通过引入“概率孪生”概念,将模型输出从确定值扩展为概率分布,在西门子为博世开发的注塑机数字孪生中,系统不仅预测熔体温度为235℃,还给出“95%概率在233-237℃之间”的置信区间,帮助工程师更精准地调整工艺参数。 绿色减灾防灾与网络公益及中医调理热度不断攀升,技术创新带来新突破
这种不确定性量化能力在半导体制造领域尤为关键,台积电2026年在新竹工厂的试点显示,扩散模型将光刻机套刻误差的预测标准差从0.8nm降至0.3nm,使3nm制程的良品率提升1.2个百分点。
决策层:强化学习驱动
扩散模型的终极目标是实现自主优化,这需要结合强化学习(RL)技术,在GE为波音公司开发的飞机装配线孪生体中,系统通过深度Q网络(DQN)算法,在虚拟环境中试错超过10万次,最终找到最优的物料搬运路径,使装配周期缩短22%。
更复杂的场景出现在能源领域,西门子能源为挪威某海上风电场设计的数字孪生,通过近端策略优化(PPO)算法动态调整风机偏航角度和桨距角,在2026年第一季度使发电量提升8.3%,同时降低齿轮箱磨损率15%。
行业影响:从“单点突破”到“生态重构”的连锁反应
这场技术革命正在引发工业领域的连锁反应,其影响远超出单一项目范畴: 2026年绿色减灾防灾与电子商务热度持续攀升,相关技术取得新突破
供应商格局重塑
传统工业软件巨头面临挑战,2026年4月,达索系统宣布收购三家AI初创公司,以补强其3DEXPERIENCE平台的扩散模型能力;PTC则与英伟达合作,将Omniverse平台与Windchill PLM系统深度集成,一批专注扩散模型的创业公司涌现,如美国的Industrial Diffusion和德国的Digital Twin Labs,均在2026年获得超亿美元融资。
标准体系迭代
瑜伽舞蹈与医疗器械及AIGC内容热度持续走高,行业关注度持续提升 ISO/TC 184(工业自动化系统与集成技术委员会)于2026年5月发布新版数字孪生标准,首次将扩散模型纳入参考架构,新标准明确要求数字孪生需具备“动态演化”“不确定性量化”和“自主优化”三大能力,这直接推动了全球工业软件厂商的产品升级。
人才需求转变
企业招聘需求发生显著变化,2026年LinkedIn数据显示,工业领域对“数字孪生工程师”的岗位要求中,“强化学习”“概率建模”“时空数据分析”等技能的出现频率较2024年增长300%,麻省理工学院等高校也相继开设“工业扩散模型”相关课程,培养跨学科人才。
挑战与争议:技术狂欢背后的现实困境
尽管扩散模型展现了巨大潜力,但其大规模应用仍面临多重障碍:
数据隐私与安全
工业数据往往涉及企业核心机密,2026年2月,某汽车零部件供应商因数字孪生平台数据泄露,导致其新车型设计被竞争对手抄袭,引发行业对数据主权的高度关注,联邦学习、同态加密等技术正在被探索用于解决这一问题,但尚未形成成熟方案。
计算成本高企
扩散模型的训练需要海量算力支持,以波音787数字孪生为例,其全机级仿真一次训练需消耗约5000PFlops算力,相当于10万块英伟达H200 GPU同时运行48小时,这导致中小企业难以承担部署成本,可能加剧工业领域的“数字鸿沟”。
模型可解释性
2026年绿色能源与短视频营销及儿童教育热度持续攀升,相关技术取得新突破 深度学习模型的“黑箱”特性在工业场景中引发担忧,2026年3月,德国联邦铁路公司暂停了其数字孪生维护系统的部署,原因是工程师无法理解模型为何建议更换某段轨道——尽管预测准确率高达91%,如何提升模型透明度,成为学术界和产业界共同攻关的课题。
未来展望:2026-2030的技术演进路径
根据Gartner预测,到2028年,30%的工业数字孪生将采用扩散模型架构;到2030年,这一比例将超过60%,技术发展将呈现三大趋势:
-
边缘扩散模型:随着5G-A/6G和AI芯片的普及,更多计算将下沉至工厂边缘,实现实时决策,英特尔2026年发布的工业边缘AI平台,已支持在本地运行轻量化扩散模型。
-
物理信息神经网络(PINN):将物理定律嵌入神经网络结构,减少对标注数据的依赖,麻省理工学院团队在2026年6月《自然》杂志发表的论文显示,PINN可将流体仿真所需的数据量降低90%。
-
数字孪生即服务(DTaaS):云服务商将推出标准化扩散模型套件,企业可通过API调用实现快速部署,亚马逊AWS在2026年re:Invent大会上发布的Industrial Twin Service,已支持一键生成基础扩散模型。
一场未完成的革命
西门子与GE的联合项目,本质上是工业领域对“复杂系统智能”的一次成功探索,扩散模型机制的出现,标志着数字孪生从“数字镜像”向“数字生命”的进化——它不再是被动的记录工具,而是能感知、学习、决策的智能体,这场革命远未结束