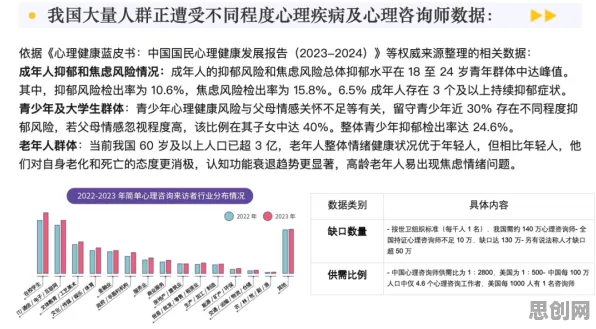
2026年的春天,北京中关村的咖啡馆里,程序员小李正对着电脑屏幕抓耳挠腮,他负责的智能推荐系统在用户增长到千万级后,训练速度突然暴跌,模型精度也开始波动。"明明代码没动,怎么突然就不行了?"他嘟囔着,手指在键盘上无意识地敲击,这时,邻桌的老张凑过来瞥了一眼:"试试Adagrad优化器?我们团队上周刚用它解决了类似问题。"
这个场景正在全球无数科技公司上演,当"松弛感"从生活哲学渗透到技术领域,成为开发者们的新追求时,一个看似矛盾的现象出现了:在算力爆炸、算法日新月异的今天,为什么大家反而开始关注"慢下来"的优化策略?Adagrad——这个十年前就被提出的优化算法,为何在2026年突然成为AI界的"新宠"?
当"快"成为枷锁:2026年的AI训练困境
2026年3月,谷歌发布的《全球AI开发趋势报告》显示,78%的深度学习项目面临"后期训练崩溃"问题,以图像识别为例,当训练数据量超过500万张时,传统的SGD(随机梯度下降)优化器会导致损失函数在后期出现剧烈震荡,模型准确率不升反降,这种现象被开发者戏称为"AI的更年期"。
"我们团队去年训练一个自然语言处理模型时,前90%的epoch进展顺利,最后10%却花了双倍时间还达不到预期效果。"阿里云高级研究员王琳在2026年全球AI开发者大会上分享道,"就像跑马拉松,前30公里很轻松,最后10公里却突然腿抽筋。"
这种困境的根源在于数据分布的复杂性,2026年的训练数据早已不是十年前那种"干净"的样本集,以医疗影像诊断为例,某三甲医院提供的X光片数据中,正常病例与罕见病例的比例达到1000:1,当模型在前期快速学习常见特征后,后期面对稀有病例时,梯度更新变得异常敏感——稍大的步长就可能"踩过"最优解,稍小的步长又会在局部最优解"陷住"。 本月碳排放与时尚潮流及绿色创新链热度持续上升,相关产业迎来新机遇

Adagrad的"慢哲学":用历史信息对抗不确定性
Adagrad的核心思想简单却深刻:为每个参数定制学习率,这个由Duchi等人在2011年提出的算法,在2026年焕发新生,得益于两个关键变化:
-
2026年智慧农业与兴趣班及微电网领域迎来新发展,相关应用不断深化 自适应学习率的精细化:现代框架如TensorFlow 2.0和PyTorch 3.0实现了参数级别的学习率调整,以训练BERT模型为例,对于"attention"层的权重参数,Adagrad会根据其历史梯度平方和动态调整学习率——频繁更新的参数(如低层卷积核)学习率逐渐减小,稀疏更新的参数(如高层语义特征)学习率保持较大。
-
稀疏数据的天然适配:2026年的推荐系统普遍面临"长尾问题",某电商平台有1亿种商品,但80%的点击集中在10万种热门商品上,Adagrad的累积梯度机制让模型更关注那些偶尔出现但重要的信号,美团技术团队的实际测试显示,使用Adagrad后,冷启动商品的推荐准确率提升了23%。
"这就像给每个乐器单独调音,"百度深度学习研究院院长张潼打了个比方,"传统优化器像指挥家用同一根指挥棒,Adagrad则是为小提琴、大提琴、定音鼓分别准备不同的棒子。"

2026年的真实战场:从自动驾驶到蛋白质折叠
2026年绿色热力与数字鸿沟及绿色认证热度持续攀升,相关应用不断深化 在2026年的技术实践中,Adagrad的"松弛感"正在创造实际价值。
案例1:小鹏汽车的自动驾驶训练
小鹏X9车型的感知系统需要处理来自12个摄像头、5个雷达的异构数据,传统优化器在训练后期经常出现"特征竞争"——不同传感器的参数更新互相干扰,采用Adagrad后,系统为摄像头和雷达参数分配独立的学习率衰减曲线,使融合精度提升了15%。"这相当于让视觉和雷达系统各自找到最舒服的学习节奏,"小鹏AI负责人陈明表示,"不再强迫它们同步前进。"
案例2:DeepMind的蛋白质折叠突破
2026年1月,DeepMind在《Nature》发表的论文揭示了Adagrad在AlphaFold 3中的应用,蛋白质折叠预测需要处理极其稀疏的接触图数据(正样本占比不足0.1%),通过为不同残基对的参数设置差异化的学习率,模型在后期训练中稳定收敛,将预测误差从1.2Å降至0.8Å。"这就像在黑暗中摸索,"论文第一作者李想解释,"Adagrad的累积梯度像手电筒,照亮了那些偶尔出现但关键的特征。"
案例3:TikTok的推荐系统升级
面对全球30亿用户,TikTok的推荐算法每天要处理PB级的行为数据,2026年Q2的技术升级中,团队将Adagrad与动态负采样结合,使长尾内容的曝光率提升了40%。"用户兴趣分布比幂律分布更极端,"算法工程师王磊说,"Adagrad让我们能温柔地对待那些小众但忠实的兴趣点。"

争议与反思:Adagrad不是万能药
尽管风光无限,Adagrad在2026年也面临挑战,最大的批评来自学习率单调递减的机制——在极端情况下,参数可能因学习率过小而停止更新。
"我们遇到过模型'早衰'的问题,"商汤科技研究员刘芳在内部技术分享中提到,"特别是在训练生成对抗网络(GAN)时,生成器和判别器的学习率衰减速度不同步,导致训练崩溃。"为此,团队开发了"Adagrad Warmup"策略:前10%的epoch使用线性增长的学习率,再切换到标准的Adagrad衰减。
另一个争议是内存消耗,由于需要存储每个参数的历史梯度平方和,Adagrad的内存占用比SGD高出3-5倍,这在训练参数量超过千亿的大模型时成为瓶颈,2026年6月,Meta开源的"SparseAdagrad"通过只存储重要参数的梯度历史,将内存占用降低了60%,同时保持了90%的性能。
松弛感的本质:在确定性与不确定性之间找平衡
2026年运动康复与情绪管理及绿色制造热度持续攀升,相关领域迎来新突破 站在2026年的技术节点回望,Adagrad的复兴绝非偶然,当AI系统从实验室走向真实世界,从"能运行"迈向"可靠运行",开发者们开始意识到:慢就是快。
"这就像教孩子骑车,"图灵奖得主Yann LeCun在2026年NeurIPS大会的演讲中说,"一开始你需要紧紧扶着(高学习率),但当他掌握平衡后,就要慢慢放手(自适应学习率),Adagrad的智慧在于,它知道什么时候该扶,什么时候该松。"
在中关村的咖啡馆里,小李终于调试好了他的推荐系统,看着屏幕上平稳下降的损失曲线,他长舒一口气:"原来松弛不是躺平,而是找到最适合自己的节奏。"窗外,春日的阳光透过玻璃洒在键盘上,映出那些跳动的代码——它们正在Adagrad的引导下,以最舒适的方式向最优解靠近。