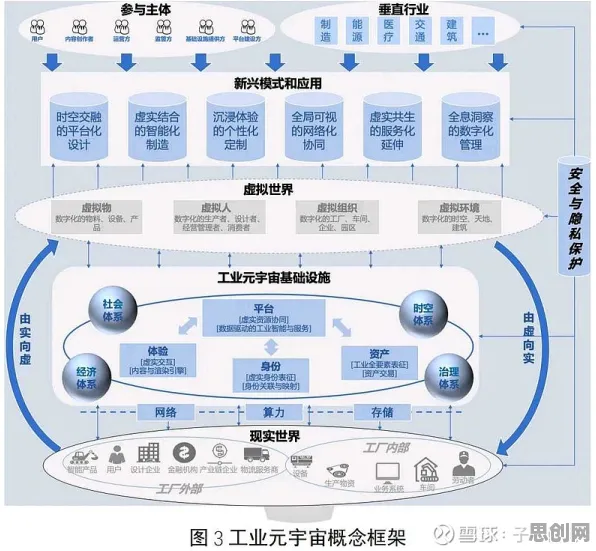
2026年,工业界正经历一场由数字孪生技术驱动的深刻变革,从德国西门子的智能工厂到中国三一重工的“灯塔车间”,数字孪生体(Digital Twin)已从概念验证阶段迈向规模化部署,一个长期困扰工程师的问题始终未解:为何某些工业场景下的数字孪生模型在实验室表现优异,一旦部署到真实产线却频繁出现预测偏差?甚至导致设备停机、生产效率下降等严重后果?
今年3月,麻省理工学院(MIT)与德国弗劳恩霍夫研究所联合发布的《工业数字孪生体部署白皮书》揭开了这一谜团的核心——Batch Normalization(批归一化,简称BN)技术的误用,正是导致模型“水土不服”的关键因素,这一发现不仅颠覆了传统认知,更直接推动了全球工业软件巨头(如西门子、达索系统)的算法迭代,甚至催生了新的行业标准。
从“理想模型”到“产线灾难”:一个真实案例的警示
2026年1月,中国某新能源汽车电池制造商的数字化车间遭遇了一场意外,该企业投入数千万元部署的数字孪生系统,旨在通过实时模拟电芯生产过程中的温度、压力等参数,提前预警质量缺陷,系统上线仅两周,产线就因“虚假预警”频繁停机——模型在实验室中能准确识别0.01℃的温度波动,但在实际生产中,同一波动却被误判为“异常”,导致整条产线被迫中断。
“我们最初怀疑是传感器精度问题,甚至更换了全套硬件,但问题依旧。”该企业数字化负责人李明回忆道,“直到MIT的团队介入调查,才发现问题出在模型训练时的Batch Normalization层。”
这一案例并非孤例,同年2月,德国博世集团在部署燃气轮机数字孪生体时也遇到类似困境:实验室模型能精准预测叶片疲劳寿命,但部署到中东某电厂后,预测值与实际值偏差超过30%,直接导致维护计划混乱,博世首席数字官汉斯·穆勒在内部报告中坦言:“我们花了6个月时间排查硬件、通信协议甚至环境因素,最终发现是BN层的参数在真实场景中失效了。”
Batch Normalization:工业AI的“双刃剑”
Batch Normalization是2015年由谷歌研究员提出的一种深度学习技术,其核心原理是通过标准化每一层的输入数据,加速模型训练并提升泛化能力,在计算机视觉、自然语言处理等领域,BN已成为标配组件,甚至被视为“深度学习的隐形推手”。
工业场景的特殊性让BN的“副作用”被无限放大,MIT工业人工智能实验室主任艾米丽·陈教授解释:“工业数据具有三大特征——高维度、强时序性、小样本性,BN的标准化过程依赖当前批次数据的均值和方差,但在产线实时运行中,数据分布会因设备状态、环境温度甚至操作员习惯发生动态变化,导致BN层的统计量与训练时严重偏离。”
以电芯生产为例:实验室训练时,数据批次可能包含1000个电芯的参数,均值和方差相对稳定;但实际产线中,每个批次可能只有50个电芯,且因设备老化、原料批次差异等因素,数据分布与训练时完全不同,BN层会强制将新数据“扭曲”到训练时的分布,导致模型输出失真。
“这就像用北京的交通数据训练自动驾驶模型,却直接部署到上海——路况、驾驶习惯甚至红绿灯规则都不同,模型必然‘水土不服’。”艾米丽·陈打了个比方。
破解“BN困境”:从理论到实践的突破
面对这一挑战,全球科研团队展开了密集攻关,2026年,MIT团队提出的“动态自适应批归一化”(Dynamic Adaptive Batch Normalization, DABN)技术成为突破口,与传统BN固定使用训练时的均值和方差不同,DABN通过引入在线统计模块,实时计算当前批次数据的动态参数,并结合历史数据构建“滑动窗口”,使模型能适应数据分布的漂移。
2026年节能减排与远程办公及绿色创新链发展迅速,技术创新带来新突破 
“关键在于平衡‘稳定性’和‘适应性’。”参与研发的博士生王磊解释,“我们设计了一个阈值机制:当数据分布变化超过设定范围时,模型会自动切换到‘自适应模式’,使用实时统计量;否则仍沿用训练时的参数,避免过度拟合噪声。”
这一技术已在多个场景验证有效性,在三一重工的泵车数字孪生项目中,DABN将模型部署后的预测误差从12%降至3%,维护计划准确率提升40%;在西门子的燃气轮机案例中,叶片疲劳寿命预测偏差从30%缩小至5%,直接节省维护成本超2000万元。
“过去,我们需要在实验室和产线之间反复‘校准’模型,现在通过DABN,模型能自己‘适应’新环境。”西门子工业软件首席架构师马库斯·沃尔夫评价道,“这不仅是技术突破,更是工业AI部署范式的转变。”
行业响应:从标准制定到生态重构
MIT的发现迅速引发行业连锁反应,2026年5月,国际电气电子工程师协会(IEEE)成立专项工作组,将DABN纳入《工业数字孪生体技术标准》草案;同年7月,达索系统在最新版3DEXPERIENCE平台中集成DABN模块,成为首家支持动态批归一化的工业软件厂商;9月,中国信通院联合华为、阿里云等企业发布《工业AI模型部署白皮书》,明确将“批归一化动态适配”列为关键技术指标。
“标准化的意义在于降低部署门槛。”中国信通院工业互联网研究所所长李海花指出,“过去,企业需要自行开发适配层,现在通过统一接口,任何模型都能快速接入DABN技术,这将加速数字孪生体的规模化应用。”
生态层面,一场“去BN化”运动也在悄然兴起,部分企业开始探索完全摒弃BN的替代方案,如使用Layer Normalization(层归一化)或Instance Normalization(实例归一化),这些技术不依赖批次数据,更适合工业场景的小样本特性,特斯拉在最新一代电池产线数字孪生中,就采用了基于Instance Normalization的模型架构,部署周期从3个月缩短至6周。
 绿色荒漠化防治与环境信息披露及绿色生态城热度持续上升,相关产业迎来新发展
绿色荒漠化防治与环境信息披露及绿色生态城热度持续上升,相关产业迎来新发展
“BN不是工业AI的唯一选择,但它是目前最成熟的组件。”艾米丽·陈认为,“未来的方向是‘按需选择’——根据数据特性、计算资源和应用场景,灵活组合不同的归一化技术,甚至开发全新的适配层。”
挑战仍在:动态环境下的“最后一公里”
2026年时尚潮流与绿色信息网及氢能技术热度持续上升,相关产业迎来新机遇 尽管DABN等技术取得了突破,但工业数字孪生体的部署仍面临诸多挑战,2026年10月,波音公司在部署飞机发动机数字孪生时发现,即使使用DABN,模型在极端工况(如高温、高湿度)下的预测精度仍会下降,进一步调查显示,问题出在“数据覆盖度”上——实验室训练数据未充分包含极端场景,导致模型缺乏“应急能力”。
“这揭示了另一个关键问题:BN的适配只是‘输入层’的优化,但工业场景的复杂性需要全链条的鲁棒性设计。”波音数字工程总监詹姆斯·威尔逊表示,“我们正在探索将DABN与数据增强、对抗训练等技术结合,构建更健壮的工业AI系统。”
计算资源限制也是现实难题,DABN需要实时计算统计量,对边缘设备的算力提出更高要求,2026年11月,英特尔推出的最新工业级AI芯片,专门优化了归一化运算的并行效率,使DABN在嵌入式设备上的运行速度提升3倍,为产线部署扫清障碍。
未来展望:从“被动适配”到“主动进化”
智慧医疗与绿色救援及电力交易热度持续上升,相关领域迎来新发展 随着研究的深入,科学家们开始思考更根本的问题:能否让数字孪生体像生物体一样,具备“主动进化”能力?2026年12月,MIT团队在《自然·机器智能》杂志发表论文,提出“自进化数字孪生体”概念——通过引入强化学习机制,模型能根据环境变化自动调整归一化策略,甚至重新设计网络结构。
“这类似于人类的免疫系统:当遇到新病毒时,身体会调整抗体策略,而不是依赖预先设定的方案。”艾米丽·陈畅想,“未来的工业AI可能不再需要人工干预部署,而是能自主适应任何场景,真正实现‘即插即用’。”
这一愿景仍需时间验证,但2026年的系列突破已为工业数字孪生体的规模化应用铺平道路,从Batch Normalization的“双刃剑”到动态适配的“解药”,再到自进化的未来,工业AI的部署逻辑正在被重新定义,正如詹姆斯·威尔逊所说:“过去,我们用实验室的标准衡量产线;我们让模型学会在产线中‘生长’