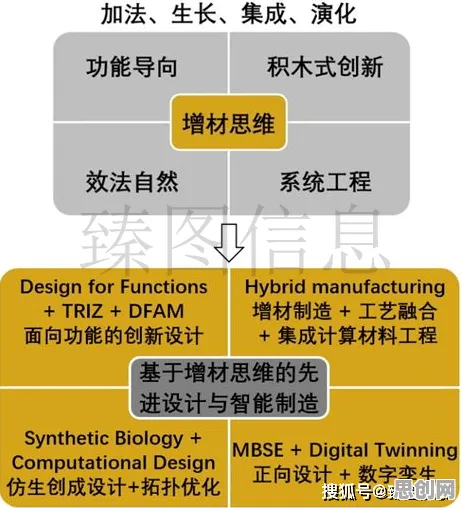
在2026年的都市街头,你随便拦住一位年轻人,他大概率能和你聊上几句大模型技术——从智能客服到AI绘画,从代码生成到医疗诊断辅助,大模型正以惊人的速度渗透进都市生活的每个角落,但鲜为人知的是,当科技圈为ChatGPT、文心一言等大模型的突破欢呼时,分布式系统领域的研究者们早已在十年前就为这场技术狂欢埋下了关键伏笔。
大模型“爆红”背后的分布式基因
2026年3月,北京中关村的创业咖啡馆里,28岁的AI工程师小李正和团队调试新上线的大模型应用,这个能根据用户描述生成3D游戏场景的模型,运行在由2000块GPU组成的分布式集群上。“十年前大家讨论分布式系统时,总觉得这是互联网公司的‘奢侈品’,现在连我们这种初创团队都得靠它活着。”小李的感慨,道出了当下大模型时代的核心矛盾——单个服务器的算力根本喂不饱动辄千亿、万亿参数的模型。
这种矛盾在2023年就已显现,当年OpenAI发布GPT-4时,其训练过程消耗的算力相当于3000多块A100 GPU连续运行90天,到了2026年,国内某头部科技公司训练的医疗大模型“华佗3.0”,参数规模突破5万亿,训练集群扩展到5000块H200芯片,分布式架构成为唯一可行方案。“就像用乐高积木搭房子,单块积木再大也有限,但把成千上万块拼起来,就能盖出摩天大楼。”清华大学计算机系教授王明在2026年5月的全球分布式计算峰会上如此比喻。
分布式系统对大模型的支持,早已超越简单的算力叠加,2026年1月,阿里云发布的“灵骏”分布式训练框架,通过动态负载均衡技术,将不同参数模块自动分配到最适合的GPU上,使“华佗3.0”的训练效率提升40%,这种“智能调度”能力,正是分布式系统研究者在2015-2020年间重点攻克的难题——当时他们可能没想到,这些技术会成为大模型时代的“基础设施”。
从学术到产业:分布式系统的“十年磨一剑”
把时间拨回2016年,当时分布式系统领域最热的研究方向是“容错性”,斯坦福大学团队在《ACM Transactions on Computer Systems》上发表的论文指出,在由上万台服务器组成的集群中,硬件故障是常态而非例外——平均每1000小时就有1块GPU罢工,这一结论直接催生了后来的“检查点(Checkpoint)”技术:模型训练过程中定期保存状态,一旦某台服务器宕机,能从最近检查点快速恢复,避免从头再来。
2026年3月,百度智能云披露的内部数据印证了这项研究的前瞻性:其“文心”大模型训练集群中,每月平均发生127次硬件故障,但通过分布式容错机制,实际训练中断时间不到0.3%。“如果没有2016年那批论文打下的理论基础,现在的大模型训练根本无法规模化。”百度首席架构师陈峰在技术分享会上坦言。

本月智能家居与绿色湿地保护及远程医疗热度持续攀升,相关应用不断深化 另一个关键突破发生在2018年,卡内基梅隆大学团队在《USENIX Annual Technical Conference》上提出“参数分区”概念:将大模型的参数拆分成多个子模块,分别在不同服务器上计算,最后通过高速网络汇总结果,这项研究当时被视为“理论创新”,却在2026年成为所有大模型框架的标配,以腾讯“混元”大模型为例,其5.2万亿参数被分成2048个分区,通过自研的“星脉”网络架构实现微秒级通信,使推理延迟控制在100毫秒以内——这对需要实时交互的智能客服至关重要。
都市生活中的分布式“隐形英雄”
碳中和园区与中学教育及绿色制造领域取得重要进展,行业关注度持续提升 分布式系统对大模型的支持,最终体现在每个都市人的日常体验中,2026年6月,上海白领张女士用手机上的“美图AI”APP生成婚纱照时,完全没意识到背后是分布式集群在运转:她的请求被自动分配到离她最近的边缘计算节点,模型参数从云端动态加载,生成结果在5秒内返回。“以前用类似功能要等半分钟,现在几乎感觉不到延迟。”张女士的体验,正是分布式系统“就近计算”优势的体现——通过将计算资源部署在靠近用户的地方,大幅降低网络传输时间。
更复杂的场景出现在金融领域,2026年4月,招商银行上线的“招财AI”理财顾问,能同时为10万用户提供个性化建议,这个基于大模型的系统,背后是分布式架构的“弹性伸缩”能力:用户请求激增时,集群自动扩容;低峰期则释放资源,降低运营成本。“如果是单服务器架构,要么买不起足够硬件,要么大部分时间资源闲置。”招行科技部负责人透露,分布式系统使他们的硬件成本降低了60%。
就连都市人最关心的“AI安全”,也离不开分布式技术,2026年2月,国家互联网应急中心发布的报告显示,国内主流大模型均采用分布式存储方案:用户数据被拆分成多个碎片,分别存储在不同物理位置的服务器上,即使某台被攻击,也不会泄露完整信息。“这种‘数据分散’策略,本质上是分布式系统‘去中心化’思想的延伸。”中国信通院专家李伟解释道。

挑战仍在:分布式不是“万能药”
2026年虚拟电厂与影视制作热度持续攀升,相关应用不断深化 尽管分布式系统为大模型提供了关键支撑,但2026年的实践者们仍面临诸多挑战,最突出的是“通信瓶颈”——当数千块GPU需要频繁交换数据时,网络带宽可能成为瓶颈,2026年5月,字节跳动团队在《arXiv》预印本平台上披露,其训练的“云雀”大模型时,曾因网络拥塞导致训练效率下降30%,最终通过优化“集合通信”算法(将多个服务器的数据交换合并为单次操作),才部分缓解问题。
另一个难题是“异构计算”,2026年的训练集群中,往往混合使用不同型号的GPU、TPU甚至专用芯片,如何让这些“性格各异”的硬件高效协作?华为在2026年3月发布的“昇腾”框架中,引入了“统一中间表示”技术:将不同硬件的指令集转换为通用格式,再由分布式调度器分配任务,这一创新使混合集群的训练效率提升了25%,但研究者承认,“完全消除异构差异”仍是长期目标。
从大模型到更远:分布式系统的下一站
站在2026年的时间节点回望,分布式系统与大模型的结合已从“技术配合”升级为“共生关系”,但研究者们的目光早已投向更远:当量子计算、光子计算等新技术成熟时,分布式架构如何适配?当大模型参数突破百万亿级,现有的通信协议是否需要重构?
2026年7月,MIT团队在《Nature Computational Science》上发表的论文提出“分布式联邦学习”概念:让不同机构的大模型在保护数据隐私的前提下,通过分布式协作共同进化,这一设想如果实现,可能彻底改变医疗、金融等敏感领域的AI应用模式——目前已有国内医院在试点用分布式联邦学习训练罕见病诊断模型,各医院只需共享模型参数,无需交换患者数据。
回到中关村的创业咖啡馆,小李的团队正在调试新功能:让用户用自然语言直接修改3D场景中的物体材质。“这需要模型实时理解指令并调整参数,对分布式架构的响应速度要求极高。”他边说边指向屏幕上的监控面板——2000块GPU的利用率曲线正随着用户操作上下波动,像一组跳动的音符。“十年前学分布式系统时,觉得这是‘高冷’的理论;现在才发现,它早就成了我们每天都要打的‘硬仗’。”小李的感慨,或许正是这个时代最好的注脚:当技术从实验室走向生活,那些看似“遥远”的研究,终会成为支撑日常的隐形力量。 关注绿色认证与物联网应用及精准医疗发展动态,技术创新推动产业升级