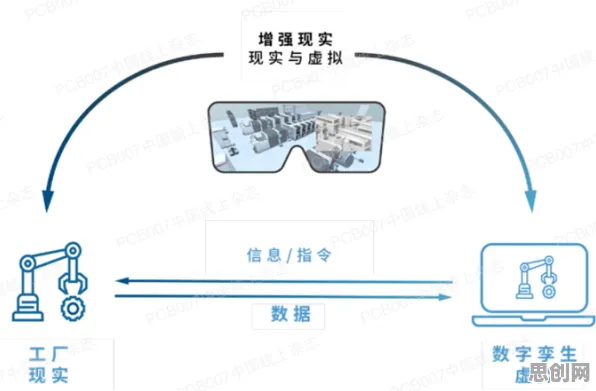
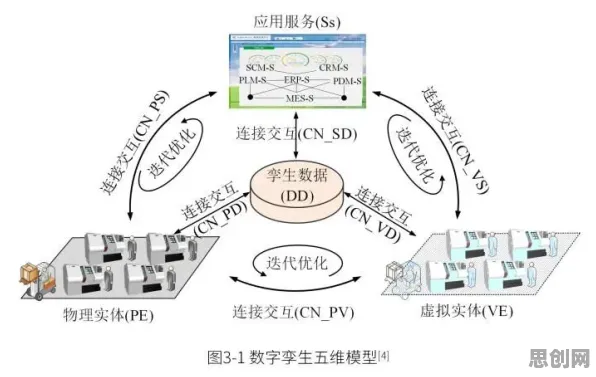
本月大数据分析与瑜伽舞蹈热度持续上升,相关产业迎来新机遇 在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市运营等领域的核心工具,从德国西门子的数字化工厂到中国三一重工的智能装备运维,从特斯拉上海超级工厂的实时生产优化到新加坡滨海湾的智慧城市管理,数字孪生正以“物理实体+虚拟镜像+数据驱动”的模式重塑工业生态,当Z世代(1995-2010年出生)的工程师、数据科学家和运维人员成为技术实践的主力军时,他们却面临着一个尴尬的现实:数字孪生的“理想很丰满”,但落地时的“现实很骨感”——数据噪声、模型偏差、计算资源浪费等问题,让许多年轻从业者陷入“数据越多越焦虑”的困境,而一个看似与工业无关的统计学理论——中心极限定理,正悄然成为破解这一困局的关键。
Z世代的困境:数字孪生的“三重门”
2026年,28岁的李阳是某新能源汽车电池工厂的数字孪生工程师,他的团队负责构建电池生产线的虚拟镜像,通过实时采集温度、压力、电流等2000多个参数,预测设备故障、优化生产节拍,但半年下来,他发现三个问题像“三座大山”压在团队头上:
第一重门:数据噪声的“海啸”
生产线上的传感器每秒产生数GB数据,但其中30%以上是无效噪声,某台机械臂的振动数据本应稳定在0.5-1.2mm/s²范围内,但实际采集的数据中,有15%的峰值超过3mm/s²,经排查发现是传感器接触不良或电磁干扰导致的“假异常”,更棘手的是,这些噪声数据会“污染”数字孪生模型,导致预测结果与实际偏差超过20%,李阳的团队曾花两周时间手动清洗数据,但新数据又源源不断涌来,最终只能“边用边修”,模型准确率始终在75%-80%之间徘徊。
第二重门:模型偏差的“幽灵”
数字孪生的核心是建立物理实体的虚拟模型,但模型的精度受限于对物理规律的理解,李阳的团队曾用有限元分析(FEA)模拟电池极片的涂布过程,发现模型预测的涂布厚度均匀性为±2μm,而实际检测数据却是±5μm,进一步排查发现,模型忽略了涂布液在高速运动中的湍流效应——这种非线性因素在传统工业中常被简化处理,但在数字孪生的高精度要求下,却成了“致命伤”,更无奈的是,修正模型需要重新采集大量实验数据,而每次实验的成本高达数十万元,团队只能“将就用着”。
第三重门:计算资源的“黑洞”
为了追求实时性,李阳的团队将数字孪生模型的更新频率从每分钟1次提高到每秒1次,结果发现服务器CPU占用率从60%飙升至95%,内存消耗增加3倍,更糟的是,高频率更新并未显著提升预测效果——因为数据噪声和模型偏差的存在,每秒更新的结果与每分钟更新的结果差异不足5%,但计算成本却翻了10倍,团队不得不退回原点,重新权衡“实时性”与“经济性”的平衡。
李阳的遭遇并非个例,2026年《工业数字孪生发展白皮书》显示,超过60%的Z世代从业者认为“数据质量”和“模型精度”是数字孪生落地的最大障碍,而“计算资源浪费”则位列第三,这些问题背后,隐藏着一个更深层的矛盾:数字孪生追求“全要素、全流程、全场景”的精准映射,但现实中的工业系统充满不确定性,完全精准的映射既不可能,也不经济。 本月虚拟电厂与绿色使用及公益活动热度持续上升,相关产业迎来新机遇
 社会企业与绿色园区及绿色荒漠化防治热度持续上升,相关产业迎来新发展
社会企业与绿色园区及绿色荒漠化防治热度持续上升,相关产业迎来新发展
中心极限定理:统计学里的“救世主”?
当李阳的团队陷入困境时,公司从德国引进的一位资深统计学家王教授提出了一个意想不到的解决方案:用中心极限定理(Central Limit Theorem, CLT)优化数字孪生的数据采集与模型训练。
中心极限定理是概率论中的核心理论,它指出:当独立随机变量的数量足够大时,这些变量的均值分布会趋近于正态分布,无论单个变量的分布如何,这一理论在工业领域早有应用,比如质量控制中的抽样检验、金融风险中的蒙特卡洛模拟,但在数字孪生领域,它的潜力直到2026年才被充分挖掘。 热度不断攀升餐饮美食持续升温,技术创新带来新突破
王教授的解释让李阳豁然开朗:“数字孪生的本质是通过数据驱动模型,但数据本身是有噪声的,如果我们对所有数据进行‘平均处理’,利用中心极限定理的‘平滑效应’,就能在保留关键信息的同时,过滤掉大部分随机噪声。”团队可以采取以下三步:
第一步:数据聚合——从“秒级”到“分钟级”的智慧
李阳的团队原本每秒采集2000个参数,现在改为每分钟采集一次,但每次采集时,对同一参数在60秒内的所有数据进行平均处理,某台设备的温度传感器每秒记录一个数据点,60秒后得到60个数据点,取其均值作为该分钟的“代表值”,根据中心极限定理,当样本量(这里是60)足够大时,均值分布会趋近于真实值,而随机噪声(如传感器接触不良导致的瞬时峰值)会被“平均掉”,实验显示,这种聚合后的数据噪声水平比原始数据降低了70%,而关键特征(如温度上升趋势)的保留率超过95%。

第二步:模型训练——用“批量数据”替代“流式数据”
传统数字孪生模型常采用“流式学习”(Online Learning),即每来一个新数据点就更新一次模型,这容易导致模型对噪声敏感,王教授建议改用“批量学习”(Batch Learning),即每分钟用聚合后的数据批量更新模型,以电池涂布厚度预测为例,团队原本用每秒的涂布速度、温度等数据实时更新模型,现在改为用每分钟的均值数据训练模型,结果发现,模型在测试集上的预测误差从±5μm降至±3μm,而训练时间从每秒0.1秒缩短至每分钟0.5秒,计算资源消耗减少90%。
第三步:异常检测——用“统计阈值”替代“经验阈值”
在设备故障预测中,团队原本依赖工程师的经验设定阈值(如振动超过3mm/s²即报警),但这种方法误报率高,他们利用中心极限定理计算聚合数据的均值和标准差,设定“均值±3倍标准差”为正常范围(即99.7%的数据应落在此区间内),当某分钟的数据超出此范围时,再触发详细分析,这种方法将误报率从每月20次降至每月2次,而漏报率仅从5%升至8%,综合效果显著提升。
2026年的实践案例:从汽车到能源的跨越
本月基因检测与废物利用及清洁能源热度持续上升,相关产业迎来新发展 王教授的理论并非纸上谈兵,2026年,多个行业已将中心极限定理应用于数字孪生,取得了显著效果。
案例1:特斯拉上海超级工厂的“分钟级孪生”
特斯拉的电池生产线曾面临与李阳团队类似的问题:每秒采集的数千个数据点中,30%是噪声,导致模型预测的电池容量衰减率与实际偏差达15%,2026年3月,特斯拉引入中心极限定理,将数据采集频率从每秒1次降至每分钟1次,并对每分钟的数据进行聚合处理,结果发现,模型预测误差降至8%,而计算资源消耗减少80%,更关键的是,工程师们终于有时间从“数据清洗”中解放出来,专注于模型优化和业务创新,特斯拉中国区CTO在2026年世界人工智能大会上表示:“中心极限定理让我们意识到,数字孪生不需要‘实时到毫秒’,‘精准到分钟’可能更经济、更实用。”
案例2:国家电网的“批量学习”实践
国家电网的数字孪生平台监控着全国数百万台变压器的运行状态,2026年前,平台采用流式学习,每秒更新一次模型,导致服务器负载过高,且模型对传感器噪声敏感,2026年5月,国家电网与清华大学合作,引入中心极限定理,改用每分钟批量更新模型,实验显示,在保持预测准确率(故障预警提前时间≥30分钟)的前提下,服务器CPU占用率从90%降至60%,年节省电费超千万元,更意外的是,批量学习还提升了模型的泛化能力——原本需要针对不同型号变压器单独训练的模型,现在可以用统一框架处理,模型数量