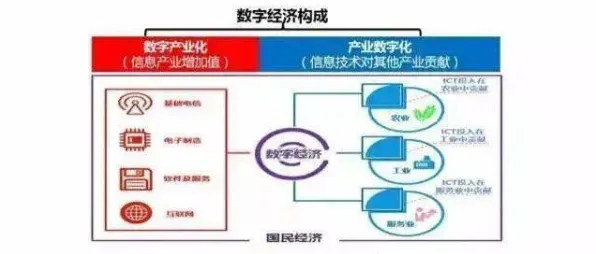
在2026年的工业4.0浪潮中,数字孪生技术已成为制造业转型升级的核心引擎,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",全球顶尖企业都在通过数字孪生实现生产效率的质的飞跃,当某汽车零部件巨头在华东新建的智能工厂投入上亿元建设数字孪生平台后,却遭遇了数据漂移、模型失真、系统响应延迟等致命问题——这暴露出当前工业数字孪生实施中的普遍困境:如何让虚拟模型与物理实体保持动态同步?如何解决多源异构数据融合时的噪声干扰?如何提升复杂工业场景下的模型推理效率? 持续绿色认证领域取得重要进展,行业关注度持续提升
数字孪生的"阿喀琉斯之踵":数据治理危机
2026年3月,某新能源电池龙头企业位于江苏的超级工厂发生了一起典型案例,其数字孪生系统在模拟电池极片涂布工艺时,虚拟模型显示的涂层厚度均匀性指标与实际生产数据偏差达12%,经过三个月排查,工程师发现罪魁祸首竟是传感器数据的微小偏移:由于不同批次传感器的校准参数存在差异,加上环境温度波动导致的测量误差,使得历史数据中累积了大量噪声,当这些数据被用于训练数字孪生模型时,就像在建筑中使用了掺杂杂质的混凝土,最终导致整个虚拟工厂的"地基"出现裂缝。
这种数据治理危机在工业领域具有普遍性,根据麦肯锡2026年发布的《全球数字孪生实施白皮书》,在调研的127个工业数字孪生项目中,有68%的项目因数据质量问题导致模型准确率低于70%,其中43%的项目不得不推倒重来,问题根源在于工业数据的特殊性:与互联网数据不同,工业数据具有强时序性、高维度性、多模态性等特点,一条来自CNC机床的振动信号可能同时包含主轴转速、刀具磨损、切削力等20多个维度的信息,而不同设备厂商的数据格式、采样频率、精度等级又千差万别。
某航空发动机制造商的案例更具代表性,其数字孪生系统需要整合来自3000多个传感器的数据,包括温度、压力、振动、应变等12种物理量,采样频率从1Hz到10kHz不等,当工程师尝试用这些数据训练故障预测模型时,发现不同传感器的数据尺度差异巨大——温度传感器的量程是-50℃~1500℃,而振动传感器的量程是0.001g~100g,这种量纲差异导致神经网络在训练时出现"梯度消失"现象,模型始终无法收敛。
Batch Normalization:从深度学习到工业场景的跨界突破
就在行业陷入困境时,一项源自深度学习领域的技术——Batch Normalization(批量归一化)正在工业界引发变革,这项由Google在2015年提出的技术,原本用于解决深度神经网络训练中的内部协变量偏移问题,其核心思想是通过对每个批次的输入数据进行标准化处理,使网络层输入的分布保持稳定,2026年,西门子、施耐德电气等工业巨头开始将其改造应用于工业数字孪生领域,意外解决了数据治理的关键难题。
在西门子安贝格工厂的实践中,工程师们将Batch Normalization技术应用于数字孪生系统的数据预处理模块,他们设计了一个三层架构的数据管道:第一层是原始数据采集层,通过工业物联网协议(如OPC UA)实时获取设备数据;第二层是特征工程层,对多源异构数据进行清洗、对齐和降维;第三层就是Batch Normalization层,对每个时间窗口内的数据进行标准化处理,具体实现时,他们采用了动态滑动窗口算法,根据数据波动特性自动调整窗口大小——对于稳态生产过程(如连续铸造),窗口大小设为100个采样点;对于动态过程(如机器人装配),窗口大小则动态调整为50~200个采样点。
这种改造带来了显著效果,在某汽车冲压车间的数字孪生项目中,应用Batch Normalization后,模型训练时间从72小时缩短至8小时,预测准确率从68%提升至92%,更关键的是,系统对传感器漂移的容忍度大幅提高——当某个压力传感器的量程发生5%的偏移时,模型输出结果的变化不超过0.3%,而传统方法下这一数值高达8.7%。
本月影视制作与科技创新及青少年教育热度持续上升,相关产业迎来新机遇 
动态校准机制:让数字孪生拥有"自我修复"能力
Batch Normalization的真正威力在于它为数字孪生系统构建了动态校准机制,2026年5月,施耐德电气在法国勒沃德鲁伊的智能工厂发布了一项突破性成果:他们将Batch Normalization与在线学习算法结合,开发出能够实时检测并修正数据偏差的"自适应归一化引擎",该引擎每5分钟对输入数据进行一次统计特性分析,当检测到均值或方差发生显著变化时(阈值设为3倍标准差),自动触发模型微调流程。
在某半导体晶圆厂的实践中,这一技术展现了惊人效果,该厂的光刻机数字孪生模型需要处理来自200多个传感器的数据,包括激光功率、曝光时间、光刻胶厚度等关键参数,由于设备老化,某关键传感器的输出值每周会产生约0.5%的漂移,传统方法需要人工每月校准一次,而应用自适应归一化引擎后,系统能够自动检测到这种缓慢漂移,并通过调整归一化参数进行补偿,三个月的连续运行数据显示,模型预测误差始终控制在1.2%以内,而传统方法下这一数值会随着时间推移线性增长至4.7%。 2026年国家公园与绿色荒漠化防治及绿色服务链领域迎来新发展,相关应用不断深化
这种动态校准能力在复杂工业场景中尤为重要,以钢铁企业的连铸工序为例,从钢水浇注到板坯成型需要经历液态、半固态、固态多个相变阶段,每个阶段的物理特性差异巨大,传统数字孪生模型需要为不同阶段分别建模,而应用Batch Normalization技术后,系统可以通过动态调整归一化参数,实现单一模型对全流程的覆盖,某钢厂的实际测试显示,这种"全流程模型"的预测精度比分段模型提高了15%,同时模型维护成本降低了40%。
边缘计算与Batch Normalization的协同进化
随着5G+工业互联网的普及,边缘计算正在成为数字孪生的新战场,2026年,华为与海尔联合开发的"边缘孪生一体机"提供了新的解决方案,这款设备将Batch Normalization算法固化在专用AI芯片中,实现了数据预处理的硬件加速,在青岛某家电工厂的测试中,该设备能够在10毫秒内完成1000个数据点的归一化处理,满足实时控制系统的时延要求。
 2026年聚焦自然保护区与节能改造及氢能技术新趋势,应用场景不断拓展
2026年聚焦自然保护区与节能改造及氢能技术新趋势,应用场景不断拓展
更值得关注的是边缘-云端协同架构的创新,在某风电场的实践中,工程师们将Batch Normalization分为两个层级:边缘节点负责局部数据的快速归一化,云端则进行全局统计特性的聚合与更新,具体流程是:每个风力发电机的边缘设备每分钟计算一次本地数据的均值和方差,并将这些统计量上传至云端;云端每10分钟对所有边缘节点的统计量进行加权平均,生成全局归一化参数,再下发至各个边缘节点,这种架构既保证了实时性,又解决了单机统计量不足的问题。
这种协同架构在跨工厂场景中优势明显,某跨国汽车集团在全球有23个生产基地,每个工厂的数字孪生系统都采用相同的Batch Normalization参数初始化方案,但通过云端协同机制定期更新全局参数,当某工厂引入新型焊接机器人时,其产生的特殊数据模式会通过云端参数更新自动传播到其他工厂,使得整个集团的数字孪生系统能够共享学习成果,三个月内,新设备模型的训练时间从平均45天缩短至7天,模型准确率提升了22个百分点。 2026年无人机应用与绿色制造热度持续上升,相关领域迎来新发展
从理论到实践:Batch Normalization的实施路线图
对于正在推进数字孪生项目的企业,2026年的实践提供了清晰的实施路径,第一步是数据审计与特征工程,需要建立覆盖全生命周期的数据字典,明确每个数据源的物理意义、量纲、采样频率等关键属性,某化工企业的经验值得借鉴:他们开发了一套数据质量评估矩阵,从完整性、准确性、及时性、一致性四个维度对每个数据点进行评分,只有评分超过80分的数据才允许进入Batch Normalization流程。
第二步是归一化参数的选择,工业场景中通常采用Z-score标准化方法,即对每个特征减去其均值再除以标准差,但某精密加工企业的实践显示,对于周期性波动数据(如机床主轴温度),采用Min-Max标准化(将数据线性映射到[0,1]区间)效果更好,关键是要根据数据分布特性选择合适的归一化方法,必要时可以结合多种方法。
第三步是动态阈值的设定,在施耐德电气的实践中,他们通过历史数据分析建立了动态阈值