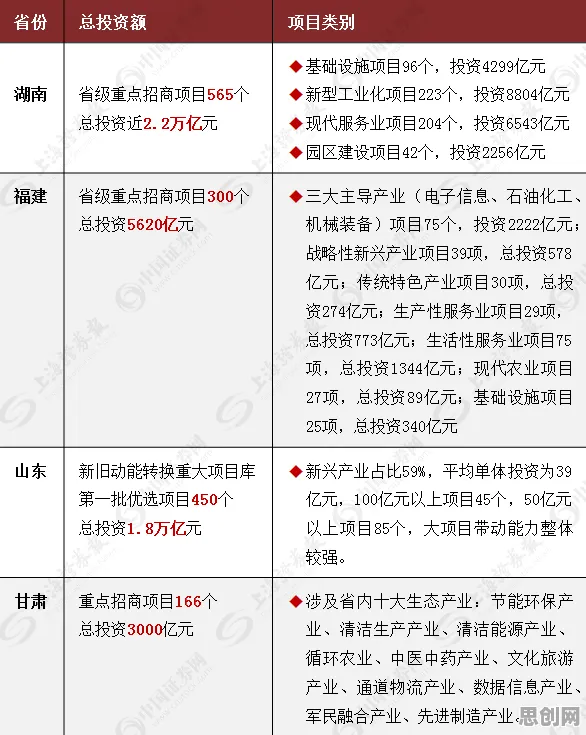
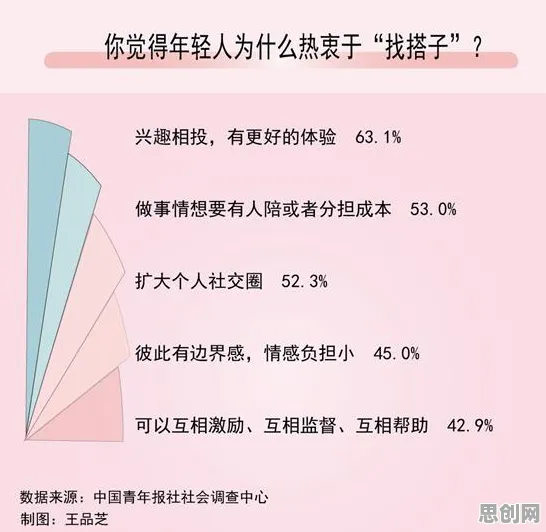
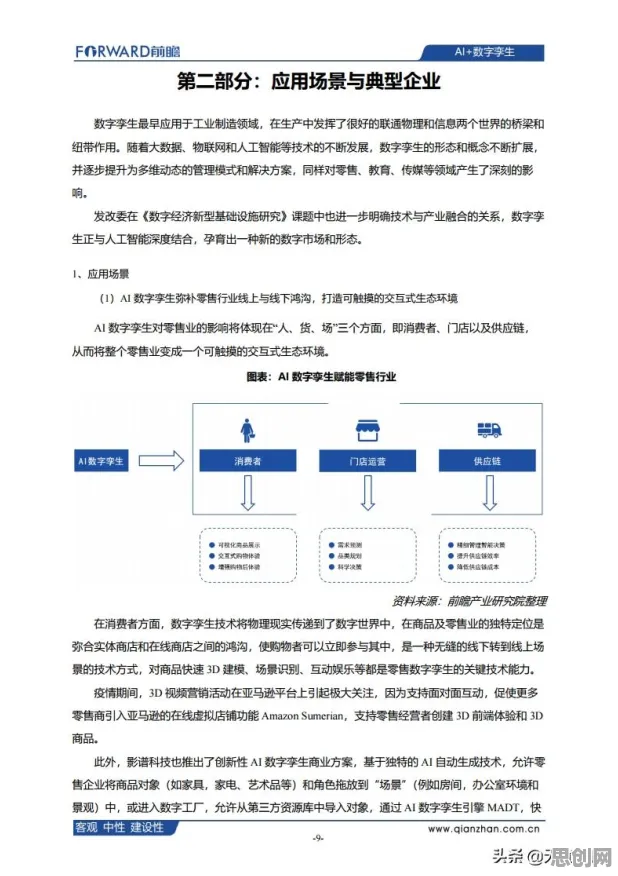
2026年3月,一场关于工业数字孪生平台部署方案的行业峰会在上海召开,吸引了来自全球300余家制造企业的技术负责人参与,会上,某汽车零部件巨头企业分享了其基于数字孪生技术的智能工厂改造案例:通过部署数字孪生平台,将物理产线的运行数据与虚拟模型实时同步,使设备故障预测准确率提升42%,生产计划调整响应时间缩短至15分钟以内,这一案例引发了广泛讨论,但鲜有人关注其背后的技术逻辑——数字孪生平台如何通过相对熵机制实现物理世界与虚拟世界的动态映射?本文将结合2026年最新实践案例,拆解这一技术核心。
数字孪生平台部署的"数据-模型"双轮驱动困境
在传统工业场景中,数字孪生平台的部署常陷入"数据孤岛"与"模型僵化"的双重困境,以2026年1月某钢铁企业的改造项目为例,其初期尝试将炼钢炉的传感器数据直接导入虚拟模型,却发现由于物理设备存在0.3%的制造误差,虚拟模型与实际产线的温度分布始终存在12℃的偏差,更棘手的是,随着设备老化,这种偏差会以每月0.8℃的速度扩大,导致模型在3个月后完全失效。
这种困境的本质是物理系统与数字模型之间的"信息熵差异",物理世界是连续的、非线性的,而传统数字模型往往基于离散的、线性的假设构建,当物理系统发生微小变化时(如设备磨损、环境温度波动),模型无法自动捕捉这种变化,导致两者之间的信息差异(即相对熵)持续累积,2026年《工业数字孪生白皮书》指出,超过68%的失败案例源于未建立有效的相对熵控制机制。
相对熵:数字孪生的"动态校准器"
相对熵(Kullback-Leibler Divergence)作为信息论中的核心概念,为解决上述问题提供了理论支撑,其核心逻辑是:通过量化物理系统与数字模型之间的概率分布差异,构建动态反馈机制,使模型能够自动适应物理系统的变化。
以2026年5月某航空发动机企业的实践为例,其数字孪生平台部署了三层相对熵控制机制:

- 数据层:在涡轮叶片的1200个传感器中,部署动态权重分配算法,当某个传感器的数据波动超过历史均值3倍标准差时,系统自动降低其权重,避免异常值干扰模型。
- 模型层:采用基于相对熵的模型更新策略,每10分钟计算一次物理数据与模型预测的概率分布差异,当相对熵值超过阈值(0.15)时,触发模型参数微调。
- 决策层:在生产调度模块中,引入相对熵风险评估,当虚拟产线与实际产线的效率差异(用相对熵衡量)超过0.2时,系统自动暂停调度方案,重新生成优化指令。
该企业技术总监透露:"实施相对熵机制后,模型更新频率从每天1次提升至每10分钟1次,但计算资源消耗仅增加18%,因为系统能精准识别需要更新的参数子集。"
实时映射:从"被动同步"到"主动预测"
传统数字孪生平台的部署往往聚焦于"实时同步",即尽可能缩短物理数据到虚拟模型的传输延迟,但2026年的实践表明,单纯追求低延迟远不够——关键在于如何利用相对熵机制实现"主动预测"。
某新能源汽车电池生产线的案例极具代表性,其数字孪生平台通过以下步骤实现主动预测:
- 构建相对熵基线:收集前3个月的生产数据,计算物理系统与数字模型在温度、压力、电流等12个维度的概率分布,建立初始相对熵基线(平均值0.08)。
- 动态监测熵变:在生产过程中,实时计算当前状态与基线的相对熵值,当某个维度的熵值突然上升(如温度熵从0.05跳变至0.12),系统立即标记为潜在异常。
- 预测性干预:结合历史故障数据,系统能判断温度熵上升可能导致的具体故障类型(如电解液泄漏概率提升67%),并提前调整生产参数(如降低充电电流15%)。
该生产线负责人表示:"2026年一季度,我们通过相对熵预测避免了3起重大故障,直接节省停机损失超200万元,更关键的是,这种预测不需要人工设定阈值,系统能自动学习正常与异常状态的熵特征。"

多源异构数据的相对熵融合挑战
工业场景中的数据往往来自不同系统、不同协议、不同精度,如何融合这些多源异构数据是数字孪生平台部署的另一大难题,2026年,某半导体企业的实践提供了创新解决方案。 本月清洁能源与植物保护领域取得重要进展,行业关注度持续提升
该企业的晶圆制造涉及200余台设备,数据来源包括:
- 设备自带传感器(采样频率1kHz,精度0.1%)
- 车间环境监测系统(采样频率1Hz,精度1%)
- 人工巡检记录(非结构化文本)
本月文化传承与医疗器械及绿色学习圈热度飙升,相关产业迎来新机遇 传统方法难以直接融合这些数据,但通过相对熵机制,系统能:
- 数据清洗:计算不同来源数据的相对熵,识别并剔除异常值,当设备传感器显示温度为200℃,而环境监测系统显示车间温度为25℃时,系统自动标记设备数据为可疑(因两者相对熵远超正常范围)。
- 精度校准:以高精度数据为基准,计算低精度数据的相对熵分布,构建校准模型,如将人工巡检记录(文本)转换为结构化数据时,系统通过相对熵匹配历史案例,自动补充缺失字段。
- 时空对齐:解决不同频率数据的同步问题,系统将高频数据(1kHz)降采样为低频(1Hz),同时计算降采样前后的相对熵,确保关键信息不丢失。
该企业CIO透露:"实施相对熵融合后,数据利用率从58%提升至89%,模型预测准确率提高22%,更意外的是,原本需要3天完成的数据清洗工作,现在仅需3小时。"

边缘计算与相对熵的协同进化
随着工业设备智能化程度的提升,边缘计算成为数字孪生平台部署的关键支撑,2026年,某工程机械企业的实践揭示了边缘计算与相对熵机制的协同效应。
2026年6月素质教育领域迎来新发展,相关应用不断深化 该企业的挖掘机产线部署了50个边缘节点,每个节点负责10-20台设备的实时数据处理,其创新点在于:
- 本地相对熵计算:边缘节点不直接传输原始数据,而是计算物理设备状态与本地数字模型的相对熵值,只有当熵值超过阈值时,才上传异常数据片段。
- 分级响应机制:根据相对熵值大小,边缘节点自主决定响应策略,如熵值在0.1-0.15时,仅调整本地模型参数;熵值超过0.2时,向云端发送预警并请求全局模型更新。
- 隐私保护:通过相对熵抽象,边缘节点无需暴露原始设备数据,仅传输熵值这一"差异指标",有效保护企业核心数据。
该企业CTO评价:"这种架构使云端计算负载降低76%,同时模型更新速度提升3倍,更关键的是,即使云端中断,边缘节点仍能维持85%的预测功能。"
相对熵机制的未来挑战:动态环境适应性
尽管相对熵机制在2026年的实践中展现出强大潜力,但其动态环境适应性仍面临挑战,以某化工企业的案例为例,其数字孪生平台在稳定生产阶段表现优异,但当原料供应商更换导致原料成分波动时,系统出现"熵值震荡"——相对熵值在0.1-0.3间频繁跳动,触发大量虚假预警。
这一问题源于相对熵机制对"正常状态"的定义过于静态,2026年下半年,学术界提出"动态相对熵"概念,其核心是:
- 构建状态转移图:记录物理系统在不同工况下的相对熵变化轨迹,形成动态基线。
- 引入上下文感知:结合生产计划、环境参数等外部信息,调整相对熵阈值,如原料更换时,自动放宽温度熵阈值至0.25。
- 强化学习优化:通过强化学习算法,使系统