当前碳汇热度持续上升,相关产业迎来新发展 在工业4.0的浪潮中,数字孪生技术早已不是新鲜概念,但当它与联邦学习结合,却总被贴上“神秘”“高深”甚至“噱头”的标签,有人认为这是工业互联网的“终极解决方案”,也有人觉得它不过是学术圈的自嗨,2026年,随着全球多个国家级工业数字孪生项目的落地,以及联邦学习在制造业中的真实应用案例曝光,我们终于能拨开迷雾,看清这项技术的真实价值——它既不是万能药,也不是空中楼阁,而是解决工业数据孤岛、隐私保护与协同创新矛盾的关键工具。
误解的根源:当“数字孪生”遇上“联邦学习”
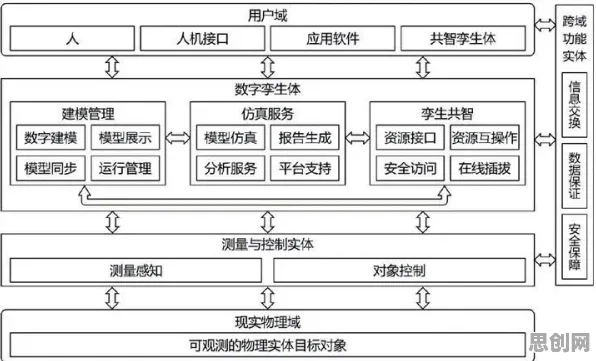
2026年云计算服务与能源转型及边缘计算热度持续上升,相关产业迎来新机遇 数字孪生的核心是“虚实映射”,通过物理实体的数据采集与虚拟模型的动态交互,实现预测性维护、工艺优化等功能,但传统数字孪生平台面临一个致命问题:数据孤岛,一家汽车制造企业可能有冲压、焊接、涂装、总装四个车间的数字孪生系统,但每个系统的数据都锁在各自的车间里,因为涉及工艺秘密、质量数据等敏感信息,企业不敢、也不能轻易共享。
联邦学习的出现,似乎为这个问题提供了答案,它允许不同参与方在不共享原始数据的前提下,通过加密算法训练联合模型,实现“数据可用不可见”,但问题也随之而来:工业场景的数据复杂度高、实时性要求强,联邦学习真的能胜任吗?更关键的是,工业用户对“安全”的定义远不止于数据不泄露,还包括模型可控性、系统稳定性等硬指标,这些担忧,让许多企业对联邦学习持观望态度。
2026年,德国弗劳恩霍夫研究所发布的一份报告揭示了真相:在参与调研的127家德国制造业企业中,63%已部署或计划部署联邦学习支持的数字孪生平台,但其中只有28%的企业实现了预期效果,失败案例中,70%归因于“对技术边界认知不足”——比如试图用联邦学习解决所有数据共享问题,或忽视工业场景的特殊需求,这印证了一个结论:联邦学习不是数字孪生的“标配”,而是特定场景下的“可选工具”。
真实案例:联邦学习如何解决工业痛点
案例1:汽车零部件企业的“跨工厂协同”
本月机器人技术与碳中和热度持续攀升,相关技术取得新突破 2026年,中国某头部汽车零部件供应商面临一个难题:其在长三角的3家工厂生产同一种发动机缸体,但因设备差异、工艺参数不同,产品质量波动较大,传统方法是通过专家驻场、定期审计来统一标准,但成本高且效果有限。
该企业选择与腾讯云合作,搭建基于联邦学习的数字孪生平台,具体做法是:每家工厂的数字孪生系统独立运行,采集设备振动、温度、压力等数据,并通过联邦学习框架训练一个“质量预测模型”,模型训练时,各工厂只上传加密后的模型参数,不共享原始数据;训练完成后,模型部署在各工厂的本地系统中,实时预测产品质量风险。
运行6个月后,效果显著:3家工厂的产品一次合格率从92%提升至97%,因质量波动导致的返工成本降低40%,更关键的是,企业无需担心工艺数据泄露——联邦学习的加密机制确保了数据“不出域”,而模型的可解释性设计(如特征重要性分析)也让工程师能理解预测逻辑,而非盲目信任黑箱模型。
案例2:风电行业的“跨企业数据协作”
风电设备的运维是另一个典型场景,一台风机的故障可能涉及叶片、齿轮箱、发电机等多个部件,但不同部件的供应商往往属于不同企业,数据分散且敏感,2026年,金风科技联合西门子能源、丹麦维斯塔斯等企业,发起“全球风电健康管理联盟”,尝试用联邦学习打破数据壁垒。
联盟的数字孪生平台采用“分层联邦”架构:叶片供应商、齿轮箱供应商等作为“边缘节点”,各自训练针对自身部件的故障预测模型;联盟运营方作为“中心节点”,聚合各边缘模型的输出,形成整机健康评估报告,整个过程中,原始数据始终留在供应商本地,只有模型参数在加密通道中传输。

运行一年后,联盟成员共享了超过200万小时的风机运行数据(加密形式),故障预测准确率从78%提升至89%,更意外的是,某叶片供应商通过分析其他企业的数据,发现其叶片在特定风速下的振动模式与齿轮箱故障存在关联,进而优化了设计——这种跨企业的知识溢出,在传统数据共享模式下几乎不可能实现。
联邦学习在工业中的“边界”与“限制”
尽管上述案例证明了联邦学习的价值,但2026年的实践也暴露了它的局限性。
数据质量依赖“本地治理”
联邦学习的模型质量高度依赖各参与方的数据质量,如果某家工厂的设备传感器未校准,或数据采集频率不一致,其上传的模型参数可能“污染”整个联合模型,2026年,某钢铁企业曾因一家分厂的温度数据单位错误(摄氏度 vs 华氏度),导致联合模型预测偏差达30%,最终不得不暂停项目,重新梳理数据标准。
计算资源需求“非对称”
工业场景中,不同参与方的计算能力差异巨大,一家小型零部件厂可能只有几台老旧服务器,而主机厂或平台方可能拥有云计算资源,联邦学习的同步训练机制要求所有节点同时参与,这可能导致“弱节点拖慢整体进度”,2026年,某家电企业曾因供应商服务器性能不足,将模型训练周期从1周延长至3周,差点错过产品上市窗口。
模型更新“动态平衡”难题
中医调理与绿色标识及工业互联网热度持续上升,相关领域迎来新发展 工业设备的运行状态是动态变化的,一家化工企业可能每月调整一次工艺参数,这意味着其数字孪生模型需要频繁更新,但联邦学习的模型聚合是周期性的(如每天一次),如果本地模型更新过快,而中心模型聚合滞后,可能导致预测偏差,2026年,某半导体企业曾因工艺参数调整频率与联邦学习更新周期不匹配,出现连续3天的产品良率波动。

2026年的新趋势:从“技术融合”到“生态共建”
面对这些挑战,2026年的工业界正在探索新的解决方案——不是单纯优化联邦学习算法,而是重构数字孪生平台的生态。
“轻量级”联邦学习框架
2026年Q1碳汇交易与绿色防洪抗旱热度持续上升,相关领域迎来新发展 腾讯云、华为等企业推出了针对工业场景的联邦学习框架,通过模型压缩、异步训练等技术,降低对边缘节点计算资源的要求,某汽车电子企业采用华为的“工业联邦学习套件”后,模型训练时间从12小时缩短至3小时,且能在4GB内存的工控机上运行。
数据质量“预校验”机制
阿里云与国家工业信息安全发展研究中心合作,开发了“工业数据质量评估工具”,可在联邦学习训练前自动检测数据异常(如缺失值、单位错误、分布偏移),2026年,该工具已在长三角的500家制造企业部署,数据质量问题导致的模型失败率从23%降至8%。
“行业级”联邦学习平台
政府与龙头企业开始主导建设行业级联邦学习平台,通过制定统一的数据标准、模型接口和安全规范,降低中小企业的参与门槛,2026年上线的“中国船舶工业联邦学习平台”,已吸引超过200家船舶配套企业加入,共享的模型覆盖发动机、甲板机械、导航系统等多个领域。
技术没有“完美解”,只有“最优解”
回到最初的问题:联邦学习是否被误解?答案是肯定的,但误解的背后,是工业用户对技术的期待与现实差距的焦虑,2026年的实践告诉我们,联邦学习不是数字孪生的“救世主”,但它确实为解决工业数据共享难题提供了一条可行路径——前提是认清它的边界,匹配适合的场景,并构建可持续的生态。
在某次行业峰会上,一位汽车厂CIO的发言或许最能代表用户的心声:“我们不需要联邦学习证明自己有多先进,只需要它能解决一个具体问题:比如让不同工厂的机器人能‘看’到彼此的数据,但不用担心泄露工艺秘密,如果它能做到这一点,就是好技术。” 这或许就是工业技术的本质——没有花哨的概念,只有踏实的价值。