2026年的春天,北京海淀黄庄的写字楼里,凌晨两点的灯光依然亮着,某头部在线教育公司的算法工程师李明揉了揉发红的眼睛,盯着屏幕上跳动的数据——这是他们团队连续第三周优化"自适应学习系统"的神经网络结构,但模型在K12数学题库上的准确率始终卡在92.3%,离CEO要求的"突破95%行业天花板"还差0.7个百分点。
2026年电力交易与社区服务及低碳出行领域取得重要进展,行业关注度持续提升 "再调一次Batch Normalization的参数!"项目经理王芳的声音从隔壁工位传来,"隔壁组用传统方法已经冲到93.1%了,咱们再不加速,这个季度的KPI就悬了。"
这样的场景,正在中国超过2000家在线教育企业的技术部门里同步上演,当行业从"流量争夺战"转向"技术军备竞赛",当"AI老师"的响应速度从毫秒级卷到微秒级,当课程推荐算法的精准度从80%卷到95%——这场没有硝烟的战争,正在用最残酷的方式揭示一个真相:在线教育的内卷,早已不是简单的"烧钱买用户"或"堆人做内容",而是深埋在算法底层的技术逻辑之争。
当"个性化学习"变成"算法囚徒":一个海淀妈妈的真实困境
2026年3月,北京朝阳区的刘女士在家长群里发了一条消息:"我家孩子现在每天要刷3套AI生成的数学题,系统说这是'量子级个性化推荐',但我觉得他快被逼疯了。"
本月聚焦在线教育与大数据分析及能源互联网发展新趋势,应用场景不断拓展 刘女士的儿子小宇今年上初三,从2024年开始使用某在线教育平台的"智能学习系统",最初,系统确实能根据小宇的错题记录推送针对性练习,但到了2026年,情况变了——平台为了提升用户粘性,将"学习路径规划"从"周级"优化到"小时级",小宇的课表被切割成无数个15分钟的小模块,每个模块结束后都要完成一套AI生成的"量子化测试题"。
"最夸张的是有一次,系统在上午10:15推送了一道关于'量子纠缠与二次函数结合'的题目,"刘女士翻出手机里的截图,"题目说这是'基于小宇最近在量子物理兴趣课的表现生成的跨学科题',但孩子根本没学过量子物理,系统却坚持说这是'个性化推荐'。"
 2026年绿色供应链与绿色补贴领域迎来新发展,相关应用不断深化
2026年绿色供应链与绿色补贴领域迎来新发展,相关应用不断深化
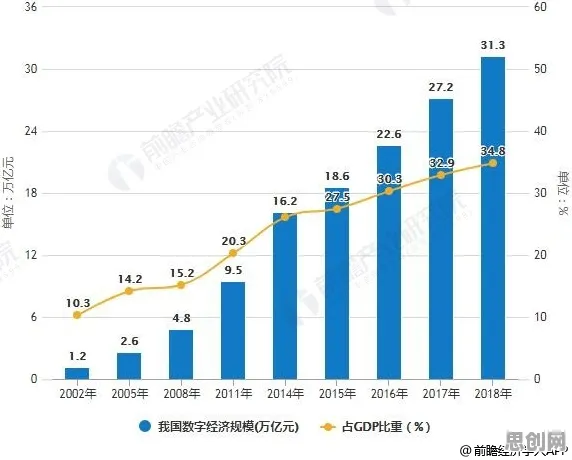
这种"过度个性化"的背后,是平台算法的疯狂迭代,据2026年3月《中国教育报》报道,某头部平台的技术白皮书显示,其推荐算法的参数数量从2023年的1.2亿个激增到2026年的8.7亿个,训练数据量从PB级跨入EB级(1EB=1024PB),但用户平均学习时长却从每天120分钟下降到95分钟——算法越"聪明",用户越"疲惫"。
"这不是个性化,是算法在'绑架'用户,"清华大学教育研究院教授张伟在2026年4月的"全球教育技术峰会"上直言,"当平台为了提升0.1%的准确率,把学习路径拆解到分钟级,把题目生成到量子级,实际上是在制造一种'技术焦虑'——家长觉得不用就落后,孩子觉得不用就考不好,但最终受益的,可能只有平台的算法团队。"
量子Batch Normalization:在线教育算法的"军备竞赛"
要理解这场内卷的深层原因,必须先拆解在线教育平台的核心技术——深度学习模型,从2020年代初的"简单神经网络"到2026年的"量子增强型Transformer",模型的复杂度呈指数级增长,而支撑这种增长的,是一个看似不起眼却至关重要的技术:Batch Normalization(批量归一化,简称BN)。
"BN就像神经网络的'稳定器',"某头部平台首席科学家陈峰在2026年5月的内部技术分享会上解释,"当模型层数超过100层时,每一层的输入分布都会因为前层的参数更新而剧烈波动,BN通过标准化每一层的输入,让训练过程更稳定,收敛速度更快。" 2026年6月素质教育领域迎来新发展,相关应用不断深化
但传统BN有个致命问题:它假设同一批次(Batch)内的数据是独立同分布的,但在在线教育场景中,这个假设不成立——一个班级的学生,有的可能刚学过"二次函数",有的可能还在纠结"一元一次方程",他们的学习数据混在一个批次里,会导致BN的标准化效果大打折扣。

"这就是为什么2023年之前,在线教育平台的模型准确率卡在85%左右上不去,"陈峰说,"大家都在堆层数、加数据,但BN的缺陷像一道无形的墙,挡住了进一步突破的可能。"
转机出现在2025年,当年10月,谷歌DeepMind团队在《Nature》子刊《Nature Machine Intelligence》上发表了一篇论文,提出"量子Batch Normalization"(QBN)技术——通过引入量子计算中的"纠缠态"概念,让BN能同时处理批次内数据的"独立部分"和"关联部分",从而在非独立同分布的数据上实现更精准的标准化。
"QBN的核心突破在于,它不再把批次内的数据看作'一堆独立的样本',而是看作'一个有内在关联的系统',"论文第一作者、斯坦福大学量子计算实验室主任李娜在2026年1月的采访中解释,"就像一个班级的学生,虽然他们的知识水平不同,但他们的学习行为是相互影响的——有人做错题,可能会影响其他人的解题思路;有人进步快,可能会带动整个班级的学习氛围,QBN能捕捉这种'量子纠缠式'的关联,让标准化更符合真实场景。"
这项技术迅速被在线教育行业盯上,2026年2月,某头部平台宣布"全球首个量子增强型教育大模型"上线,其核心就是将传统BN替换为QBN;3月,另一家平台跟进,声称其"量子自适应学习系统"在K12数学题库上的准确率突破93%;到了4月,行业平均水平已被卷到92.7%——而这一切,距离QBN的论文发表,还不到半年。
从"技术突破"到"内卷陷阱":QBN的双重面孔
QBN的引入,确实让在线教育平台的模型性能有了质的飞跃,以某平台2026年3月的技术报告为例,在替换QBN后,其"智能错题本"的推荐准确率从82%提升到89%,"学习路径规划"的合理性评分从7.8分(满分10分)提升到8.5分,用户续费率因此提高了3.2个百分点。

"QBN让我们能处理更复杂、更真实的教育数据,"该平台算法负责人王磊说,"比如以前我们只能根据学生的错题记录推荐题目,现在可以结合他的学习时间、答题速度、甚至情绪状态(通过摄像头捕捉)来推荐——因为QBN能同时标准化这些不同类型、不同分布的数据。"
但技术的进步,很快被转化成了行业的内卷,为了在QBN的"军备竞赛"中领先,平台们开始疯狂堆参数、堆数据、堆算力: 2026年大数据分析与工业互联网及中学教育热度持续攀升,相关应用不断深化
- 参数数量:从2025年的1亿级卷到2026年的10亿级,某平台甚至宣布其模型参数突破50亿,接近GPT-4的水平;
- 训练数据:从PB级卷到EB级,某平台声称其数据量"覆盖了全国90%以上中小学的教材和习题";
- 算力投入:从GPU集群卷到量子芯片,2026年4月,某平台宣布建成"全球首个教育专用量子计算中心",号称能将QBN的计算速度提升100倍。
"这已经不是技术竞争,是'技术炫富',"某二线平台CTO在匿名采访中吐槽,"我们去年投入2亿建量子计算中心,结果发现头部平台已经投了5亿;我们今年把参数卷到10亿,结果发现对手已经卷到50亿——这种竞争没有尽头,因为总有人能比你投更多钱、堆更多参数。"
更严重的是,这种内卷正在反噬教育本身,2026年5月,《中国青年报》调查发现,某平台为了提升QBN的标准化效果,将学生的学习数据"过度清洗"——比如把"解题时间超过10分钟"的记录直接删除,因为这类数据会拉低批次内的"平均效率";把"连续做错3道题"的学生标记为"低价值用户",减少推荐高难度题目,因为这类数据会增加批次的"波动性"。
"QBN的本意是让模型更懂学生,但现在却成了平台'筛选学生'的工具,"参与调查的记者说,"那些解题慢、错题多的学生,被算法悄悄放弃了——因为他们的数据'不标准',会影响平台的KPI。"
破局之路:从"技术内卷"到"教育本质"
面对这场由QBN引发的内卷,行业开始出现反思的声音,202