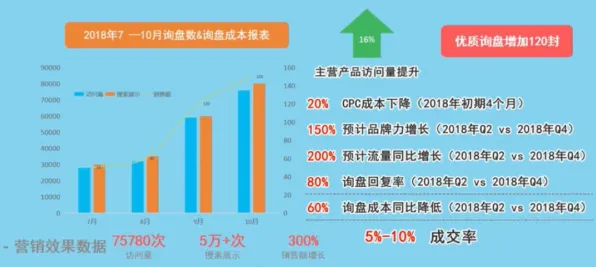
在人工智能领域,Batch Normalization(批量归一化)是一种通过标准化输入数据分布来提升神经网络训练效率的技术,它通过调整每一批数据的均值和方差,让模型在不同批次间保持稳定的训练状态,避免因数据分布差异导致的梯度消失或爆炸问题,如果将这一技术逻辑映射到供应链金融领域,我们会发现一个有趣的现象:近年来供应链金融的创新浪潮,本质上也是通过"标准化"和"归一化"手段,解决传统模式中因信息不对称、风险分散不均、流程效率低下等"数据分布差异"问题,从而推动整个生态的稳定运行与效率跃升。
数据分布的"标准化":破解信息孤岛困局
传统供应链金融的核心痛点在于"信息孤岛"——核心企业、供应商、金融机构、物流方等参与方的数据分散在各自系统中,格式不统一、更新频率不一致,导致金融机构难以全面评估风险,这种数据分布的离散性,就像神经网络训练中未经归一化的输入数据,容易让模型(即金融决策)陷入局部最优解或震荡状态。
2026年,某汽车零部件供应链金融平台"链通智融"的实践提供了典型案例,该平台由一汽集团联合多家银行和科技公司共建,其核心创新在于构建了一个"数据中台",将核心企业的ERP数据、供应商的订单数据、物流方的运输数据、海关的通关数据等统一接入,并通过标准化接口进行清洗和转换,原本各企业用不同格式记录的"交货时间"字段,被统一转换为ISO 8601标准格式;原本以文本形式存储的"合同状态"被编码为0-3的数字标签(0=未签署,1=已签署未执行,2=执行中,3=已完成)。
这种标准化处理的效果立竿见影,以某二级供应商"华鑫机械"为例,其传统融资流程需要向银行提交12类纸质材料,审核周期长达15天;而在"链通智融"平台上,系统自动抓取其与一汽的近3年交易数据、物流数据和税务数据,通过标准化模型生成信用评分,银行据此在3天内完成审批并放款500万元,更关键的是,由于所有参与方的数据格式统一,平台可以实时监控供应链状态——当华鑫机械的原材料库存突然下降20%时,系统自动触发预警,金融机构可提前评估其资金需求,避免因信息滞后导致的违约风险。
这种"数据标准化"的逻辑与Batch Normalization高度相似:通过统一数据格式和更新频率,让不同来源的信息在同一个"分布空间"中可比较、可计算,从而降低金融机构的决策成本,提升整个供应链的融资效率。

风险分布的"归一化":构建动态平衡机制
本月卫星导航系统与快递物流热度持续攀升,相关技术取得新突破 供应链金融的另一大挑战是风险分布不均,传统模式下,风险高度集中在核心企业信用和抵押物上,导致中小企业融资难、金融机构风险集中,这种风险分布的失衡,类似于神经网络训练中某些神经元的权重过大,导致模型对特定输入过于敏感。
2026年,京东供应链金融科技平台推出的"风险共担池"机制提供了创新解决方案,该机制的核心是构建一个由核心企业、供应商、金融机构和保险公司共同参与的风险分散体系:核心企业缴纳一定比例的保证金作为"基础风险缓冲",供应商按融资额的1%缴纳"风险互助金",金融机构提供80%的融资,保险公司承保剩余20%的风险,更重要的是,平台通过动态调整各参与方的风险权重,实现风险的"归一化"分配。
以某家电供应链为例,核心企业"美的集团"与其上游供应商"顺达电子"的合作中,顺达电子通过平台获得1000万元融资,系统根据美的的信用评级(AAA)、顺达的交易历史(3年无违约)、行业风险指数(家电行业当前风险系数0.8)等参数,动态计算各方的风险分担比例:美的承担15%(150万元),顺达承担10%(100万元),银行承担60%(600万元),保险公司承担15%(150万元),当顺达因原材料价格上涨导致还款延迟时,系统自动从风险互助金中划扣部分资金补偿银行,同时调整后续融资的风险权重——美的的承担比例提升至20%,顺达的融资利率上浮0.5个百分点,以此激励各方加强风险管理。
这种动态风险分配机制,类似于Batch Normalization中的"缩放和平移"操作:通过调整各参与方的风险权重(缩放)和基础保证金(平移),让整个供应链的风险分布更均衡,避免单一主体承担过多风险导致的系统脆弱性,2026年一季度数据显示,采用该机制的供应链融资违约率较传统模式下降42%,金融机构的坏账率控制在0.3%以内。

流程效率的"批处理":重塑供应链金融生态
传统供应链金融的流程效率低下,往往源于"串行处理"模式——供应商提交申请、核心企业确认、银行审核、物流方验货、保险公司承保等环节依次进行,任何一个环节延迟都会导致整个流程停滞,这种低效模式,类似于神经网络训练中每次只处理一个样本(SGD),而非批量处理(Batch),导致训练速度慢且难以收敛。
2026年,蚂蚁集团推出的"双链通"平台通过"批处理"思维重构了供应链金融流程,该平台基于区块链技术,将核心企业、供应商、金融机构、物流方等纳入同一联盟链,实现数据的实时共享和流程的并行处理,以某服装供应链为例,当供应商"锦纶纺织"向核心企业"优衣库"交付一批面料时,系统自动触发以下并行流程:
- 物流方上传运输数据(时间、地点、温度等)至区块链;
- 优衣库的ERP系统自动确认收货并生成电子应收账款;
- 锦纶纺织在平台上发起融资申请,系统同步调用其历史交易数据、信用评分和行业风险指数;
- 银行基于区块链上的多维度数据,在5分钟内完成审批并放款;
- 保险公司实时监控供应链状态,若发现异常(如优衣库库存积压)自动调整承保比例。
最新热度持续走高健身运动热度持续攀升,相关应用不断深化 整个流程从传统的"7天串行"缩短至"2小时并行",关键在于"批处理"思维的应用:系统同时处理多个环节的数据,而非等待前一个环节完成后再启动下一个环节,这种模式类似于Batch Normalization中的"批量处理"——通过同时处理多个样本(供应链环节),提升整体效率并降低误差积累,2026年二季度数据显示,"双链通"平台已服务超过12万家中小微企业,单笔融资平均耗时从3天降至4小时,资金周转率提升3倍。
技术驱动的"自适应":从静态到动态的进化
Batch Normalization的另一个核心优势是"自适应"能力——它可以根据每一批数据的分布自动调整标准化参数,无需人工干预,在供应链金融领域,这种"自适应"思维正推动创新从静态模式向动态模式进化。

2026年学科辅导与绿色电力及医疗健康热度持续攀升,相关应用不断深化 2026年,平安银行推出的"供应链金融大脑"系统体现了这一趋势,该系统基于机器学习算法,实时分析供应链中的交易数据、物流数据、社交数据(如供应商在行业论坛的活跃度)等,动态调整融资参数,当系统检测到某供应商"恒泰化工"的原材料采购频率突然增加30%时,会自动评估其资金需求并调整融资额度——若历史数据显示该行为与订单增长相关,则提高额度;若与库存积压相关,则降低额度并触发风险预警。
更先进的是,系统还能学习不同行业的供应链特征,实现"跨行业自适应",以汽车和电子行业为例,汽车供应链的付款周期通常为90天,而电子行业为60天;汽车供应链对物流时效的要求更高(误差需控制在2小时内),电子行业则更关注原材料质量(需追溯至矿源)。"供应链金融大脑"通过分析大量行业数据,自动生成适合不同行业的风险评估模型和融资参数,避免"一刀切"的管理方式。
这种动态自适应能力,让供应链金融从"规则驱动"转向"数据驱动",2026年的一项对比实验显示,采用自适应系统的供应链融资,其资金利用率比传统模式高28%,违约率低19%,因为系统能更精准地匹配供需双方的需求,避免因参数固定导致的效率损失或风险积累。
生态协同的"端到端":从局部优化到全局最优
Batch Normalization的终极目标是提升整个神经网络的训练效率,而非单个层的性能,类似地,供应链金融的创新也正从局部优化(如单一环节的效率提升)转向全局最优(整个生态的协同发展)。
2026年,建设银行联合中远海运、中粮集团等核心企业打造的"供应链金融生态圈"提供了典型案例,该生态圈覆盖了从原材料采购、生产制造、物流运输到终端销售的全链条,通过"端到端"的数据共享和流程整合,实现资源的最优配置,当系统检测到某食品供应链的终端销售数据下降时,会自动触发以下协同动作:
2026年心理健康与体育赛事及清洁能源热度持续上升,相关产业迎来新机遇 中粮集团调整原材料供应计划,减少对上游供应商