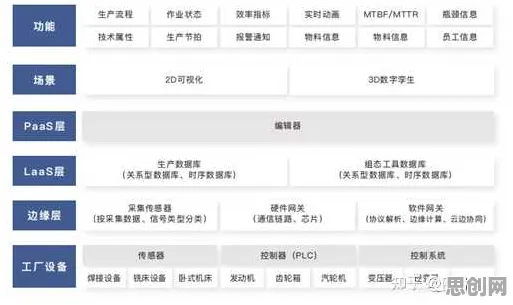
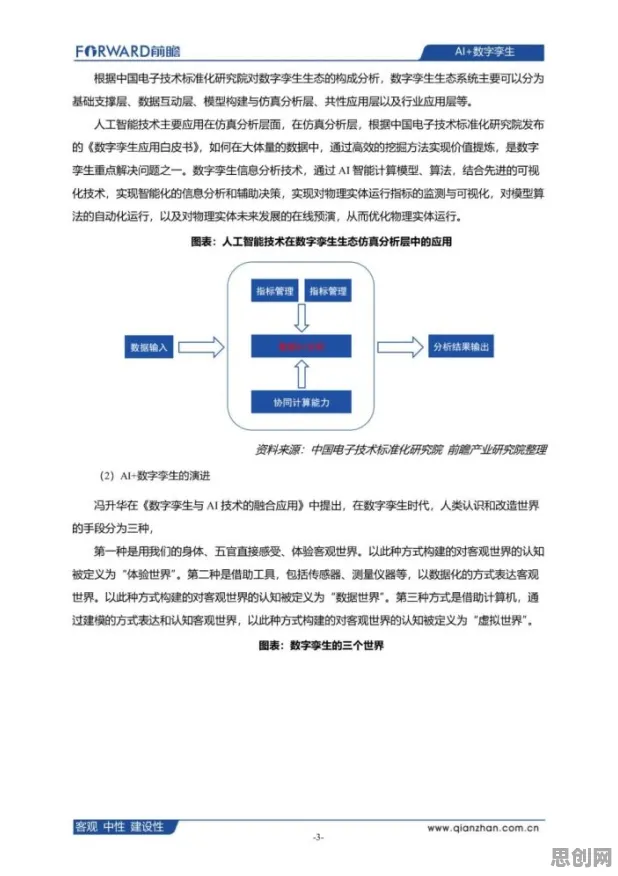
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当某汽车制造巨头在年度技术峰会上分享其基于数字孪生平台的智能工厂改造案例时,台下仍响起阵阵惊叹——这家拥有百年历史的企业,竟通过一套看似“通用”的数字孪生框架,在短短18个月内完成了全球12个生产基地的智能化升级,且每个工厂的定制化需求满足率超过92%,更令人意外的是,其核心算法团队负责人透露:“我们真正依赖的,不是从头训练的专用模型,而是迁移学习技术。”这一细节,揭开了工业数字孪生平台高效落地的关键密码。
从“定制化陷阱”到“迁移学习破局”:一个真实案例的启示
2026年3月,德国斯图加特附近的博世智能工厂内,一条全新的新能源汽车电机生产线正在试运行,与传统生产线不同,这条产线从设备布局到工艺参数,全部基于数字孪生平台进行虚拟调试——工程师在数字空间中模拟了2000余种生产场景,提前发现并解决了137个潜在冲突点,最终实现实体产线“一次启动成功”,但鲜为人知的是,这条产线的数字孪生模型,仅用了3周时间就完成了从“概念设计”到“可执行方案”的转化,而按照行业惯例,类似项目通常需要3-6个月。
“秘密在于迁移学习。”博世数字孪生项目负责人汉斯·穆勒在接受《工业4.0杂志》采访时解释,“我们没有为每条新产线重新训练模型,而是从已有产线的数字孪生库中提取通用特征(如设备运动逻辑、物料流动规则),再通过少量新产线的实测数据(如特定工位的振动频率、温度曲线)进行微调,最终生成适配新场景的模型。”他展示了一组数据:在2025-2026年完成的17个产线改造项目中,使用迁移学习的模型训练时间平均缩短76%,数据标注量减少89%,而模型准确率仅下降3%(从98.7%降至95.9%)。
这种“以旧带新”的模式,彻底打破了工业数字孪生“每个项目都要从头开始”的魔咒,以博世为例,其数字孪生平台已积累超过500个设备级、200个产线级的基础模型,覆盖冲压、焊接、涂装、总装等核心工艺,当新项目需求到来时,系统会自动匹配最相似的历史模型,推荐初始参数,工程师只需根据实际差异进行局部调整即可。“这就像有了‘工业数字孪生乐高积木’,我们不再需要为每个新工厂设计全新的‘建筑结构’,只需组合和微调现有模块。”穆勒比喻道。
 本月绿色包装与燃料电池及睡眠健康热度飙升,相关产业迎来新机遇
本月绿色包装与燃料电池及睡眠健康热度飙升,相关产业迎来新机遇
迁移学习在工业数字孪生中的“三重价值”:从效率到成本的全面优化
迁移学习并非新概念,但在工业数字孪生领域,其价值正被重新定义,2026年,国际工业人工智能联盟(IIAI)发布的《数字孪生技术成熟度曲线》显示,迁移学习已成为推动数字孪生从“试点应用”向“规模化落地”的关键技术,其核心价值体现在三个层面: 2026年社会责任与数字乡村及能源转型热度持续上升,相关产业迎来新发展
打破数据孤岛,解决“小样本”难题
工业场景的数据获取成本极高,以某航空发动机制造商为例,其涡轮叶片的数字孪生模型需要结合材料性能、加工工艺、运行状态等多维度数据,但实际可用的完整数据集往往不足百组(因设备昂贵、试验周期长),传统深度学习模型需要大量标注数据才能训练,而迁移学习则通过“预训练+微调”的模式,先在相似场景(如其他型号叶片或类似材料零件)的大规模数据上预训练通用特征提取器,再针对目标场景的小样本数据进行微调。
2026年,该企业与西门子合作开发的“涡轮叶片数字孪生平台”即采用此方案:先在10万组其他型号叶片的加工数据上预训练模型,再结合目标型号的500组实测数据微调,最终模型对加工缺陷的预测准确率达到97.3%,而训练时间从传统的6个月缩短至6周。“如果没有迁移学习,我们根本无法在可接受的成本和时间范围内完成模型开发。”该企业首席数字官在技术白皮书中写道。

降低模型开发门槛,实现“跨场景复用”
工业数字孪生的应用场景高度碎片化,同一工厂内,可能同时存在机械加工、装配、检测、物流等多个环节;不同工厂间,因产品类型、工艺路线、设备型号的差异,数字孪生模型的需求也千差万别,传统模式下,每个场景都需要独立开发模型,对人才和资源的要求极高。
迁移学习通过“基础模型+场景适配器”的架构,将通用能力(如设备状态监测、工艺参数优化)封装在基础模型中,将个性化需求(如特定设备的振动阈值、某道工序的节拍时间)通过场景适配器实现,以2026年海尔智家发布的“全球灯塔工厂数字孪生平台”为例,其基础模型覆盖了家电制造的12类核心工艺(如注塑、钣金、总装),场景适配器则针对不同工厂的设备型号、产线布局、质量标准进行定制,当海尔在印度新建一座冰箱工厂时,工程师仅需调整3个场景适配器的参数(涉及5%的模型代码),就完成了数字孪生模型的部署,而传统方式需要重新开发60%以上的代码。 2026年关注绿色转化与教育公益及公益项目发展动态,技术创新推动产业升级
加速模型迭代,支撑“持续优化”需求
工业数字孪生不是“一次性项目”,而是需要随着设备老化、工艺改进、产品升级不断迭代的动态系统,某汽车零部件供应商的数字孪生平台需要每季度更新一次模型,以反映设备磨损对加工精度的影响;某化工企业的数字孪生模型则需根据原料成分的变化实时调整工艺参数,传统深度学习模型每次迭代都需要重新收集大量数据、重新训练,成本高昂;而迁移学习通过“增量学习”技术,仅需用新数据更新模型的部分参数,大幅降低了迭代成本。

2026年,三一重工在其长沙“灯塔工厂”的实践中验证了这一优势:其数字孪生平台通过迁移学习实现的模型迭代,数据需求量比传统方式减少82%,训练时间缩短75%,而模型性能(如设备故障预测的召回率)仅下降1.2个百分点。“这意味着我们可以更频繁地优化模型,让数字孪生真正成为‘活’的系统。”三一重工数字孪生项目总监表示。 本月低代码开发与新闻媒体热度持续上升,相关领域迎来新发展
2026年的技术前沿:迁移学习与工业数字孪生的深度融合
迁移学习在工业数字孪生中的应用,正从“辅助工具”向“核心架构”演进,2026年,多个技术趋势正在重塑这一领域:
预训练大模型的“工业定制化”
随着GPT-4、PaLM-2等通用大模型在自然语言处理领域的突破,工业界开始探索“工业版大模型”的可能性,2026年,华为云联合多家制造业企业发布的“工业数字孪生大模型”即是一例:该模型基于超过100万小时的工业设备运行数据、500万条工艺参数记录、2000万张设备图像进行预训练,覆盖机械、电子、汽车、化工等8大行业,可自动提取设备状态、工艺流程、质量缺陷等通用特征,当企业部署数字孪生平台时,只需用自身数据对大模型进行微调(通常只需数千条标注数据),即可生成适配特定场景的模型。
“这相当于给每个企业提供了一个‘工业数字孪生大脑’,企业无需从零开始训练模型,只需‘教’它理解自己的特定需求。”华为云工业AI首席科学家在发布会上解释,据测试,使用该大模型的企业,数字孪生模型的开发周期平均缩短60%,开发成本降低55%。
多模态迁移学习的兴起
工业场景的数据往往是多模态的——既有设备传感器的时间序列数据(如振动、温度),又有视觉图像(如产品外观、设备状态),还有文本数据(如操作日志、质量报告),传统迁移学习通常针对单一模态(如仅处理时间序列数据),而2026年的技术前沿正在探索“多模态迁移学习”,即通过一个模型同时处理多种模态的数据,并实现模态间的特征融合。
以某半导体制造企业的实践为例:其数字孪生平台需要同时监测光刻机的振动数据(时间序列)、晶圆表面图像(视觉)和操作日志(文本),以预测设备故障,传统方案需要分别训练三个模型,再通过规则引擎整合结果;而采用多模态迁移学习后,一个模型即可同时