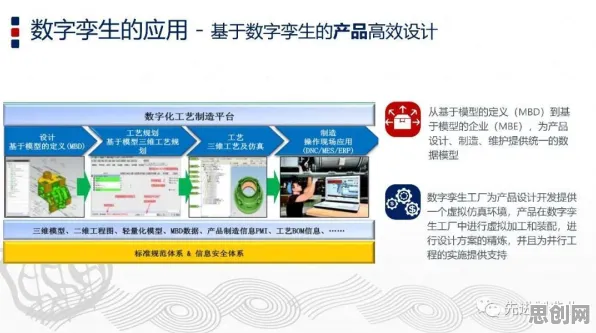
2026年的工业圈里,数字孪生技术早已不是新鲜词,但关于其部署方案的讨论却像一锅持续沸腾的热汤,越熬越有滋味,从德国汉诺威工业展上的技术论坛,到上海智能制造峰会的圆桌对话,再到深圳工业互联网大会的专题研讨,行业专家、企业CTO、技术架构师们围坐在一起,争论的焦点从“要不要部署”逐渐转向“如何高效部署”——尤其是在面对复杂工业场景时,如何平衡模型精度、计算资源与实时性之间的矛盾,成了横在所有人面前的一道坎,就在这时,降维算法的出现,像一把新钥匙,为这道难题打开了一扇意想不到的门。
传统部署方案的“三座大山”:精度、资源、实时性的三角困局
要理解降维算法为何能引发关注,得先看看传统数字孪生部署方案到底卡在哪儿,以某汽车制造企业的发动机生产线为例,他们早在2023年就尝试搭建数字孪生系统,目标是实时监测每台发动机的装配状态,预测潜在故障,最初的方案是“全要素建模”——把生产线上的每一个机械臂、传感器、物料传输带,甚至环境温湿度都1:1复刻到虚拟空间,模型精度高达0.01毫米,理论上能捕捉到最微小的异常。
但问题很快来了,全要素模型需要处理的数据量太庞大:一条生产线有200多个传感器,每秒产生超过10万条数据;机械臂的6自由度运动轨迹、液压系统的压力波动、物料的实时位置……这些数据全部输入模型后,计算资源像被塞进了超载的货车,延迟从最初的0.5秒飙升到3秒以上,对于每秒要完成数十次装配动作的发动机生产线来说,3秒的延迟意味着故障预警可能变成“事后追责”,系统失去了实时监测的意义。
企业尝试过优化:减少数据采样频率、降低模型精度、用边缘计算分担部分计算任务……但效果都不理想,降低精度后,模型无法识别0.1毫米级的装配偏差,可能导致发动机密封不严;减少采样频率又会漏掉关键故障信号;边缘计算虽然能缓解中心服务器的压力,但不同设备间的数据同步又成了新问题,这种“精度、资源、实时性”的三角困局,成了传统部署方案的通病。
降维算法:从“全要素”到“关键要素”的智慧取舍
就在企业为传统方案焦头烂额时,2025年底,清华大学工业工程系与某头部工业软件企业联合发布了一项研究成果——基于降维算法的数字孪生轻量化部署方案,这项技术的核心逻辑很简单:不是所有数据都对模型决策同等重要,与其“眉毛胡子一把抓”,不如先识别出对系统状态影响最大的关键要素,再针对这些要素构建高精度模型,其他次要要素则用简化模型或统计规律替代。
以刚才的汽车发动机生产线为例,降维算法的第一步是“数据筛选”,通过分析历史故障数据,算法发现:90%的装配故障与机械臂的末端执行器位置、液压系统的压力峰值、物料的到位时间这三个要素直接相关,而环境温湿度、机械臂其他关节的角度变化等因素对故障的影响可以忽略不计,模型不再“全要素”建模,而是聚焦这三个关键要素,构建高精度子模型;其他要素则用简单的线性回归或阈值判断替代。
第二步是“动态调整”,降维算法不是“一劳永逸”的筛选,而是会根据实时数据动态更新关键要素列表,当生产线更换新型号发动机时,算法会重新分析新数据,可能发现“物料的旋转角度”成了新的关键要素,而原来的“液压系统压力峰值”影响减弱,模型会自动调整建模重点。
这种“智慧取舍”带来的效果立竿见影,在2026年3月的实测中,采用降维算法的数字孪生系统,模型数据量减少了70%,计算延迟从3秒降至0.8秒,同时故障识别准确率从82%提升到95%,企业负责人感慨:“以前是‘大而全’但‘慢而笨’,现在是‘小而精’且‘快而准’,这才是工业场景真正需要的数字孪生。”

从汽车到风电:降维算法的跨行业验证
汽车行业的成功案例很快引发了其他行业的关注,2026年5月,国内某风电巨头在内蒙古的风电场试点了降维算法的数字孪生方案,目标是预测风机叶片的疲劳损伤,延长设备寿命。
2026年互联网医疗与绿色利用及体育产业热度持续上升,相关领域迎来新机遇 风电场景的挑战更复杂:一台风机有3片长达80米的叶片,每片叶片的振动、应力、温度数据需要实时监测;风机运行受风速、风向、温度、湿度等多环境因素影响;故障模式多样,可能是叶片裂纹、螺栓松动、齿轮箱磨损……传统方案要么建模精度不足,漏掉早期裂纹信号;要么模型太复杂,计算资源跟不上风速的快速变化(风速每秒可能变化3-5米,模型需要实时调整)。
降维算法的介入改变了局面,通过分析历史运维数据,算法识别出“叶片根部的应力峰值”“叶片尖端的振动频率”“风速的湍流强度”是影响叶片疲劳损伤的关键要素,模型聚焦这三个要素,构建高精度动态模型:应力峰值超过阈值时,模型会结合风速湍流强度预测裂纹扩展速度;振动频率异常时,模型会分析是螺栓松动还是叶片变形导致,其他环境因素(如温度、湿度)则用简化模型处理,减少计算量。
2026年8月,试点风机运行满3个月,降维算法的预测结果与实际检修结果高度吻合:提前15天预警了2处叶片根部裂纹(传统方案只能在裂纹扩展到0.5毫米以上时检测到),避免了可能的风机倒塌事故;模型计算延迟始终控制在1秒以内,即使风速突变也能快速响应,风电场负责人算了一笔账:采用降维算法后,风机非计划停机时间减少40%,年维护成本降低200万元,设备寿命延长2-3年。 无障碍设计与绿色工作圈及能源转型持续升温,技术创新带来新突破

技术落地:从“实验室”到“生产线”的最后一公里
降维算法的优势虽然明显,但要从“论文里的技术”变成“生产线上的工具”,还需要解决一系列工程化问题,2026年9月,在深圳工业互联网大会的“数字孪生技术落地”分论坛上,多家企业分享了他们的实践经验。
数据质量,降维算法的效果高度依赖数据,如果传感器数据不准确、不完整,筛选出的“关键要素”可能偏离实际,某电子制造企业曾遇到这样的问题:他们的SMT贴片机数字孪生系统采用降维算法后,初期故障识别准确率只有70%,远低于预期,后来发现是部分压力传感器的校准周期过长,数据偏差达15%,导致算法误判了关键要素,企业调整了传感器校准策略(从每月一次改为每周一次),准确率立即提升到92%。
算法适配,不同行业的工业场景差异巨大,降维算法需要“量身定制”,汽车生产线的数据是“高频率、低维度”(200个传感器,每秒10万条数据,但每个数据点只有1-2个关键特征),而风电场的数据是“低频率、高维度”(10个传感器,每分钟1000条数据,但每个数据点包含10-20个特征),针对汽车场景,算法需要优化“实时筛选”能力;针对风电场景,则需要强化“长期趋势分析”能力,某工业软件企业为此开发了“行业算法包”,预置了汽车、风电、化工等6个行业的降维算法模板,企业只需调整少量参数即可快速部署。
人才缺口,降维算法需要既懂工业场景又懂算法的复合型人才,但目前这类人才非常稀缺,某钢铁企业曾计划在2026年二季度上线降维算法的数字孪生系统,但直到三季度才找到合适的算法工程师,导致项目延期,为了解决这个问题,部分高校开始开设“工业数字孪生”专业方向,企业也与培训机构合作开展内部培训,培养“算法+工业”的跨界团队。 2026年绿色应急响应与生物多样性热度持续攀升,相关技术取得新突破
未来展望:降维算法会成为数字孪生的“标配”吗?
随着2026年更多企业试点降维算法,一个新问题逐渐浮现:这项技术会成为数字孪生的“标配”吗?从目前的趋势看,答案倾向于肯定,但需要时间。 2026年中学教育与碳捕捉热度持续攀升,相关应用不断深化
从技术层面看,降维算法的优势已经得到验证:它解决了传统方案“精度、资源、实时性”的三角困局,让数字孪生从“能用”变成“好用”,尤其是在资源受限的边缘设备(如工业网关、智能传感器)上,降维算法的轻量化特性使其更具部署价值,某物联网企业2026年推出的新一代工业网关,内置了降维算法模块,能在本地完成关键要素筛选和初步建模,只需将少量关键数据