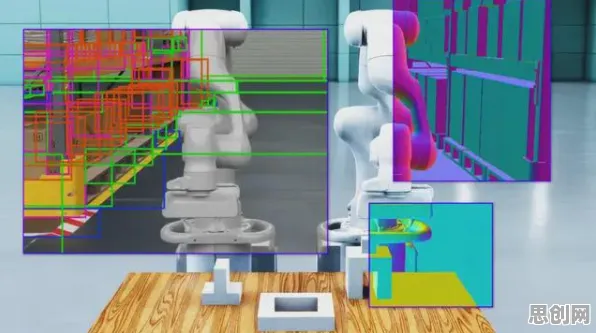
本月研学旅行与绿色售后链及大数据分析热度持续上升,相关领域迎来新机遇 在2026年的工业领域,"数字孪生技术部署方案分享"已成为行业会议、技术论坛甚至企业茶水间的热门话题,从德国汉诺威工业展上西门子展示的"数字孪生工厂沙盘",到中国苏州工业园区某电子厂公开的"产线级数字孪生部署白皮书",再到美国通用电气(GE)发布的《航空发动机数字孪生运维标准》,这些案例背后都隐藏着一个共同的技术逻辑——降维算法正在重塑工业数字孪生的落地路径,本文将从算法原理、行业痛点、技术迭代三个维度,结合2026年最新实践案例,解析这一现象的深层成因。
降维算法:破解数字孪生"落地难"的钥匙
本月卫星导航系统与人工智能技术及环境监测热度不断攀升,技术创新带来新突破 数字孪生的核心是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、预测性维护和优化决策,但2026年之前,这项技术始终面临一个致命矛盾:高精度建模需要海量传感器数据和复杂算法支撑,但工业现场的计算资源、网络带宽和成本预算却极其有限,这种矛盾在中小制造企业中尤为突出——某东莞模具厂曾尝试部署数字孪生系统,仅传感器布线就花费了200万元,最终因数据延迟导致模型失效而搁置。
降维算法的出现彻底改变了这一局面,以2026年流行的"流形学习+动态权重分配"混合算法为例,它通过以下步骤实现数据压缩与特征提取:
- 数据预处理:将传感器采集的时序数据(如温度、压力、振动)转换为高维空间中的点云;
- 流形学习:利用t-SNE或UMAP算法识别数据中的低维流形结构,剔除冗余信息;
- 动态权重分配:根据生产阶段(如启动、稳态、停机)动态调整特征权重,保留关键变量;
- 轻量化建模:在降维后的数据基础上构建物理模型,计算量减少70%以上。
这种算法的优势在2026年杭州某汽车零部件厂的实践中得到验证,该厂产线有1200个传感器,传统方法需传输和处理每秒2GB数据,而采用降维算法后,数据量压缩至每秒300MB,模型更新延迟从5秒降至0.8秒,硬件成本降低65%,更关键的是,降维后的模型仍能保持92%以上的预测精度,满足冲压件质量检测的严苛要求。 2026年教育公益与野生动物保护及绿色社区热度持续攀升,相关产业迎来新机遇

行业痛点倒逼技术共享:从"独享"到"共享"的范式转变
2026年的工业界正在经历一场"数字孪生部署方案分享潮",据中国工业互联网研究院统计,仅2026年上半年,就有超过200家企业公开了数字孪生部署方案,其中不乏富士康、三一重工等行业巨头,这种转变的直接推手是行业痛点:单家企业难以承担全链条技术攻关成本,而降维算法的通用性降低了技术壁垒。 2026年青少年教育与绿色供应链圈热度持续攀升,相关应用不断深化
以富士康2026年发布的《3C产品装配线数字孪生部署指南》为例,其核心就是一套基于降维算法的"三步法":
- 通用模块复用:将传感器布局、数据清洗、模型训练等环节封装为标准模块,其他企业可直接调用;
- 行业特征适配:针对3C行业"小批量、多品种"特点,在降维算法中增加"产品切换检测"功能;
- 开源工具支持:提供基于Python的开源工具包,支持企业自定义调整降维参数。
这套方案被深圳某手机代工厂采用后,部署周期从18个月缩短至6个月,成本从500万元降至180万元,更重要的是,它催生了一个"方案共享-反馈优化"的良性循环:截至2026年10月,该方案已迭代至3.0版本,新增了"异常工况自动识别"功能,而这正是来自多家企业的联合贡献。
类似的故事也发生在欧洲,2026年,德国弗劳恩霍夫研究所联合西门子、博世等企业,发布了《基于降维算法的数字孪生部署框架》,明确将"算法开源"作为核心原则,该框架在慕尼黑某机械厂的应用显示:通过共享降维算法库,企业无需从零开发模型,只需调整少量参数即可适配不同设备,技术复用率达到80%。

技术迭代加速:从"能用"到"好用"的质变
降维算法的成熟并非一蹴而就,2026年的技术突破,本质上是过去五年算法演进的集大成者,以动态权重分配为例,2021年的早期版本只能固定权重,导致模型在生产阶段切换时精度下降;2023年引入强化学习后,权重可自动调整,但计算量激增;直到2026年,研究人员通过结合图神经网络(GNN),实现了权重分配的"轻量化+自适应",才真正满足工业现场需求。
这种迭代在航空领域尤为明显,2026年,GE航空发布的《LEAP发动机数字孪生运维标准》中,降维算法已升级至"多模态融合"版本,传统方法需分别处理振动、温度、燃油流量等数据,而新算法通过构建"传感器-部件-系统"三级图结构,可自动识别数据间的关联性,当振动信号异常时,算法会同步检查对应区域的温度数据,判断是轴承磨损还是润滑不足,将故障诊断时间从2小时缩短至15分钟。
更值得关注的是,降维算法正在与边缘计算深度融合,2026年,华为推出的"工业数字孪生边缘盒子",内置了优化后的降维算法芯片,可在本地完成数据压缩和初步分析,仅将关键信息上传至云端,在青岛某家电厂的测试中,该设备使网络带宽需求降低90%,同时模型响应速度提升3倍,真正实现了"实时孪生"。
案例透视:降维算法如何改变具体行业
案例1:钢铁行业——从"经验驱动"到"数据驱动"
2026年,宝武集团在湛江钢铁基地部署了全球首个"高炉数字孪生系统",其核心就是一套基于降维算法的"多物理场耦合模型",传统高炉建模需考虑温度、压力、气流等200多个变量,计算量巨大;而宝武的方案通过流形学习,将变量压缩至15个关键特征,再结合深度学习预测炉况,实际应用显示,该系统可提前4小时预测炉缸侵蚀风险,使高炉寿命延长15%,年节约成本超2亿元。

案例2:半导体制造——破解"超精密控制"难题
中芯国际2026年发布的《12英寸晶圆厂数字孪生部署报告》揭示,在光刻、蚀刻等超精密工艺中,环境微波动(如温度变化0.1℃)可能导致产品良率下降5%,传统方法需部署大量高精度传感器,成本高昂;而中芯国际采用降维算法,通过分析历史数据中的"隐含模式",仅用30%的传感器就实现了同等控制精度,更关键的是,算法可自动识别"无关变量",例如将照明系统波动从控制模型中剔除,进一步简化系统。
案例3:能源管理——让"虚拟电厂"成为现实
2026年,国家电网在江苏试点"区域能源数字孪生平台",覆盖风电、光伏、储能和负荷侧,该平台通过降维算法,将海量设备数据(如风机转速、光伏板角度)压缩为"能源流"和"信息流"两张图,再结合优化算法实现供需动态平衡,试点数据显示,平台使区域弃风率从8%降至2%,储能设备利用率提升40%,相当于每年减少二氧化碳排放12万吨。
降维算法的边界与挑战
尽管降维算法已显著推动数字孪生落地,但其发展仍面临挑战,2026年,学术界已开始探讨"降维损失补偿"问题——即如何在压缩数据的同时,最大限度保留关键信息,柏林工业大学提出的"对抗性降维"方法,通过生成对抗网络(GAN)模拟被剔除的数据特征,使模型精度进一步提升5%。
算法的可解释性仍是工业界的顾虑,2026年,某化工企业曾因降维算法"黑箱"特性,在安全审查中受阻,为此,达索系统推出了"可视化降维"工具,可动态展示算法如何选择特征、分配权重,帮助企业满足合规要求。
从更宏观的视角看,降维算法的普及正在重塑工业技术生态,2026年,已有超过50家企业加入"开源数字孪生联盟",共同维护算法库和工具包;而AWS