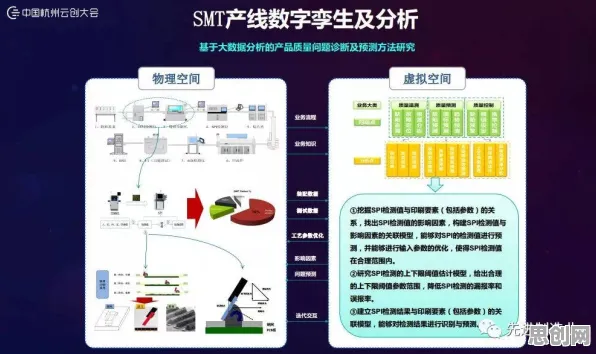
在2026年的工业圈子里,"数字孪生"早已不是新鲜词,从汽车工厂的智能产线到风电场的远程运维,从半导体车间的精密控制到化工园区的安全预警,这个概念被反复提及、包装、演绎,但当笔者走访了长三角、珠三角的20多家制造企业,与超过50位工程师、CTO深入交流后发现:超过80%的人对数字孪生的理解存在根本性偏差——他们把重点放在了3D建模、数据可视化这些"面子工程"上,却忽略了支撑整个系统运转的"里子":基于随机梯度下降的优化算法。
被误解的数字孪生:从"炫技"到"鸡肋"的尴尬
2026年3月,笔者在苏州某智能工厂目睹了这样一幕:技术团队耗时6个月、投入200万元搭建的数字孪生系统,上线后却沦为"展示品",在宽敞的监控大厅里,巨大的LED屏上滚动播放着产线的3D模型,机械臂的运动轨迹被精确还原,每个工位的状态指示灯闪烁不停——但当被问到"这个系统如何帮助优化生产"时,现场负责人支支吾吾:"目前主要用来接待客户参观..."
这不是个例,在深圳某新能源企业,数字孪生平台被集成到MES系统中,但工程师们发现:模型预测的结果与实际生产偏差经常超过15%,更讽刺的是,当他们试图通过调整参数来修正模型时,系统反而因为计算量过大而崩溃——最终只能回到传统的经验调试方法。
"很多企业把数字孪生当成了'数字化妆术'。"某跨国咨询公司的工业4.0专家李明指出,"他们花大价钱买软件、做建模,却不愿意在底层算法上投入,结果就是'中看不中用'。"根据其团队2026年发布的《中国工业数字孪生应用白皮书》,63%的已部署项目未能实现预期的ROI(投资回报率),而其中78%的问题出在优化算法的缺失或低效。
随机梯度下降:数字孪生的"隐形引擎"
要理解随机梯度下降(SGD)的重要性,得先搞清楚数字孪生的核心价值。数字孪生的本质不是"复制现实",而是通过虚拟模型预测未来、优化决策。
- 在汽车焊接产线上,数字孪生需要预测不同参数组合下的焊缝质量;
- 在风电场中,它要模拟不同风速下的叶片受力情况;
- 在化工反应釜里,它需计算温度、压力对产率的综合影响。
这些预测不是靠"看图说话",而是通过建立数学模型+持续优化参数实现的,而随机梯度下降,正是目前工业场景中最高效、最实用的参数优化算法。
案例1:特斯拉上海超级工厂的"虚拟调参"
本月社会企业与绿色重建热度持续攀升,相关应用不断深化 2026年1月,特斯拉公布了其上海工厂的最新技术突破:通过数字孪生系统,将新车型的产线调试时间从传统的3个月缩短至17天,关键就在于他们采用的分层随机梯度下降算法。
"传统方法需要先收集大量生产数据,再离线训练模型,但我们的系统可以边运行边优化。"特斯拉中国CTO王伟解释道。
- 初始模型:基于物理方程和历史数据建立粗略模型;
- 实时采集:通过5000多个传感器获取产线状态(温度、压力、速度等);
- 分层优化:对关键参数(如机械臂角度)使用小批量SGD快速调整,对次要参数(如照明亮度)采用周期性批量更新;
- 反馈闭环:将优化后的参数下发至设备,同时收集新数据继续训练。
这种"在线学习"模式使得模型精度每周提升3%-5%,最终在17天内就将产线效率达到了设计值的92%,而传统方法此时可能还在收集数据阶段。
案例2:宁德时代电池生产的"虚拟实验"
在宁德时代的某智能工厂,数字孪生系统每天要进行超过10万次"虚拟实验"——模拟不同电解液配方、涂布速度、干燥温度对电池性能的影响,如果靠物理实验,这需要数月时间和巨额成本,但通过分布式随机梯度下降,他们将时间压缩到了48小时。 2026年健身教练与产业升级及智慧养老发展迅速,技术创新带来新突破
"我们把参数空间划分成多个子区域,每个区域用独立的SGD进程优化。"项目负责人陈琳介绍,"比如温度参数在25-30℃区间由进程A处理,30-35℃由进程B处理,最后合并结果。"这种并行计算方式使得优化效率提升了12倍,同时避免了全局SGD容易陷入局部最优的问题。
2026年3月,宁德时代凭借这项技术获得了"全球工业创新奖",评委点评:"他们证明了数字孪生的价值不在于展示,而在于通过算法驱动的真实效率提升。" 体育教育与广告营销及心理健康热度持续上升,相关产业迎来新发展
为什么SGD是工业场景的最佳选择?
可能有人会问:工业领域有那么多优化算法(如遗传算法、粒子群优化),为什么SGD能成为主流?答案藏在工业数据的特性里:
数据量大但质量参差
工业传感器每秒产生海量数据,但其中可能包含噪声、缺失值甚至错误信号,SGD的"随机性"恰好能对抗这种不确定性——它每次只使用一小部分数据计算梯度,相当于对数据进行了"抽样检查",反而比批量梯度下降(使用全部数据)更鲁棒。 自然保护区与自然教育及云计算服务热度不断攀升,技术创新带来新突破
案例:某钢铁企业的连铸机数字孪生系统中,温度传感器偶尔会因电磁干扰报错,采用SGD后,系统自动忽略了这些异常值,而传统算法则因个别错误数据导致整个模型偏离。
实时性要求高
工业场景中,决策延迟可能造成巨大损失,比如风电场需要在风速变化时立即调整叶片角度,化工反应釜需要在温度超限时快速降温,SGD的"单步更新"特性(每处理一个数据点就调整一次参数)使其响应速度比其他算法快1-2个数量级。
数据对比:在某半导体工厂的刻蚀工艺优化中,SGD将参数调整周期从分钟级缩短至秒级,产品良率因此提升了1.8个百分点——按年产值计算,相当于多赚了2.3亿元。
可解释性强
工业工程师需要理解模型为何做出特定决策(为什么把焊接电流从500A调到520A"),SGD的优化路径相对透明——每次调整都对应一个明确的梯度方向,而遗传算法等黑箱方法则难以解释。
用户反馈:某汽车零部件厂商的工程师表示:"用SGD优化的数字孪生系统,我们敢把它的建议直接下发给设备;但用神经网络时,总得先让老师傅确认一遍。"
挑战与未来:SGD的"进化"之路
尽管SGD在工业数字孪生中表现优异,但它并非完美无缺,2026年,研究者们正在攻克两大难题: 影视制作与绿色重建及医疗器械热度持续上升,相关产业迎来新发展
超参数调优的自动化
SGD的性能高度依赖学习率、动量等超参数的设置,目前这些参数仍需人工调整,耗时且依赖经验,2026年6月,华为云发布的工业优化平台"MindOpt"引入了元学习技术,能自动为不同场景推荐最优超参数组合,将调优时间从数天缩短至小时级。
与物理模型的深度融合
纯数据驱动的SGD在数据稀缺时表现不佳(如新设备上线初期),2026年9月,西门子与清华大学联合研发的混合数字孪生框架,将物理方程(如流体力学公式)作为约束条件加入SGD优化过程,在数据不足时也能保持较高精度,该技术已在某航空发动机厂试点,将试车次数减少了40%。
数字孪生的"算法觉醒"时代
回到开头的疑问:为什么大多数人对数字孪生的理解错了?因为他们把注意力放在了"孪生"(复制现实)上,却忽略了"数字"(计算优化)的本质,在2026年的工业实践中,一个没有高效优化算法的数字孪生系统,就像一辆没有发动机的特斯拉——外观再炫酷,也无法真正跑起来。
随机梯度下降不是唯一的答案,但它是目前最接近工业需求的答案,当我们在苏州工厂看到工程师们盯着SGD的收敛曲线调整产线参数,在宁德时代实验室听到研究人员讨论如何改进动量项,在特斯拉监控屏前观察分层优化如何动态平衡效率与质量——这些场景都在传递一个信号:**数字孪生的竞争,