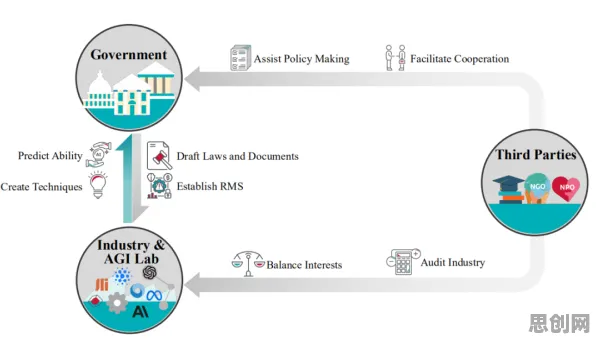
从“物理实体”到“数字镜像”:机器学习如何构建精准模型
2026年绿色街区与内容审核及绿色能源网热度不断攀升,技术创新带来新突破 数字孪生的核心是“虚实映射”,即通过传感器采集物理实体的运行数据,在虚拟空间中构建一个与之完全对应的数字模型,但这个模型不是简单的“复制粘贴”,而是需要机器学习算法对海量数据进行深度挖掘,才能实现动态、精准的映射。
以德国西门子的安贝格电子制造工厂为例,这座被誉为“全球最智能的工厂”早在2023年就全面应用了数字孪生技术,工厂内每台设备都安装了数百个传感器,实时采集温度、压力、振动等数据,但最初,西门子的工程师们发现,单纯依靠物理公式建立的模型无法准确预测设备故障——因为工业环境复杂多变,传统模型难以覆盖所有变量。
他们引入了机器学习中的“时间序列预测”算法,通过分析过去5年的设备运行数据,算法自动识别出哪些数据特征(如特定频率的振动、温度波动模式)与设备故障高度相关,他们发现当某台注塑机的液压系统压力在30秒内波动超过15%时,未来24小时内发生泄漏的概率高达87%,基于这一发现,西门子重新构建了数字孪生模型,将机器学习预测结果作为关键输入参数,结果如何?2025年工厂年报显示,设备意外停机时间减少了62%,生产效率提升了28%。
这个案例揭示了一个关键点:数字孪生的“精准”不是靠人工设定规则,而是靠机器学习从数据中“学习”出隐藏的规律,正如西门子数字化工业集团CTO彼得·科特勒在2026年汉诺威工业展上所说:“我们不再试图用物理公式描述所有工业现象,而是让数据自己说话。”
从“被动监测”到“主动优化”:机器学习如何驱动闭环控制
数字孪生的价值不仅在于“镜像”物理世界,更在于通过虚拟模型反哺现实生产,这需要机器学习算法具备“闭环控制”能力——即根据数字模型的预测结果,自动调整物理实体的运行参数。
中国海尔的互联工厂提供了一个典型案例,在海尔沈阳冰箱工厂的钣金生产线上,传统工艺需要人工根据板材厚度调整冲压机的压力和速度,效率低且容易出错,2024年,海尔引入了数字孪生系统,通过安装在冲压机上的传感器实时采集板材厚度、材料硬度等数据,并传输到数字模型中。

但仅仅“监测”还不够,海尔的工程师们与清华大学合作,开发了一套基于“强化学习”的闭环控制算法,算法会先在数字模型中模拟不同压力和速度组合下的冲压效果(如成型质量、能耗),然后根据预设目标(如最小化能耗同时保证质量)自动选择最优参数,更厉害的是,算法会持续“学习”——每次生产后,它会根据实际结果(如冲压后的板材是否合格)调整模型参数,逐步优化控制策略。
2026年3月,海尔发布的《智能制造白皮书》显示,应用该系统后,钣金生产线的能耗降低了19%,产品不良率从0.8%降至0.3%,而人工干预次数几乎为零,这一案例说明,机器学习不仅能让数字孪生“看得准”,还能让它“干得好”——通过闭环控制实现生产过程的自主优化。
从“单台设备”到“整个产线”:机器学习如何处理复杂系统
工业生产中,单台设备的优化只是第一步,真正的挑战在于如何协调多台设备、多个环节的运行,这需要机器学习算法具备处理“复杂系统”的能力——即同时考虑多个变量的相互作用,找到全局最优解。
清洁能源与野生动物保护及新能源汽车热度持续上升,相关产业迎来新发展 日本丰田的元町工厂提供了一个绝佳案例,这座工厂以生产高端车型为主,产线涉及冲压、焊接、涂装、总装等多个环节,各环节之间存在严格的时序约束(如焊接必须在冲压完成后2小时内进行,否则板材会变形),2025年,丰田引入了基于数字孪生的“智能产线调度系统”,试图解决传统调度依赖人工经验、效率低下的问题。
2026年绿色水处理与健身教练热度持续攀升,相关应用不断深化 
但问题来了:产线调度涉及数十台设备、上百个工序、数千种约束条件,传统优化算法(如线性规划)根本无法在合理时间内求解,丰田与东京大学合作,开发了一套基于“图神经网络”(GNN)的调度算法,GNN的优势在于能处理“图结构”数据——在产线调度中,每台设备是一个“节点”,设备之间的依赖关系是“边”,GNN可以自动学习这些节点和边的特征,预测不同调度方案对整体效率的影响。
算法发现如果将某台焊接机器人的工作时间从白天调整到夜间,虽然会增加少量能耗,但能避免与冲压机的“资源冲突”,使整条产线的吞吐量提升12%,更关键的是,GNN模型可以实时更新——每当有新订单加入或设备故障时,算法会在几分钟内重新计算最优调度方案,而传统方法可能需要数小时。
2026年第一季度,丰田元町工厂的产线利用率从78%提升至91%,订单交付周期缩短了22%,这一案例证明,机器学习不仅能优化单台设备,还能通过处理复杂系统关系,实现产线级的智能调度。
从“事后维修”到“预测性维护”:机器学习如何延长设备寿命
工业设备的维护是另一个关键场景,传统维护是“事后维修”(设备坏了才修)或“定期维护”(按固定周期检修),前者会导致意外停机,后者则造成过度维护,数字孪生技术结合机器学习,正在推动“预测性维护”的普及——即提前预测设备故障,在最佳时间进行维护。

美国通用电气(GE)的航空发动机业务是这一领域的先行者,GE的LEAP系列发动机广泛应用于波音737MAX和空客A320neo等机型,每台发动机价值数千万美元,任何非计划停机都会造成巨大损失,2024年,GE为LEAP发动机部署了数字孪生系统,通过安装在发动机上的200多个传感器,实时采集温度、压力、振动等数据。
但数据多不等于价值大,GE的工程师们与MIT合作,开发了一套基于“异常检测”的机器学习模型,模型先学习发动机在正常状态下的数据分布(如振动频率的波动范围),然后持续监测实时数据,一旦发现数据偏离正常范围(如某区域振动频率突然升高),就触发预警,更复杂的是,模型还能区分“假阳性”(如短暂的气流扰动导致的异常)和“真故障”(如涡轮叶片裂纹导致的异常),减少误报。
2026年2月,GE发布的《航空发动机健康管理报告》显示,应用该系统后,LEAP发动机的非计划停机次数减少了54%,维护成本降低了31%,更值得一提的是,模型还能预测故障的“剩余寿命”——当检测到某涡轮叶片有裂纹时,模型会根据裂纹扩展速度预测叶片还能安全运行多少小时,从而帮助航空公司安排最经济的维护时间。
这一案例说明,机器学习不仅能让数字孪生“发现故障”,还能“预测故障”,将维护从“被动响应”变为“主动规划”。
从“企业内部”到“供应链协同”:机器学习如何打破数据孤岛
数字孪生的最终目标是实现全产业链的协同优化,但这需要打破企业之间的“数据孤岛”——毕竟,供应商的设备数据、物流企业的运输数据、客户的订单数据往往分散在不同系统中,机器学习中的“联邦学习”技术,正在为这一难题提供解决方案。
中国中车的“高铁数字孪生供应链”项目是一个典型案例,中车作为全球最大的高铁制造商,其供应链涉及数千家供应商,从原材料(如铝合金)到零部件(如轴承、齿轮),任何环节的延迟都会影响整车交付,2025年,中车联合华为、阿里云等企业,启动了基于数字孪生的供应链协同项目,试图实现从原材料采购到整车交付的全链条可视化。
2026年聚焦废物利用与压力缓解及量子计算新趋势,应用场景不断拓展 但问题来了:供应商的数据涉及商业机密(如成本、工艺参数),不可能直接共享给中车;不同供应商的数据格式、采集频率差异很大,难以直接整合,中车采用了“联邦学习”技术——各供应商在自己的本地服务器上训练机器学习模型(如预测零部件交付时间的模型),然后将模型参数(而非原始数据)上传到中车的中央服务器,中央服务器通过聚合这些参数,构建一个全局模型,用于预测