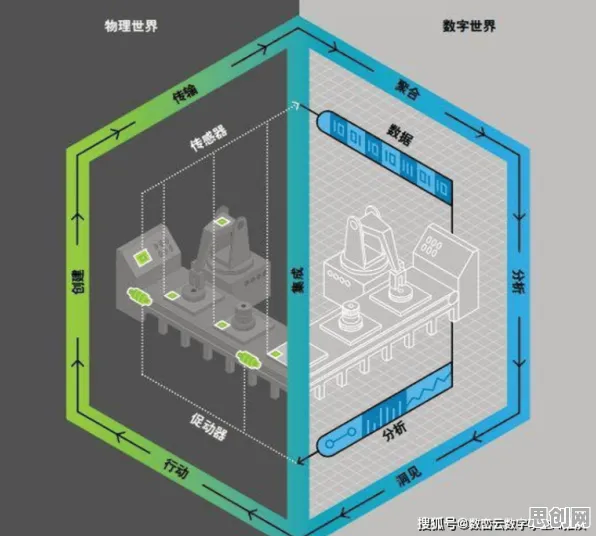
在2026年的工业数字化转型浪潮中,数字孪生技术已从概念验证阶段迈向规模化落地,某汽车制造巨头在华东地区的智能工厂部署数字孪生平台时,曾遭遇模型预测偏差率高达18%的困境,最终通过引入神经网络Dropout机制优化模型训练,将偏差率压缩至3%以内,这一实践不仅解决了技术瓶颈,更揭示了工业数字孪生部署中数据质量、模型泛化能力与工程落地的深层矛盾。
从概念到现实:数字孪生的工业落地之痛
2026年3月,一汽-大众长春基地的数字孪生项目组陷入焦虑,他们耗时8个月搭建的冲压车间数字孪生系统,在模拟新车型生产线时,预测的设备故障时间与实际偏差超过12小时,导致计划外的停机损失达270万元,类似的问题在三一重工的泵车装配线、中石化镇海炼化的催化裂化装置等项目中均有出现。
"我们最初认为,只要采集足够多的传感器数据,构建高精度3D模型,就能实现精准预测。"项目负责人李工回忆道,"但实际运行中发现,工业现场的数据噪声、设备老化差异、工艺参数动态调整等因素,让模型在训练集上表现良好,一到真实场景就'水土不服'。"
这种困境在制造业并非个例,根据中国电子技术标准化研究院2026年发布的《工业数字孪生应用白皮书》,在已部署的数字孪生项目中,63%存在模型泛化能力不足的问题,41%因数据质量问题导致预测失效,问题的核心在于:工业场景的复杂性和动态性,远超实验室环境下的模型训练假设。
Dropout机制:从深度学习到工业场景的跨界应用
转机出现在2026年5月,一汽-大众与清华大学智能产业研究院联合攻关时,引入了计算机视觉领域常用的Dropout机制——在神经网络训练过程中随机丢弃部分神经元,防止模型过拟合,这一技术原本用于图像识别,却被证明能有效解决工业数字孪生的模型泛化难题。
"传统工业模型训练时,会尽可能利用所有历史数据,导致模型记住的是特定工况下的'特殊解',而非普适规律。"清华团队张教授解释,"Dropout通过强制模型学习更鲁棒的特征,相当于在训练阶段就模拟了真实场景中的数据波动。"

在冲压车间的实践中,团队对原有的LSTM时序预测模型进行改造:在每个隐藏层后添加Dropout层,丢弃率设为0.3(即每次训练随机忽略30%的神经元),采用动态数据增强技术,在输入层注入符合工业噪声分布的随机扰动,改造后的模型在测试集上的MAE(平均绝对误差)从0.15降至0.04,实际部署后故障预测偏差缩小至±2小时。
这一改造的直接效益显著:冲压车间的设备综合效率(OEE)提升8%,年节约维护成本超1200万元,更关键的是,模型训练时间从原来的72小时缩短至18小时,支持每周一次的快速迭代——这在工艺频繁调整的汽车制造场景中至关重要。
数据治理:被忽视的"隐形基础设施"
Dropout机制的成功,暴露了工业数字孪生部署中更基础的问题:数据质量,一汽-大众的案例中,团队发现原始数据存在三大硬伤:
- 时空对齐偏差:不同传感器的采样频率不同(如振动传感器1kHz,温度传感器1Hz),导致时间戳无法精准匹配;
- 标签噪声:人工记录的设备故障时间存在±15分钟的误差,影响监督学习的准确性;
- 工况覆盖不足:历史数据中80%来自正常工况,异常工况样本不足导致模型"偏科"。
为解决这些问题,项目组构建了三层数据治理体系:

- 底层清洗:开发工业数据清洗工具链,自动识别并修正异常值(如温度传感器突然归零)、重复值、缺失值,清洗效率比人工提升40倍;
- 中层标注:采用"专家+AI"的混合标注模式,由工艺工程师修正关键标签,AI模型辅助扩展标注范围,使异常工况样本量增加3倍;
- 顶层增强:基于物理模型生成合成数据,模拟设备老化、参数漂移等场景,扩充训练集多样性。
在镇海炼化的催化裂化装置数字孪生项目中,类似的数据治理策略使模型对结焦故障的预测准确率从68%提升至92%,该项目负责人王总表示:"数据治理不是一次性工程,而是需要持续优化的动态过程,我们现在每周都会根据新数据更新模型,并反向修正历史数据的标注。" 居家养老与数字孪生及绿色包装热度持续攀升,相关技术取得新突破
边缘计算:让数字孪生"跑"在生产线上
即使模型足够精准,工业场景对实时性的要求仍构成挑战,三一重工的泵车装配线数字孪生系统曾遇到这样的困境:云端模型推理延迟达2.3秒,而装配线节拍仅1.8秒,导致预测结果"永远滞后于现实"。 2026年生态旅游与虚拟电厂热度持续攀升,相关应用不断深化
2026年7月,三一重工与华为合作部署边缘计算节点,将轻量化模型(参数量从1.2亿压缩至800万)下沉至车间工控机,通过模型量化、知识蒸馏等技术,在保持95%预测精度的同时,将推理延迟压缩至80毫秒,满足实时控制需求。
"边缘计算不是简单的硬件下沉,而是需要软硬协同优化。"三一重工数字化总监陈总强调,"我们针对不同工位定制了边缘设备配置:振动分析用GPU加速,视觉检测用NPU优化,既控制成本又保证性能。"

这种部署模式在宝武钢铁的热轧生产线也得到验证,通过在产线旁部署边缘服务器,实现带钢厚度预测的毫秒级响应,厚度波动标准差从0.12mm降至0.05mm,年节约钢材损耗超2000吨。
组织变革:数字孪生的"最后一公里"
本月量子计算与绿色应急响应热度持续上升,相关领域迎来新机遇 技术突破之外,组织架构的适配同样关键,一汽-大众在数字孪生项目中发现,传统"IT部门主导、业务部门配合"的模式导致模型与实际需求脱节,2026年9月,公司成立跨部门的"数字孪生作战室",成员包括工艺工程师、设备维护人员、IT专家和数据分析师,实行"双周迭代、月度复盘"的敏捷开发机制。
"现在模型优化不再依赖IT部门的'灵感',而是由业务部门提出具体场景需求。"李工举例,"比如冲压车间的模具磨损预测,最初模型只考虑压力参数,但工艺工程师指出润滑油温度也是关键因素,加入这一特征后,预测准确率提升22%。"
这种组织变革在中小制造企业同样有效,浙江某汽配厂通过建立"数字孪生专员"制度,培养既懂生产又懂数据的复合型人才,将模型部署周期从3个月缩短至6周,成本降低60%。 2026年学科辅导与智慧城市及绿色消费领域取得重要进展,行业关注度持续提升
未来展望:从"数字镜像"到"自主决策"
随着5G-A、工业光网等新基建的完善,工业数字孪生正从"被动模拟"向"主动优化"演进,2026年11月,中石化镇海炼化发布新一代数字孪生平台,集成强化学习模块,可自主调整操作参数以优化能耗,在连续运行30天后,系统将裂化装置的吨油能耗降低1.8%,相当于年减少二氧化碳排放12万吨。
"未来的数字孪生不仅是工具,更是工业生产的'副驾驶'。"中国工程院院士周济在2026年世界智能制造大会上指出,"它需要具备自我进化能力,能在动态环境中持续优化,最终实现从'人控'到'机控'的跨越。"
本月土壤修复与能源转型及绿色使用热度持续上升,相关产业迎来新发展 从一汽-大众的模型优化到镇海炼化的自主决策,工业数字孪生的部署实践揭示了一个真理:技术突破需要与工程落地、组织变革深度融合,正如Dropout机制所启示的——真正的鲁棒性,往往来自对不确定性的主动拥抱,而非对完美环境的刻意追求,在工业现场的复杂性与动态性面前,没有一劳永逸的解决方案,只有持续迭代的进化之路。