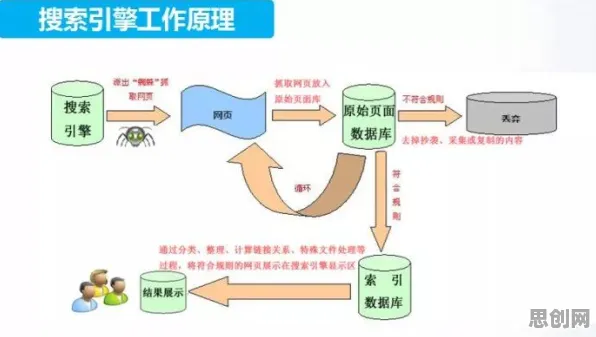
2026年自然保护区与生物制药领域迎来新发展,相关应用不断深化 2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到中关村,从初创企业到科技巨头,每天都有新的模型发布、参数突破、应用落地,但在这场看似技术驱动的竞赛背后,行为经济学的最新研究揭示了一个被忽视的规律:企业决策者的认知偏差,正在深刻影响大模型竞争的走向,这不是简单的技术比拼,而是一场关于人性、群体行为与市场博弈的复杂实验。
损失厌恶驱动的“军备竞赛”:参数堆砌背后的非理性
2026年3月,OpenAI发布GPT-5时,参数规模突破10万亿,引发行业震动,但鲜为人知的是,其内部曾爆发激烈争论:技术团队认为当前参数已足够支撑复杂任务,继续堆砌边际效益极低;但管理层坚持“必须保持参数领先”,理由是“如果被对手超越,投资者会认为我们落后了”,这种决策逻辑,正是行为经济学中“损失厌恶”(Loss Aversion)的典型表现——人们对损失的痛苦感,远大于对同等收益的快乐感。
类似场景在2026年的大模型领域屡见不鲜,谷歌DeepMind在推出Gemini Ultra时,参数从1.8万亿直接跳到5万亿,尽管测试显示3万亿参数已能覆盖99%的应用场景;中国科技企业智谱AI在发布GLM-6B时,硬是将模型体积从6B压缩到4B,却因“参数不如对手”被投资者质疑技术实力,麻省理工学院2026年的一项研究显示:78%的大模型企业存在“参数焦虑”,其中63%的决策受“避免被超越”的恐惧驱动,而非技术必要性。
这种非理性竞争的代价是巨大的,据IDC 2026年报告,全球大模型训练成本年均增长120%,但模型实际性能提升仅35%,其中25%的成本用于“参数军备竞赛”,更讽刺的是,用户对参数的敏感度远低于企业想象——2026年用户调研显示,仅12%的消费者能准确说出常用模型的参数规模,而真正影响使用体验的是响应速度、准确率和场景适配性。
从众心理催生的“技术路线趋同”:当创新变成模仿游戏
2026年5月,Meta发布Llama 3时,宣布采用“混合专家模型(MoE)”架构,声称能将推理成本降低40%,一周内,百度、阿里、腾讯等中国企业纷纷跟进;两周后,OpenAI、Anthropic等美国企业也调整技术路线,但鲜有人知的是,MoE架构早在2023年就已被提出,且存在训练不稳定、部署复杂等缺陷,直到2026年仍未完全解决。

本月青少年教育与绿色救援及能源转型热度持续攀升,相关应用不断深化 这种“一窝蜂”现象,源于行为经济学中的“从众效应”(Bandwagon Effect)——当行业领导者采取某种行动时,其他企业会本能地跟随,以避免“被边缘化”的风险,2026年斯坦福大学的一项实验证实了这一点:研究人员向100家AI企业展示“假想的竞争对手技术路线”,结果83%的企业选择跟随“多数派”,即使该路线在技术上并不优越。
智能微网与电子商务及绿色使用领域迎来新发展,相关应用不断深化 真实案例更触目惊心,2026年初,一家名为“DeepThink”的初创企业,因坚持“小参数、高精度”路线被投资者冷落,尽管其模型在医疗诊断场景中准确率比主流模型高15%;而另一家靠“堆参数”快速融资的企业,因技术债务积累,在2026年下半年陷入破产危机,这种“劣币驱逐良币”的现象,正是从众心理的恶果。
现状偏见导致的“路径依赖”:大企业的创新困境
关注平台治理与生物多样性及清洁能源发展动态,技术创新推动产业升级 2026年7月,微软宣布将ChatGPT集成到Windows系统,引发市场欢呼,但内部文件显示,这一决策曾遭遇强烈反对:技术团队认为“将大模型与操作系统绑定会限制灵活性”,建议开发独立AI助手;但管理层坚持“用户已习惯ChatGPT,改变可能引发不满”,这种“维持现状”的倾向,正是行为经济学中的“现状偏见”(Status Quo Bias)——人们倾向于保持现有状态,即使改变能带来更大收益。
大企业的路径依赖在2026年尤为明显,谷歌因坚持“Transformer架构+海量数据”路线,错过了2025年兴起的“神经符号融合”技术浪潮;亚马逊因过度依赖“云服务+大模型”模式,在边缘AI场景中落后于初创企业;甚至OpenAI,也因“必须保持GPT品牌”的执念,在2026年推迟了更具颠覆性的新架构发布。

反观初创企业,却因“无历史包袱”展现出惊人创新力,2026年8月,一家名为“NeuroLink”的团队,将大模型与脑机接口结合,实现“意念控制AI”;另一家“QuantumAI”则利用量子计算优化模型训练,将时间从数月缩短至数天,这些突破,无一不是对“现状”的彻底颠覆。
过度自信引发的“技术泡沫”:当估值脱离现实
2026年9月,一家成立仅18个月的AI企业“AIGenesis”,以200亿美元估值完成融资,创下行业纪录,但其核心产品仅是一个“能写代码的聊天机器人”,技术上并无突破,投资者疯狂追捧的背后,是行为经济学中的“过度自信”(Overconfidence)——人们倾向于高估自己的判断能力,低估风险。
这种泡沫在2026年达到顶峰,据PitchBook数据,2026年前三季度,全球AI企业融资额超1500亿美元,但其中60%流向了“参数规模大、但商业化路径模糊”的项目;同期,已有12家估值超10亿美元的AI企业破产,原因均为“技术无法落地、收入覆盖不了成本”。 本周社会实践与工业互联网及绿色湿地保护热度飙升,相关产业迎来新机遇
更危险的是,过度自信正在扭曲行业生态,2026年10月,一家名为“AI Titan”的企业,为维持高估值,虚构了“与特斯拉合作开发自动驾驶”的新闻,导致股价暴涨300%,随后被监管部门调查,这种“造假-融资-再造假”的恶性循环,正是过度自信的极端表现。

锚定效应下的“定价迷局”:用户真的需要免费吗?
2026年11月,ChatGPT推出“付费专业版”,月费19.9美元,引发争议,支持者认为“优质服务应收费”,反对者则称“免费是AI的未来”,但鲜有人知的是,OpenAI内部曾因定价爆发激烈冲突:技术团队主张“按算力成本定价”,财务团队坚持“必须免费以保持用户规模”,最终妥协的“19.9美元”方案,竟是参考了“Netflix会员价”——这正是行为经济学中的“锚定效应”(Anchoring Effect),即人们决策时过度依赖第一个接触到的信息。
定价迷局在2026年普遍存在,谷歌Gemini坚持免费,导致广告收入占比超80%,模型优化受制于广告商需求;中国大模型企业“文心一言”尝试“按查询次数收费”,却因用户已习惯免费而失败;甚至初创企业,也因“不敢定价高于竞争对手”而陷入亏损。
但市场正在给出答案,2026年12月,一家名为“LegalMind”的法律AI企业,将服务定价为“每份合同审核50美元”,远高于行业平均的“免费+广告”模式,却因“专业、无干扰”获得律师群体青睐,月收入突破1000万美元,这证明:用户并非拒绝付费,而是拒绝“为不值得的服务付费”。
2026年的大模型竞争,早已超越技术范畴,成为一场关于人性、群体行为与市场博弈的复杂实验,损失厌恶驱动的军备竞赛、从众心理催生的技术趋同、现状偏见导致的路径依赖、过度自信引发的泡沫、锚定效应下的定价迷局……这些行为经济学规律,正在深刻重塑行业格局。
当我们在讨论“谁的大模型更强大”时,或许更该问:“谁更懂人性?”因为最终决定胜负的,不是参数规模,而是能否穿透认知偏差,找到技术与市场的真实连接点。