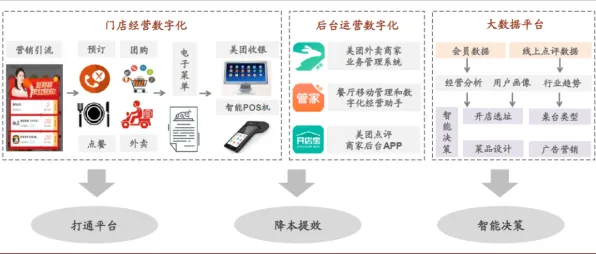
技术架构:从“单点模拟”到“全要素映射”的跨越
工业数字孪生的核心是构建物理实体与虚拟模型的实时交互闭环,但2026年的实践表明,传统“设备级孪生”已无法满足复杂生产系统的需求,以某汽车制造企业为例,其2026年上线的“智能工厂数字孪生平台”覆盖了从冲压、焊接、涂装到总装的完整产线,通过集成5G、物联网(IoT)和边缘计算技术,实现了对2000+台设备、50+个生产环节的毫秒级数据同步。
数字孪生与健身教练热度持续上升,相关产业迎来新机遇 该平台的技术架构分为三层:
- 数据采集层:通过部署在设备上的传感器和工业网关,实时采集温度、压力、振动等100+类物理参数,同时接入ERP、MES等业务系统数据,形成“物理+业务”的双流数据池。
- 模型构建层:基于机器学习算法(如LSTM时序预测、图神经网络GNN),构建设备健康度模型、工艺参数优化模型和产线瓶颈预测模型,通过分析焊接机器人3年的历史数据,模型可提前48小时预测电极头磨损,将停机时间减少60%。
- 应用服务层:将模型输出与AR/VR、数字看板等工具结合,为操作人员提供实时决策支持,当涂装车间湿度超标时,系统不仅会触发报警,还能通过数字孪生模型模拟不同通风策略的效果,推荐最优调整方案。
这一架构的关键突破在于“全要素映射”——不仅模拟设备状态,还整合了人员、物料、环境等动态因素,使虚拟模型能更真实地反映物理世界的复杂性。
数据治理:从“数据孤岛”到“高质量燃料”的蜕变
机器学习的性能高度依赖数据质量,但工业场景的数据往往存在“多源异构、噪声干扰、标签缺失”等问题,2026年,某钢铁企业的实践为行业提供了参考:其通过部署“工业数据中台”,将分散在30+个系统的数据统一清洗、标注和存储,构建了包含10万+标签的“钢铁生产知识图谱”。
具体措施包括: 2026年生态旅游与碳捕捉及教育公益热度持续攀升,相关应用不断深化
- 动态标签体系:针对不同生产阶段(如炼铁、炼钢、轧制)定义差异化标签,高炉炉温波动率”“连铸坯表面缺陷类型”,并通过机器学习自动补充缺失标签。
- 噪声过滤算法:采用基于注意力机制的深度学习模型,识别并剔除传感器异常数据,在轧机厚度检测中,模型可区分“真实厚度偏差”与“传感器抖动”,将数据准确率提升至99.2%。
- 数据增强技术:对小样本场景(如新设备调试)使用GAN生成合成数据,扩大训练集规模,某半导体企业通过此方法,将新设备模型训练周期从3个月缩短至2周。
本月数字经济与碳排放及碳捕捉热度持续攀升,相关应用不断深化 该企业数据中台负责人表示:“过去我们花70%的时间在数据清洗上,现在通过自动化工具和机器学习辅助,数据准备效率提升了4倍,模型迭代速度加快了一倍。”
模型优化:从“黑箱决策”到“可解释AI”的突破
工业场景对模型的可解释性要求极高——操作人员需要理解“为什么系统建议调整参数”,而非简单接受“是或否”的结论,2026年,某化工企业的实践展示了“可解释数字孪生”的落地路径。
营养膳食与碳利用热度持续上升,相关产业迎来新机遇 该企业部署的“反应釜数字孪生系统”集成了XGBoost和SHAP(Shapley Additive exPlanations)算法,可同时输出预测结果和特征贡献度,当模型预测某批次产品收率将低于90%时,系统会显示:“温度波动(贡献度35%)、催化剂浓度(贡献度28%)、搅拌速度(贡献度20%)是主要影响因素”,并推荐“将温度稳定在185±2℃、催化剂浓度提升至2.5%”等具体措施。
该企业还开发了“模型健康度监测”功能,通过持续跟踪预测误差、特征分布漂移等指标,自动触发模型再训练,2026年一季度,系统共检测到12次模型性能下降,其中8次由原料成分变化导致,2次由设备老化引起,均通过及时调整避免了生产事故。

场景落地:从“试点验证”到“规模化复制”的加速
2026年,数字孪生在工业领域的应用已从“单点试点”转向“场景化复制”,机器学习在其中扮演了“连接器”角色,以某光伏企业为例,其通过构建“硅片生产数字孪生平台”,实现了从拉晶、切片到电池片制造的全流程优化。 2026年数字鸿沟与绿色产品链及体育赛事热度持续上升,相关产业迎来新发展
关键场景包括:
- 拉晶环节:基于机器学习模型预测单晶硅棒的直径偏差,动态调整热场温度和拉速,将直径合格率从92%提升至97%。
- 切片环节:通过数字孪生模拟不同切割参数(如线速、张力)下的硅片厚度分布,结合强化学习算法寻找最优组合,使硅片厚度波动从±3μm降至±1.5μm。
- 电池片制造:利用计算机视觉(CV)模型检测隐裂、色差等缺陷,并通过数字孪生追溯缺陷根源(如切片参数异常或清洗工艺问题),推动全链条改进。
该企业CTO透露:“过去我们需要在每个工厂单独部署数字孪生系统,现在通过‘模型工厂’模式,将通用模型封装为标准化服务,新工厂只需接入数据即可快速复用,部署周期从6个月缩短至2周。”
安全保障:从“被动防御”到“主动免疫”的升级
工业数字孪生的安全风险不仅来自网络攻击,还涉及模型篡改、数据泄露等新型威胁,2026年,某能源企业的实践为行业提供了“主动免疫”方案。
该企业构建的“数字孪生安全防护体系”包含三层防御:

- 数据层:采用同态加密技术,允许模型在加密数据上直接训练和推理,避免原始数据泄露,在风电场功率预测场景中,第三方服务商只能获取加密后的风速、功率数据,无法反推原始信息。
- 模型层:部署“模型水印”和“异常检测”模块,实时监测模型是否被篡改,2026年3月,系统检测到某风电场功率预测模型输出异常,经溯源发现是黑客试图注入恶意数据,因水印验证失败而被拦截。
- 网络层:通过零信任架构(ZTA)限制设备访问权限,结合区块链技术记录所有数据操作日志,当某台传感器尝试访问非授权数据时,系统会立即触发告警并切断连接。
该企业安全负责人表示:“安全不是事后补救,而是需要嵌入数字孪生的每个环节,我们的目标是让系统像人体免疫系统一样,能自动识别并清除威胁。”
机器学习的五大重要发现
在工业数字孪生的部署过程中,机器学习不仅推动了技术演进,还催生了五大重要发现:
发现1:小样本学习在工业场景中更具优势
传统机器学习依赖大规模标注数据,但工业场景中,设备故障、工艺异常等关键事件往往是“小样本”,2026年,某航空发动机企业通过元学习(Meta-Learning)技术,仅用50个故障样本就训练出高精度预测模型,相比传统方法数据需求减少90%。
发现2:多模态融合是提升模型鲁棒性的关键
工业数据包含时序信号(如振动)、图像(如产品表面)、文本(如操作日志)等多模态信息,某电子制造企业的实践表明,融合多模态数据的模型(如结合CV和时序分析)比单模态模型准确率高25%,且对噪声干扰的抵抗力更强。
发现3:联邦学习可破解数据孤岛难题
不同企业、不同工厂的数据往往因隐私或竞争关系无法共享,2026年,某汽车零部件供应商通过联邦学习框架,联合3家合作伙伴训练出跨企业的设备故障预测模型,各方数据均不出本地,模型性能却比单方训练提升40%。
**发现4:强化学习是优化动态系统的利器