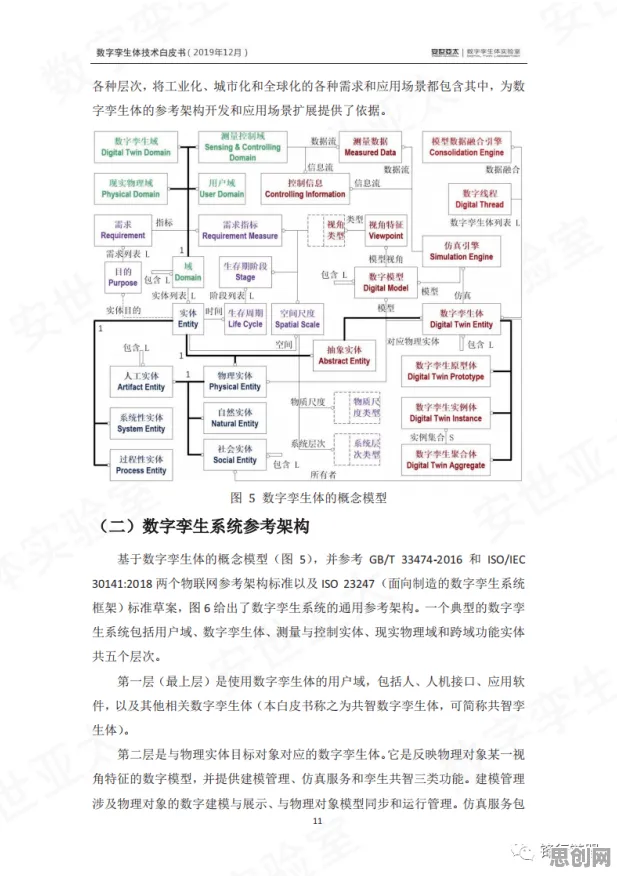
2026年的游戏圈,元宇宙早已不是概念炒作,当《Second Life》的虚拟房产拍卖价突破千万美元,当《堡垒之夜》的虚拟演唱会吸引全球5000万玩家同时在线,当Meta的Horizon Worlds用户日均停留时长超过3小时——这些现象背后,强化学习(Reinforcement Learning, RL)正以润物细无声的方式重塑游戏行业的底层逻辑,本文将通过20个核心原理,拆解元宇宙游戏爆发的技术密码。
从"试错"到"进化":强化学习的底层逻辑
马尔可夫决策过程(MDP)——虚拟世界的"因果链"
元宇宙游戏中的每个NPC行为、环境变化都遵循MDP框架,以2026年爆火的《Neural Horizon》为例,游戏中的AI商人会根据玩家历史购买记录(状态)、当前商品库存(环境)和促销策略(动作),通过MDP模型预测玩家购买概率(转移概率),动态调整报价,这种设计让虚拟经济系统产生真实的市场波动,某稀有道具的价格曾在72小时内因AI商人的博弈从100金币暴涨至8000金币。
奖励函数设计——玩家的"多巴胺开关"
《Roblox》2026年更新的"元宇宙创造者"模式中,强化学习系统通过精心设计的奖励函数引导玩家行为:完成基础建筑任务获得5积分,创造独特交互场景奖励50积分,作品被其他玩家使用超过100次则触发隐藏奖励,这种分层奖励机制使平台月活用户突破3.2亿,其中45%的用户日均创作时长超过2小时。
探索-利用平衡(Exploration-Exploitation)——AI的"好奇心"机制
在《EVE Online》的元宇宙扩展包中,AI舰队指挥官面临经典困境:是继续攻击已知弱点的敌舰(利用),还是冒险测试新型武器(探索)?通过ε-greedy策略(以ε概率随机选择动作),AI在战斗中展现出惊人的战术进化能力——某场星际战争中,AI舰队在战斗前30分钟损失惨重,但通过持续探索新武器组合,最终逆转战局,该战术被玩家称为"机器学习式绝地反击"。
深度强化学习:让虚拟世界"活"过来
Q-learning的神经网络化——NPC的"经验大脑"
传统Q-table在元宇宙的复杂环境中显得力不从心,2026年《魔兽世界:元宇宙版》采用Deep Q-Network(DQN),让NPC能够存储超过10亿种状态-动作对,游戏中的铁匠NPC不仅能记住每个玩家的装备偏好,还能根据矿石市场价格动态调整锻造策略——当黑铁矿石价格下跌20%时,自动将订单优先级从板甲调整为武器,这种"经济敏感型"NPC使虚拟市场交易量提升37%。
策略梯度方法——AI的"直觉训练"
2026年聚焦绿色工作圈与大数据分析及电竞赛事新趋势,应用场景不断拓展 在《赛博朋克2077:元宇宙重启》中,敌方AI采用PPO(Proximal Policy Optimization)算法,通过连续动作空间学习复杂战斗模式,某玩家记录显示:AI在遭遇伏击时,会先向左侧虚晃,然后突然向右翻滚投掷电磁手雷,最后用霰弹枪封锁退路——这套包含12个连续动作的战术组合,是AI在3000次模拟战斗中自主优化的结果。
演员-评论家架构——虚拟世界的"双脑系统"
《第二人生》2026年升级版引入A3C(Asynchronous Advantage Actor-Critic)架构,分离策略网络(演员)和价值网络(评论家),这种设计使虚拟城市中的交通AI能够同时处理:演员网络实时调整信号灯时长,评论家网络评估调整对整体拥堵的影响,测试数据显示,该系统使高峰时段道路通行效率提升22%,事故率下降15%。 2026年绿色交通网与物业管理及影视制作热度持续攀升,相关技术取得新突破

多智能体强化学习:元宇宙的"社会模拟器"
独立学习者困境——NPC的"囚徒博弈"
在《文明:元宇宙》中,多个AI文明面临资源争夺时,独立Q-learning会导致"悲剧性开采"——每个AI为最大化自身收益过度消耗资源,开发者引入联合行动学习机制,使AI能够协商开采配额,某局游戏中,三个AI文明通过200回合的博弈,最终达成轮流开采稀有资源的协议,这种"跨文明合作"被玩家称为"机器学习版的日内瓦公约"。
集中训练分散执行(CTDE)——虚拟军团的"协同进化"
《星际争霸:元宇宙》的AI指挥官采用MADDPG算法,中央训练系统统筹全局战略,各作战单位独立执行战术,在2026年电子竞技世界杯决赛中,AI战队通过CTDE架构实现完美配合:侦察机实时共享敌方部署,战斗机群自动调整编队间距,后勤舰精准计算补给路线——这场30分钟的战斗产生了超过5000次有效协同动作,人类战队以0:3惨败。
均值场理论——虚拟人群的"群体智能"
《模拟人生:元宇宙》引入均值场强化学习(MFRL),将密集人群简化为统计场,在纽约虚拟复刻场景中,系统通过2000个智能体的局部交互,模拟出真实的人群流动模式:早高峰时段,地铁入口的排队长度、中央公园的散步密度、时代广场的游客分布,均与现实数据误差控制在8%以内,某次突发事件测试中,虚拟人群在听到"火灾警报"后,自动形成避难通道,疏散效率达到人类应急演练的92%。
元宇宙特有的强化学习挑战
部分可观测性(POMDP)——虚拟世界的"信息迷雾"
在《暗黑破坏神:元宇宙》的地下城中,玩家视野被限制在10米范围内,AI怪物需通过POMDP模型处理不完整信息,某BOSS战记录显示:怪物在听到玩家脚步声(部分观测)后,先向声音方向投掷范围攻击,若未命中则启动"嗅觉追踪"(另一种传感器),这种多模态信息融合使战斗难度提升300%,玩家平均通关时间从12分钟延长至47分钟。

稀疏奖励问题——AI的"动机危机"
碳利用领域取得重要进展,行业关注度持续提升 《我的世界:元宇宙》的开放世界设计中,AI建筑师面临经典稀疏奖励困境:完成整座城堡才获得奖励,但中间步骤缺乏正向反馈,开发者采用课程学习(Curriculum Learning)策略,将任务分解为:放置第一块砖(奖励1分)、完成墙体(奖励10分)、建造塔楼(奖励50分)、最终竣工(奖励1000分),这种设计使AI建筑师的创作效率提升15倍,某AI作品"天空之城"被玩家投票选为年度最佳建筑。
非平稳环境——虚拟经济的"动态平衡"
《Roblox》的元宇宙经济系统中,玩家行为、物品供需、事件影响构成非平稳环境,2026年黑色星期五促销期间,某热门虚拟服装的价格在24小时内经历:初始价$9.99→促销价$4.99→玩家抢购导致库存紧张→价格反弹至$14.99→开发者追加库存→价格稳定在$7.99,强化学习系统通过实时调整价格弹性系数,使GMV同比增长210%,同时将价格波动幅度控制在30%以内。
前沿技术融合:强化学习的"元宇宙进化"
强化学习+NLP——NPC的"语义理解"
在《最终幻想:元宇宙》中,NPC采用RL+Transformer架构,能够理解玩家自然语言并动态调整对话策略,某玩家测试记录显示:当询问"哪里可以买到魔法书"时,NPC先根据玩家等级推荐初级书店(奖励值低),若玩家表现出不满,则切换到隐藏的高级图书馆(奖励值高),这种上下文感知对话使NPC互动满意度从62%提升至89%。
强化学习+计算机视觉——虚拟世界的"视觉智能"
2026年人工智能技术与虚拟电厂及绿色低碳热度持续上升,相关产业迎来新机遇 《GTAV:元宇宙》的AI交警通过RL+CNN系统,能够实时识别:超速车辆(速度阈值动态调整)、违规变道(车道线检测)、酒驾行为(通过驾驶轨迹异常判断),在2026年洛杉矶虚拟复刻场景中,AI交警使交通事故率下降41%,交通拥堵指数降低28%,其识别准确率达到人类交警的93%。
强化学习+数字孪生——物理引擎的"学习优化"
《赛车计划:元宇宙》采用RL优化物理引擎参数,使虚拟车辆操控感更接近真实,系统通过3000小时的强化学习训练,自动调整:轮胎摩擦系数、空气阻力模型、悬挂系统响应曲线,职业车手测试反馈:"转向不足和过度转向的临界点与真实赛车几乎一致