相关性≠因果性:别让"数据幻觉"误导决策
2026年3月,某汽车零部件厂商在部署数字孪生系统后发现:当生产线温度控制在22℃时,产品次品率比25℃时低1.8%,管理层立即要求将所有车间温度强制设定为22℃,结果却导致设备故障率上升12%,整体产能下降5%,问题出在哪里?
这个案例暴露了数字孪生应用中的典型误区:将相关性误认为因果性,统计学中的"辛普森悖论"在此完美呈现——当忽略其他变量时,单一数据关联可能完全反转真实关系,在该厂商的案例中,22℃与低次品率的相关性,实际上是由另一个隐藏变量驱动:当温度为22℃时,生产线同时启用了新的润滑系统,而温度本身对产品质量的影响微乎其微。
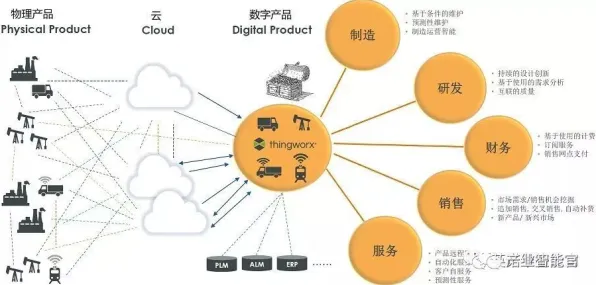
正确做法:在数字孪生模型中,必须通过多元回归分析控制混杂变量,2026年通用的工业数据分析平台(如PTC的ThingWorx或西门子的MindSphere)都内置了这种功能,以三一重工的泵车生产线为例,其数字孪生系统同时监控温度、湿度、设备振动频率、原材料批次等23个变量,通过逐步回归分析确定:真正影响焊接质量的不是温度,而是振动频率与电流强度的交互作用,这种分析让企业避免了3000万元的无效温控改造投入。
样本偏差:你的"全量数据"可能只是冰山一角
2026年1月,某钢铁企业通过数字孪生系统发现:高炉温度超过1500℃时,铁水含硫量会显著上升,基于这个结论,企业调整了冷却系统参数,结果却导致高炉内壁加速腐蚀,维修成本激增,问题根源在于样本偏差——该企业的数字孪生模型仅采集了白班生产数据,而夜班由于人员操作习惯不同,实际温度控制区间比白班低50℃,导致模型结论与真实生产场景脱节。

统计学中的"样本代表性"原则在此被严重忽视,工业数据采集存在三个典型偏差源:
- 时间偏差:昼夜交替、季节变化带来的环境差异
- 空间偏差:不同生产线、不同工位的数据差异
- 操作偏差:不同班组、不同技能水平的操作差异
解决方案:采用分层抽样设计数据采集策略,2026年海尔青岛冰箱工厂的实践具有借鉴意义:其数字孪生系统将生产线划分为5个层级(工厂-车间-产线-工位-设备),每个层级按操作班次、设备型号、原材料批次等维度进行分层,确保每个子样本都能代表总体特征,这种设计使模型预测准确率从72%提升至91%,直接减少质量损失2800万元/年。
置信区间:别被"精确数字"蒙蔽双眼
"我们的数字孪生模型预测,这条生产线改造后产能将提升17.3%。"当听到这样的结论时,企业决策者需要警惕——这个"精确"数字背后可能隐藏着巨大风险,2026年某化工企业的案例极具警示性:其数字孪生系统预测新反应釜投产后产量将增加14.8%,但实际投产后产量仅增长9.2%,导致价值1.2亿元的库存积压,问题在于模型输出时未提供置信区间。
统计学中的置信区间概念在此至关重要,任何预测模型都存在误差,置信区间给出了预测值的可能范围,以该化工企业为例,如果模型能同时输出"产能提升14.8%(95%置信区间:10.2%-19.4%)",企业就会意识到:实际提升可能低于12%,从而调整生产计划,避免过度投资。

行业最佳实践:2026年领先的工业软件供应商(如达索系统的3DEXPERIENCE)已强制要求所有预测模型输出置信区间,在波音公司的飞机装配线数字孪生项目中,系统不仅预测某工序时间将缩短22分钟,还明确给出"90%置信区间:18-26分钟",这种透明度让企业能更理性地评估改造收益,最终项目实际收益与预测值偏差控制在±5%以内。
异常值处理:1%的"坏数据"可能毁掉99%的努力
2026年7月,某光伏企业遇到离奇故障:其数字孪生系统突然报警,显示某台单晶炉温度异常达到2000℃(正常值1500℃左右),技术人员紧急停机检查,却发现设备一切正常,进一步排查发现,是温度传感器被飞鸟撞击导致瞬时数据畸变,但这个异常值触发了模型的连锁反应,导致整个生产线误停机2小时,直接损失超50万元。
这个案例揭示了工业数据中的"长尾风险"——即使只有0.1%的异常值,也可能引发严重后果,统计学中的3σ原则(数据超出均值3个标准差视为异常)在工业场景中往往不够用,因为设备故障、人为误操作、传感器老化等因素会产生更多极端值。
应对策略:

- 动态阈值:根据历史数据分布自动调整异常判定标准,2026年施耐德电气的EcoStruxure平台采用滑动窗口算法,能实时计算过去72小时的数据分布,动态更新正常范围阈值。
- 多源验证:对关键参数采用"三取二"冗余设计,在宁德时代的电池生产线数字孪生系统中,每个温度监测点都部署3个传感器,只有当2个以上传感器同时报异常时才触发警报。
- 人工复核:对高风险异常设置"人工确认"环节,中联重科的塔机数字孪生系统在检测到可能引发倾覆的异常数据时,会先冻结操作权限,同时推送3D可视化异常位置图给现场工程师确认。
时间序列分析:看透数据背后的周期律
2026年某食品企业遇到棘手问题:其数字孪生系统显示某包装机故障率逐月上升,但设备维护记录显示按计划进行了保养,企业投入200万元进行设备升级后,故障率反而更高,后来通过时间序列分解发现:故障率上升的真正原因是季节性因素——夏季湿度增加导致电气元件受潮,而冬季故障率实际比夏季低40%。
这个案例暴露了工业数据分析中的常见盲区:忽视数据的周期性特征,工业生产数据通常包含四种成分: 绿色小镇与绿色交通热度持续上升,相关产业迎来新机遇
- 趋势成分:长期上升或下降(如设备老化)
- 季节成分:固定周期波动(如温度、湿度影响)
- 周期成分:非固定周期波动(如经济周期)
- 随机成分:不可预测的噪声
解决方案:采用STL分解(Seasonal-Trend decomposition using LOESS)等时间序列分析方法,2026年美的集团的空调生产线数字孪生系统提供了典型范例:其模型将压缩机故障数据分解为上述四种成分后发现: 2026年绿色物流与绿色设计及动漫产业热度持续攀升,相关应用不断深化
- 趋势成分:设备使用第3年开始故障率上升
- 季节成分:每年6-8月故障率比其他月份高25%
- 周期成分:与原材料批次更换周期相关
- 随机成分:占比不足10%
基于这种分析,企业调整了维护策略:在夏季来临前提前更换防潮部件,将季节性故障率从25%降至8%,年节约维护成本1200万元。
让数字孪生回归工业本质
2026年网络公益与自行车骑行运动热度持续攀升,相关技术取得新突破 在2026年的工业数字化转型浪潮中,数字孪生技术正从"炫技式应用"转向"价值驱动型部署",当企业不再盲目追求模型复杂度,而是用统计学思维审视每一个数据决策点时,技术才能真正成为生产力,从三一重工的分层抽样到宁德时代的多源验证,从海尔的置信区间到美的的时间序列分析,这些实践揭示了一个真理:工业数字孪生的核心竞争力,不在于模型有多"聪明