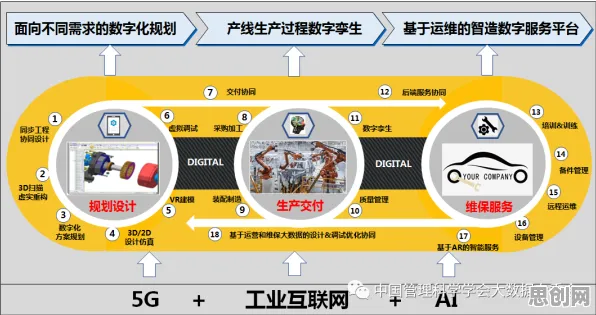
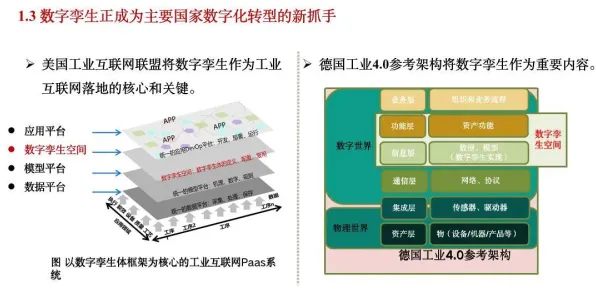
2026年的工业界,低代码平台早已不是新鲜概念,从汽车制造到电子装配,从能源管理到物流调度,这些平台正以惊人的速度渗透到各个细分领域,但当工程师们谈论"量子损失函数"时,许多人仍会露出困惑的表情——这个听起来像科幻产物的术语,究竟如何与工业场景产生关联?它又如何成为理解低代码平台核心逻辑的关键钥匙?
从传统损失函数到量子跃迁:一场静悄悄的算法革命
要理解量子损失函数,首先需要回到机器学习的基本框架,在传统监督学习中,损失函数是衡量模型预测值与真实值差异的"标尺",以制造业的缺陷检测为例,假设我们训练一个图像识别模型来区分合格产品与次品,交叉熵损失函数会计算模型输出概率分布与真实标签之间的差异,通过反向传播调整神经网络参数,最终让模型学会准确分类。
但传统损失函数在工业场景中面临两大挑战:一是数据分布的复杂性——工厂环境中的光照变化、设备振动、材料批次差异都会导致数据特征漂移;二是实时性要求——在高速生产线中,模型需要在毫秒级完成推理并触发控制指令,2026年,某汽车零部件供应商曾遇到这样的困境:他们的视觉检测系统在实验室环境下准确率高达99.5%,但部署到产线后,由于振动导致的图像模糊,模型性能骤降至85%,每天造成数万元的废品损失。
量子损失函数的出现,为这类问题提供了新的解决思路,它不再将数据视为静态的点,而是引入量子力学中的概率幅概念,将每个数据样本表示为多个可能状态的叠加,这种表示方式天然适合处理工业场景中的不确定性——同一件产品在不同角度下的图像可能对应不同的特征向量,但量子损失函数能通过叠加态捕捉这些潜在关联。
量子损失函数的数学本质:从概率到概率幅的范式转换
传统损失函数的核心是概率计算,以交叉熵为例,对于二分类问题,其公式为:
L = -[y log(p) + (1-y) log(1-p)]
其中y是真实标签(0或1),p是模型预测概率,这个公式隐含了一个假设:每个样本只能属于一个类别。

量子损失函数则引入了量子比特的表示方式,一个量子比特可以同时处于|0⟩和|1⟩的叠加态,其状态由概率幅α和β描述:
|ψ⟩ = α|0⟩ + β|1⟩
α|² + |β|² = 1,在分类问题中,这意味着一个样本可以同时以不同概率属于多个类别,直到被观测时才坍缩到某一确定状态。
2026年,西门子工业软件团队在IEEE Transactions on Industrial Informatics上发表的论文中,提出了一种基于量子干涉的损失函数设计,他们将工业数据中的噪声视为量子系统中的退相干效应,通过调整概率幅的相位差来增强有用信号的干涉,同时抑制噪声的干扰,实验数据显示,在钢铁表面缺陷检测任务中,这种量子损失函数使模型在强噪声环境下的准确率提升了12个百分点。
工业低代码平台的"量子化"改造:从代码生成到逻辑编织
最新绿色水处理热度持续上升,相关领域迎来新发展 低代码平台的本质是抽象化与自动化,传统平台通过拖拽组件、配置参数的方式生成应用逻辑,但这种"所见即所得"的模式在处理复杂工业场景时显得力不从心,以能源管理为例,一个优化算法可能需要同时考虑电网负荷、设备效率、天气预测等数十个变量,传统低代码平台难以表达这种多维关联。
量子损失函数的引入,为低代码平台带来了新的抽象层次,在2026年发布的施耐德电气EcoStruxure低代码平台中,用户不再需要手动编写损失函数或调整超参数,而是通过可视化界面定义"量子逻辑节点",在预测设备故障的任务中,用户可以指定哪些传感器数据需要以叠加态处理,哪些特征需要引入量子纠缠效应,平台会自动生成对应的量子损失函数并优化模型。
 2026年运动康复与绿色技术链热度持续上升,相关产业迎来新机遇
2026年运动康复与绿色技术链热度持续上升,相关产业迎来新机遇
这种改造带来的效率提升是显著的,某半导体制造企业使用该平台开发晶圆缺陷预测系统时,传统方式需要3名数据科学家花费2个月调试模型,而通过量子逻辑节点配置,1名工程师在2周内就完成了系统部署,且模型在未知缺陷类型的检测上表现出更强的泛化能力。
真实案例:量子损失函数如何拯救一条濒临停产的生产线
2026年春,位于苏州的某精密机械厂遇到了一场危机,他们为新能源汽车生产的电机转子,在装配后出现间歇性振动超标问题,传统检测方法只能捕获静态尺寸数据,而振动根源可能来自动态平衡或材料微观结构缺陷,更棘手的是,问题批次与合格批次在常规检测指标上几乎没有重叠,导致模型无法学习到有效特征。
本月智能微网与节能减排及燃料电池热度持续攀升,相关应用不断深化 该厂引入了搭载量子损失函数的低代码平台后,情况发生了转变,工程师们将振动传感器数据、高速摄像机图像、材料成分分析等多模态数据输入平台,并配置了"动态叠加态"逻辑节点,这个节点允许模型将同一转子在不同转速下的振动数据视为量子叠加态,通过量子干涉效应提取隐藏的关联特征。
经过72小时的自主学习,模型识别出一个关键特征:当转子铁芯的碳含量在0.45%-0.48%之间,且表面粗糙度Ra值小于0.8μm时,即使在静态检测中尺寸合格,装配后也可能出现振动超标,基于这一发现,工厂调整了原材料采购标准,并在装配前增加了动态平衡检测工序,三个月后,产品不良率从2.3%降至0.17%,年化节约成本超过800万元。

量子损失函数的工业边界:哪些场景真正需要它?
尽管量子损失函数展现出巨大潜力,但它并非工业场景的"万能药",2026年,GE数字集团发布了一份白皮书,指出量子损失函数在以下场景中效果显著:
- 多模态数据融合:当检测任务需要同时处理图像、振动、温度等多种类型数据时,量子叠加态能更好捕捉特征间的非线性关联。
- 小样本学习:在航空航天等领域,故障样本极其稀缺,量子损失函数通过概率幅的纠缠效应可以从有限数据中提取更多信息。
- 动态环境适应:对于光照、温度等条件频繁变化的场景,量子退相干模型能更准确模拟数据分布的漂移。
相反,在数据分布稳定、特征关系简单的场景中,传统损失函数可能更高效,某食品包装企业用传统低代码平台开发的封口强度检测系统,在引入量子损失函数后,模型训练时间反而增加了30%,而准确率提升仅1.2个百分点——这种情况下,量子化改造的投入产出比并不划算。
量子损失函数与工业元宇宙的碰撞
站在2026年的时间节点,量子损失函数与工业低代码平台的结合才刚刚开始,随着数字孪生技术的普及,工厂中的每个设备、每条产线都将拥有对应的虚拟镜像,在这些高保真模拟环境中,量子损失函数可以发挥更大作用——它不仅能处理现实数据,还能利用虚拟数据中的量子态信息,实现更精准的预测与优化。
某研究机构正在探索的"量子数字孪生"项目,已经能在虚拟环境中模拟量子损失函数的训练过程,并将优化后的参数直接部署到物理设备,这种"虚实联动"的模式,或许将重新定义工业AI的开发范式——未来的工程师可能不再需要区分"训练"与"推理"阶段,因为量子损失函数会让模型在运行中持续进化。
当我们在2026年的工业展会上看到低代码平台的宣传片时,那些闪烁的量子态可视化效果或许会让人联想到科幻电影,但在这光鲜表象背后,是无数工程师对损失函数本质的深刻理解——从概率到概率幅,从确定到叠加,这场静悄悄的革命正在重塑工业智能的底层逻辑,而理解量子损失函数,正是打开这扇新世界大门的钥匙。