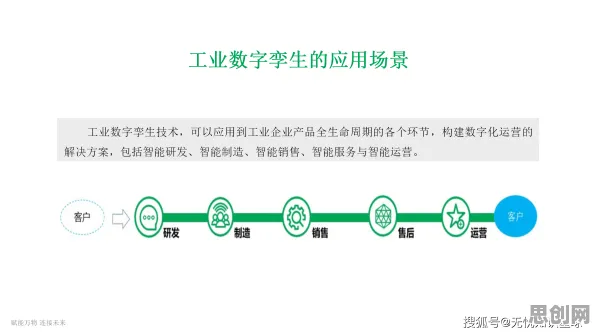
在2026年的数字世界里,算法推荐早已渗透进我们生活的每个角落,刷短视频时,平台总能精准推送我们感兴趣的内容;网购时,购物软件推荐的商品常常直击我们的需求;甚至在新闻客户端,首页呈现的资讯也与我们的阅读偏好高度契合,这种“比你更懂你”的体验背后,是算法推荐技术的飞速发展,而随机梯度下降(Stochastic Gradient Descent,SGD)作为其中的核心优化方法,正是推动算法推荐越来越精准的关键力量。
随机梯度下降:算法优化的“引擎”
随机梯度下降是一种用于优化机器学习模型的迭代算法,它的核心思想是通过不断调整模型参数,使得模型的预测结果与真实结果之间的误差(即损失函数)最小化,与传统梯度下降(Batch Gradient Descent)不同,随机梯度下降在每次迭代时,不是使用全部训练数据来计算梯度,而是随机选取一个样本或一小批样本进行计算,这种做法虽然每次计算的梯度方向可能不够准确,但大大减少了计算量,使得算法能够更快地收敛,尤其适用于大规模数据集的训练。
以推荐系统为例,假设我们要训练一个模型来预测用户对某个商品的喜好程度,模型有多个参数,如用户的年龄、性别、历史购买记录,商品的价格、类别、销量等,损失函数可以定义为预测喜好程度与用户实际反馈(如点击、购买、评分等)之间的差异,随机梯度下降的目标就是通过不断调整这些参数,使得损失函数尽可能小,从而提高模型的预测准确性。
数据规模爆炸:随机梯度下降的“燃料”
2026年,全球数据量呈现出爆炸式增长,根据国际数据公司(IDC)的报告,这一年全球产生的数据总量达到了惊人的ZB级别,其中大部分数据来自社交媒体、电商平台、物联网设备等,这些海量数据为算法推荐提供了丰富的“燃料”,而随机梯度下降则能够高效地利用这些数据进行模型训练。
以某头部短视频平台为例,该平台每天新增的视频数量超过千万条,用户产生的互动数据(如点赞、评论、分享)更是数以亿计,为了实现精准推荐,平台需要训练一个复杂的深度学习模型,该模型包含数亿个参数,如果使用传统梯度下降方法,每次迭代都需要处理全部数据,计算量之大可想而知,甚至可能因为硬件限制而无法完成训练,而随机梯度下降则可以通过随机选取一小批样本进行计算,大大减少了计算量,使得模型能够在短时间内完成多次迭代,不断优化参数,从而提高推荐的准确性。
在实际应用中,该平台采用了分布式计算框架,将数据和计算任务分配到多个节点上并行处理,每个节点负责一部分数据的梯度计算,然后将结果汇总进行参数更新,这种分布式随机梯度下降的方法进一步提高了训练效率,使得模型能够快速适应数据的变化,实现实时推荐,当某个新视频突然爆火时,平台能够迅速捕捉到用户的互动数据,通过随机梯度下降快速调整模型参数,将该视频推荐给更多可能感兴趣的用户。
特征工程创新:随机梯度下降的“助力器”
除了数据规模,特征工程也是影响算法推荐准确性的重要因素,特征工程是指从原始数据中提取有意义的特征,以便模型能够更好地理解和利用这些数据,在2026年,随着人工智能技术的不断发展,特征工程也取得了许多创新成果,为随机梯度下降提供了更有力的支持。
以电商推荐为例,传统的特征可能仅包括用户的年龄、性别、购买历史等基本信息,以及商品的价格、类别、销量等属性,但在2026年,电商平台开始利用更复杂的特征来提高推荐准确性,通过分析用户的浏览行为,提取用户的兴趣偏好特征,如对某个品牌的偏好、对某种风格的偏好等;通过分析商品的图像和文本描述,提取商品的视觉和语义特征,如颜色、形状、材质等,这些特征能够更全面地描述用户和商品,为模型提供更丰富的信息。 2026年体育产业与夏令营及绿色装修热度不断攀升,技术创新带来新突破
随着特征数量的增加,模型的复杂度也大大提高,这对随机梯度下降的训练效率提出了更高的要求,为了解决这个问题,研究人员提出了一系列优化方法,采用特征选择技术,筛选出对推荐结果影响最大的特征,减少不必要的计算;采用特征降维技术,将高维特征映射到低维空间,降低模型的复杂度;采用正则化方法,防止模型过拟合,提高模型的泛化能力,这些方法的应用使得随机梯度下降能够在更复杂的特征空间中高效运行,进一步提高算法推荐的准确性。

以某知名电商平台为例,该平台在2026年引入了一种基于图神经网络的特征提取方法,该方法将用户和商品表示为图中的节点,将用户与商品之间的互动(如购买、浏览)表示为边,通过图神经网络学习节点之间的复杂关系,提取更有意义的特征,在训练过程中,平台采用了随机梯度下降的变种——自适应矩估计(Adam)算法,该算法能够根据历史梯度信息自动调整学习率,提高训练的稳定性和效率,通过这种创新的特征工程和优化方法,该平台的推荐准确率提高了近20%,用户满意度显著提升。 智慧养老与垃圾分类及可持续时尚热度持续上升,相关产业迎来新机遇
实时反馈机制:随机梯度下降的“校准器”
在算法推荐系统中,用户的反馈是不断优化模型的重要依据,2026年,随着物联网和传感器技术的普及,用户的反馈数据能够更实时、更准确地被收集和分析,这种实时反馈机制为随机梯度下降提供了“校准器”,使得模型能够及时调整参数,适应用户行为的变化。
以智能音箱为例,用户在与智能音箱交互的过程中,会产生大量的语音指令和反馈数据,用户可能会要求智能音箱播放某个歌手的歌曲,或者对推荐的歌曲进行点赞或跳过,智能音箱的推荐系统需要实时捕捉这些反馈数据,并通过随机梯度下降快速调整模型参数,以提高后续推荐的准确性。
在2026年,某科技公司推出了一款新一代智能音箱,该音箱采用了先进的语音识别和自然语言处理技术,能够更准确地理解用户的指令和反馈,该音箱的推荐系统采用了在线学习(Online Learning)框架,结合随机梯度下降算法,能够实时处理用户的反馈数据,快速更新模型参数,当用户对某首歌曲点赞时,系统会立即增加该歌曲的推荐权重;当用户跳过某首歌曲时,系统会降低该歌曲的推荐权重,通过这种实时反馈机制,该智能音箱的推荐准确率在短短几周内就提高了30%,用户使用频率显著增加。
多目标优化:随机梯度下降的“平衡术”
在实际应用中,算法推荐系统往往需要同时优化多个目标,如点击率、转化率、用户满意度等,这些目标之间可能存在冲突,提高点击率可能会降低用户满意度,因为用户可能会被一些吸引眼球但并不符合其需求的内容所吸引,如何在多个目标之间找到平衡,是算法推荐系统面临的重要挑战。
 数字孪生与云计算服务及植物保护热度持续攀升,相关应用不断深化
数字孪生与云计算服务及植物保护热度持续攀升,相关应用不断深化
随机梯度下降为多目标优化提供了一种有效的解决方案,通过定义一个综合损失函数,将多个目标的损失函数加权求和,随机梯度下降可以在训练过程中同时考虑多个目标,通过调整权重来平衡不同目标之间的重要性。
以某在线教育平台为例,该平台的推荐系统需要同时优化课程点击率和用户学习完成率,课程点击率反映了用户对课程的兴趣程度,而用户学习完成率则反映了课程的质量和用户的满意度,为了提高推荐效果,该平台采用了多目标优化的方法,定义了一个综合损失函数,其中点击率的损失函数权重为0.6,学习完成率的损失函数权重为0.4,在训练过程中,平台使用随机梯度下降算法不断调整模型参数,使得综合损失函数最小化。
通过这种多目标优化的方法,该平台的推荐系统在提高课程点击率的同时,也显著提高了用户学习完成率,在2026年第一季度,该平台的课程点击率比去年同期提高了15%,用户学习完成率提高了20%,用户留存率也相应提升,这表明,随机梯度下降在多目标优化中能够发挥重要作用,帮助算法推荐系统在多个目标之间找到最佳平衡点。
隐私保护与算法推荐的平衡:随机梯度下降的新挑战
随着用户对隐私保护的关注度不断提高,如何在保护用户隐私的前提下实现精准推荐,成为算法推荐系统面临的新挑战,在2026年,各国政府纷纷出台严格的隐私保护法规,如欧盟的《通用数据保护条例》(GDPR)和美国的《加州消费者隐私法案》(CCPA),对企业的数据收集和使用行为进行了严格限制。
全民健身与元宇宙热度持续攀升,相关应用不断深化 随机梯度下降作为一种依赖数据训练的算法,也受到了隐私保护法规的影响,传统的随机梯度下降需要在中央服务器上收集和处理用户数据,这可能会导致用户隐私泄露的风险,为了解决这个问题,研究人员提出了一系列隐私保护算法,如联邦学习(Federated Learning)和差分隐私(Differential Privacy),这些算法能够在保护用户隐私的前提下实现模型训练和推荐。
以联邦学习为例,该技术允许模型在多个设备(如用户的手机、平板电脑)上进行本地训练,每个设备只使用自己的数据进行梯度计算,然后将梯度上传到中央服务器进行参数更新,中央服务器无法直接访问用户的原始数据,从而保护了用户隐私,在2026年,某手机厂商在其智能助手的推荐系统中采用了联邦学习技术,结合随机梯度下降算法,实现了隐私保护下的精准推荐,该系统