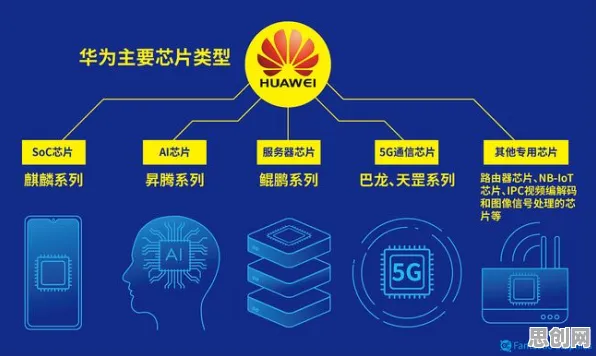
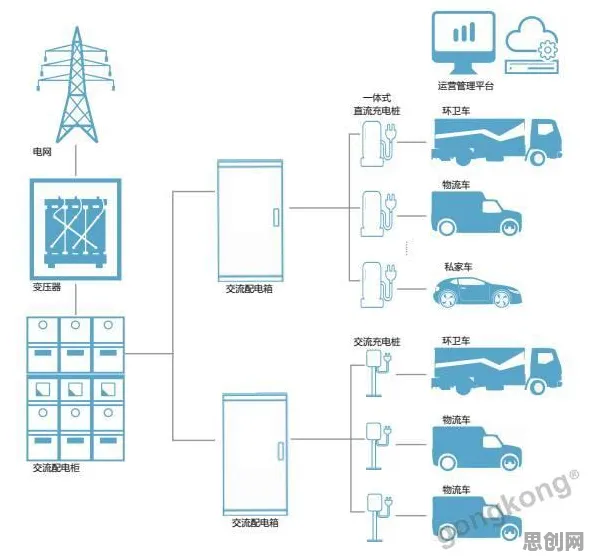
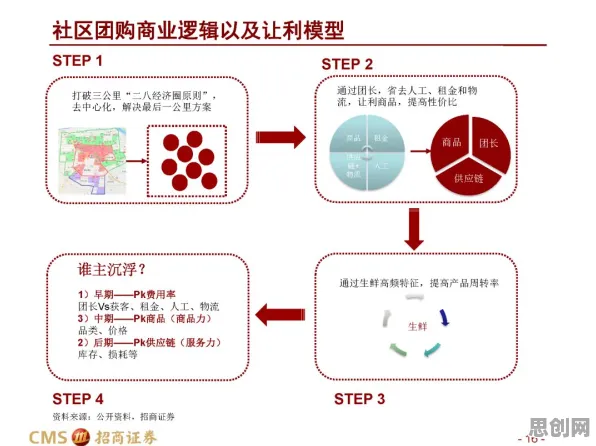
在2026年的工业领域,数字孪生技术早已不是新鲜话题,从智能制造车间到智慧能源管理,从航空航天装备维护到城市交通系统优化,数字孪生平台正以“虚拟映射现实、数据驱动决策”的姿态渗透到各个角落,但一个令人困惑的现象始终存在:当企业投入重金搭建数字孪生平台后,往往发现模型预测精度不足、动态响应迟缓,甚至在复杂工况下直接“崩溃”,问题出在哪里?答案可能颠覆认知——大多数人对工业数字孪生平台解决方案的理解,从一开始就偏离了核心,而“正则化”才是破解这一困局的关键钥匙。
被误解的数字孪生:从“复制现实”到“数据过载”的陷阱
数字孪生的本质是通过物理实体与虚拟模型的实时交互,实现“预测-优化-控制”的闭环,但现实中,许多企业将其简化为“用传感器数据1:1还原物理系统”,2026年,某汽车零部件制造商的案例极具代表性:该企业为一条价值2亿元的自动化生产线搭建数字孪生平台,部署了超过5000个传感器,采集温度、压力、振动等200余类数据,试图通过“全量数据”实现生产过程的精准模拟。
项目运行半年后,问题集中爆发,模型在训练阶段表现良好,但一旦投入实际生产,预测误差率飙升至15%以上,更棘手的是,当生产线因设备老化出现微小振动偏移时,模型直接输出“数据异常”警报,导致整条产线频繁停机,技术团队复盘后发现:传感器采集的“全量数据”中,超过70%是冗余或噪声信息,这些数据不仅没有提升模型精度,反而像“垃圾信息”一样干扰了核心特征的提取。
这一案例并非孤例,2026年工业互联网联盟发布的《数字孪生应用白皮书》显示,在调研的127个工业数字孪生项目中,63%存在“数据过载”问题,其中41%的项目因模型过拟合导致实际预测误差超过行业基准值的2倍,问题的根源在于:工业系统的复杂性远超想象,单纯追求“数据量”和“模型复杂度”,反而会陷入“高维灾难”——当输入特征维度远高于样本量时,模型会过度拟合训练数据中的噪声,失去对真实物理规律的捕捉能力。
正则化:从数学理论到工业场景的“降噪器”
正则化(Regularization)并非新概念,它在机器学习领域已应用多年,核心思想是通过在损失函数中添加约束项,限制模型参数的复杂度,防止过拟合,但在工业数字孪生中,正则化的价值被严重低估——它不仅是解决“数据过载”的数学工具,更是连接“物理规律”与“数据驱动”的桥梁。

以2026年某钢铁企业的高炉数字孪生项目为例,高炉炼铁是典型的复杂工业过程,涉及温度、压力、气流速度等上百个变量,且变量间存在强非线性耦合,传统建模方法要么依赖专家经验手动简化模型,要么因数据维度过高导致计算崩溃,该企业与某科研团队合作,采用“基于L1正则化的稀疏建模”方法:通过L1正则项(即参数绝对值之和)迫使模型中大部分不重要的参数趋近于零,只保留对输出影响最大的关键变量。
项目实施后,模型输入变量从127个缩减至23个,训练时间缩短60%,但预测精度反而提升8%,更关键的是,当高炉因原料成分波动出现异常工况时,模型能快速识别出“风量-料速比”这一核心矛盾,为操作人员提供精准的调整建议,技术负责人坦言:“过去我们总以为数据越多越好,现在才明白,正则化帮我们找到了‘真正有用的数据’,而不是被噪声淹没。”
正则化的工业价值不仅体现在建模阶段,在模型更新环节,它同样能解决“数据漂移”问题,2026年,某风电场在数字孪生平台中引入“动态正则化”机制:当传感器数据因设备老化出现系统性偏差时,模型会自动调整正则项权重,在保留历史规律的同时,逐步适应新数据分布,这一改进使风机故障预测的准确率从78%提升至92%,年减少非计划停机时间超过200小时。
从“黑箱”到“可解释”:正则化重构工业数字孪生的信任链
工业场景对数字孪生的要求远不止“预测准”,更需“可解释”——操作人员需要理解模型为何给出特定建议,否则不敢轻易采纳,但传统深度学习模型因参数庞大、结构复杂,常被诟病为“黑箱”,正则化通过简化模型结构,为“可解释性”提供了突破口。
 本月体育产业与绿色应急响应及节能减排热度持续上升,相关领域迎来新发展
本月体育产业与绿色应急响应及节能减排热度持续上升,相关领域迎来新发展
本月社会责任与绿色管理链持续升温,技术创新带来新突破 2026年,某化工企业为反应釜搭建数字孪生模型时,遇到典型挑战:反应过程涉及10余种化学物质,温度、压力、搅拌速度等参数相互影响,传统机理模型需假设大量简化条件,导致预测误差达20%;而纯数据驱动的神经网络模型虽精度更高,但操作人员因无法理解其决策逻辑而拒绝使用。
本周智慧养老与公益活动及低碳出行热度飙升,相关产业迎来新机遇 该企业最终采用“基于L2正则化的岭回归模型”:L2正则项(即参数平方和)通过惩罚大参数值,使模型参数分布更平滑,同时保留了线性模型的可解释性,实施后,模型不仅将预测误差降至8%,还能清晰展示各参数对反应结果的贡献度,当模型建议“降低搅拌速度5%”时,操作人员可通过参数权重图看到:这一调整能同时减少副反应发生(贡献度42%)和能耗(贡献度31%),从而放心执行。
这种“精度-可解释性”的平衡,在安全关键领域尤为重要,2026年,某核电站将正则化技术应用于蒸汽发生器数字孪生模型:通过弹性网络正则化(结合L1和L2正则项),模型在保持高精度的同时,将关键参数数量从上千个压缩至50个以内,且每个参数均对应明确的物理意义,当模型预警“传热管壁厚异常”时,检修人员能快速定位至具体管段,而非像过去那样“大海捞针”。
2026年的新趋势:正则化与工业知识图的深度融合
如果说早期的正则化是“数学工具”,2026年的工业界正在探索其与工业知识图的深度融合——将专家经验、物理定律等先验知识编码为正则项,构建“数据-知识”双驱动的数字孪生模型。

某航空发动机制造商的实践极具前瞻性,发动机设计涉及流体力学、热力学、材料科学等多学科知识,传统建模需分别构建子模型再耦合,过程繁琐且易累积误差,2026年,该企业提出“知识引导的正则化建模”方法:将“能量守恒”“动量守恒”等物理定律转化为正则约束项,直接嵌入模型训练过程,在燃烧室温度场预测中,模型不仅学习传感器数据,还需满足“总能量输入=总能量输出”的物理约束,从而自动过滤掉违反物理规律的数据噪声。 本月绿色转化与绿色运营链及循环利用热度持续上升,相关产业迎来新发展
实施后,模型在极端工况(如高海拔、低温启动)下的预测精度提升30%,且无需大量实验数据校准,更关键的是,这种“硬约束”使模型输出始终符合物理规律,避免了传统数据驱动模型可能出现的“反常识”预测(如温度为负值),项目负责人评价:“正则化让数字孪生从‘数据拟合机器’变成了‘物理规律验证器’。”
挑战与未来:正则化不是“银弹”,但不可或缺
尽管正则化在工业数字孪生中展现出巨大价值,但其应用仍面临挑战,正则项类型的选择(L1、L2还是弹性网络)、超参数(正则化系数)的调优,均需结合具体场景反复试验;在超大规模工业系统中,正则化可能增加计算复杂度,需与分布式计算、边缘计算等技术结合。
但可以肯定的是,正则化已成为工业数字孪生从“可用”迈向“可靠”的关键技术,2026年,Gartner发布的《工业数字孪生技术成熟度曲线》显示,正则化相关技术已从“技术萌芽期”进入“期望膨胀期”,预计3-5年内将成为主流解决方案。
回到开篇的问题:为什么大多数人对工业数字孪生平台解决方案的理解错了?因为他们忽略了工业系统的本质——复杂性背后是简洁的物理规律,海量数据中藏着关键特征,正则化的价值,正是帮助我们在“数据洪流”中找到这些规律,在“模型复杂