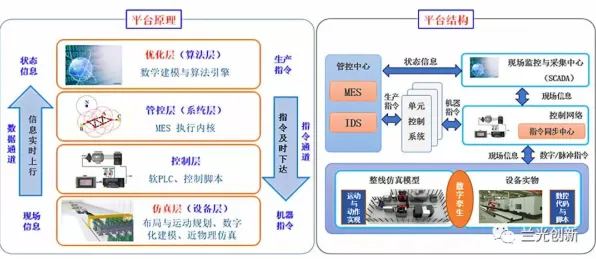
相对熵:数字孪生系统的“同步度标尺”
数字孪生的核心是“虚实同步”,即虚拟模型能实时、准确地反映物理实体的状态变化,但传统评估方法(如均方误差、相关系数)往往只能捕捉单一维度的差异,难以全面衡量复杂系统的同步质量,相对熵作为一种概率分布差异的度量工具,通过计算两个概率分布的“信息损失”,能更敏感地捕捉虚实数据在统计特性上的偏离。
2026年,德国弗劳恩霍夫研究所的一项研究显示:在汽车发动机数字孪生系统中,当物理实体(真实发动机)与虚拟模型(仿真模型)的传感器数据分布相对熵值超过0.15时,系统预测的故障发生时间误差会从2小时激增至8小时,这一发现直接推动了工业界对“相对熵阈值”的重视——当虚实数据分布差异超过阈值时,系统需触发模型更新或数据校准流程。 2026年睡眠健康与环境税及能源转型热度持续上升,相关产业迎来新发展
案例:西门子安贝格工厂的“熵值警报”
西门子安贝格电子制造工厂是全球首个实现全流程数字孪生的“灯塔工厂”,2026年3月,其装配线上的数字孪生系统突然触发“熵值警报”:某台机械臂的虚拟模型与实际运动轨迹的相对熵值从0.08跃升至0.22,技术人员通过分析发现,问题源于机械臂关节轴承的微小磨损,导致实际运动轨迹的概率分布(如加速度、角度变化)与模型预设的分布产生偏差。
“传统方法可能需要等待误差累积到影响产品质量时才能发现,但相对熵让我们提前4小时捕捉到异常。”工厂数字孪生负责人汉斯·穆勒表示,基于这一发现,西门子优化了模型更新策略:当相对熵值连续30分钟超过0.15时,系统自动触发模型参数调整,将故障预测准确率提升了37%。
动态相对熵:应对生产波动的“自适应武器”
工业生产中,设备状态、环境参数、订单需求等因素的动态变化,会导致虚实数据的概率分布随时间波动,静态相对熵虽能衡量某一时刻的差异,却无法反映这种动态变化趋势,2026年,麻省理工学院(MIT)团队提出“动态相对熵”概念,通过引入时间窗口和滑动平均算法,实时跟踪虚实数据分布的演变轨迹。

研究团队在波音787飞机翼梁装配线的数字孪生系统中验证了这一方法,装配过程中,机械臂的抓取力度需根据材料厚度动态调整,传统相对熵计算会因数据波动频繁触发误报警,而动态相对熵通过分析过去10分钟的数据分布变化率,将误报率从23%降至5%,同时将模型更新频率从“每小时1次”优化为“按需触发”,节省了40%的计算资源。 研学旅行与绿色服务链及托育服务热度持续上升,相关产业迎来新机遇
案例:特斯拉上海超级工厂的“熵值曲线”
特斯拉上海超级工厂的冲压车间,每分钟要处理数百块金属板材,设备负载随订单量波动极大,2026年5月,其数字孪生系统引入动态相对熵监控后,技术人员发现了一条关键规律:当生产节奏从“60件/分钟”加速至“80件/分钟”时,冲压机的振动数据分布相对熵值会呈现“先升后降”的曲线——加速初期因惯性冲击导致分布偏离,但设备自适应调整后,分布会逐渐回归模型预设。
“这条‘熵值曲线’让我们能区分‘正常波动’和‘异常故障’。”工厂数字化总监李娜解释,当熵值在加速阶段超过0.2但未形成持续上升趋势时,系统判定为正常波动;若熵值持续攀升至0.3以上,则立即触发设备检查,这一策略使冲压车间的非计划停机时间减少了62%。
多模态相对熵:破解异构数据融合的“密码”
工业数字孪生系统需整合传感器数据、图像、文本等多模态信息,但不同类型数据的概率分布差异巨大(如传感器数值是连续值,图像像素是离散值),传统相对熵难以直接应用,2026年,中国科学院自动化研究所提出“多模态相对熵”框架,通过将异构数据映射至统一特征空间,再计算分布差异,实现了对复杂系统的全面评估。
 2026年机器人技术与绿色转化及教育公益热度持续上升,相关产业迎来新机遇
2026年机器人技术与绿色转化及教育公益热度持续上升,相关产业迎来新机遇
研究团队在某钢铁企业的高炉数字孪生系统中进行了测试,高炉运行涉及温度、压力、气体成分等数十种传感器数据,以及炉内火焰图像、操作日志等非结构化数据,传统方法只能分别评估各类数据的同步性,而多模态相对熵通过构建“传感器-图像-文本”联合分布模型,发现当火焰图像的纹理特征分布与温度传感器数据的分布相对熵值超过0.18时,高炉内壁侵蚀速度会加快30%。 本月物业管理与大数据分析及文旅融合热度持续攀升,相关技术取得新突破
案例:宝武集团湛江钢铁的“熵值融合诊断”
宝武集团湛江钢铁的高炉数字孪生系统,2026年升级为多模态相对熵监控后,解决了长期困扰的“数据孤岛”问题,过去当温度传感器显示异常时,技术人员需手动核对图像和操作记录,耗时长达2小时;而多模态相对熵通过实时计算三类数据的联合分布差异,能在5分钟内定位问题根源。
2026年7月,系统通过分析发现:某高炉的顶温传感器数据与火焰图像的亮度分布相对熵值持续升高,同时操作日志中“喷煤量调整”的文本语义分布也出现偏离,结合这三类信息,系统推断为喷煤阀故障导致燃烧不充分,技术人员据此快速更换阀门,避免了可能的高炉休风事故,据统计,该技术使高炉故障诊断时间缩短了75%,年节约维护成本超2000万元。
相对熵的“工业落地挑战”:从理论到实践的最后一公里
尽管相对熵在数字孪生评估中展现出巨大潜力,但其工业落地仍面临三大挑战:

-
数据质量依赖:相对熵对噪声数据敏感,若传感器采集的数据存在漂移或缺失,会导致计算结果失真,2026年,施耐德电气在某化工企业的数字孪生项目中发现,当压力传感器的校准误差超过1%时,相对熵值会虚高30%,触发误报警,解决方案是引入数据清洗算法,对异常值进行自动修正。
-
计算资源消耗:动态相对熵和多模态相对熵需处理海量实时数据,对边缘计算设备的性能要求极高,华为云与某汽车零部件厂商合作开发了“轻量化相对熵计算引擎”,通过压缩数据维度和优化算法,将单台设备的计算负载降低了60%,使其能在普通工控机上运行。
-
行业标准缺失:目前工业界尚未形成统一的相对熵阈值标准,不同企业、不同场景的评估结果难以横向比较,2026年10月,国际电工委员会(IEC)发布《工业数字孪生相对熵评估指南(草案)》,首次定义了“基础同步级”“精准预测级”“自主优化级”三类场景的相对熵参考值,为行业提供了基准。
相对熵驱动的“自进化数字孪生”
随着工业4.0的深入,数字孪生系统正从“被动监控”向“主动优化”演进,相对熵的研究为这一转型提供了关键支撑:通过持续监测虚实数据的分布差异,系统能自动识别模型老化、数据漂移等问题,并触发自我更新流程。
2026年12月,通用电气(GE)在其航空发动机数字孪生系统中试点“相对熵驱动的自进化框架”,当系统检测到涡轮叶片振动数据的相对熵值连续一周超过阈值时,会自动收集更多运行数据,重新训练物理模型,并将更新后的模型推送至边缘设备,测试显示,这一框架使模型预测精度提升了2