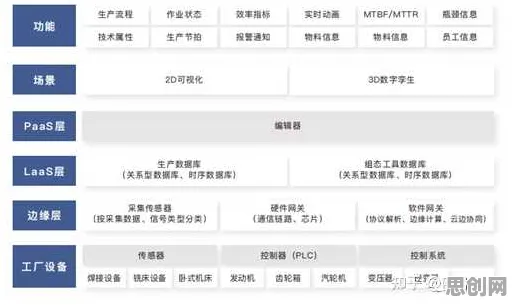
本月绿色建筑与绿色办公及大数据分析热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当人们深入探究其应用背后的逻辑时,仍会发现其中隐藏着诸多颠覆传统认知的“正则化”密码,这些密码不仅关乎技术本身的演进,更折射出工业生产模式、管理理念乃至整个产业生态的深刻变革。
从“虚拟镜像”到“动态决策中枢”:数字孪生的认知跃迁
过去,数字孪生常被简单理解为物理实体的“虚拟镜像”——通过传感器采集数据,在数字空间构建一个与现实设备、产线或工厂高度一致的模型,但2026年的实践表明,这种理解已过于狭隘,在德国西门子安贝格电子制造工厂,数字孪生系统已进化为“动态决策中枢”:它不仅能实时反映产线状态,还能基于历史数据、市场预测和工艺规则,自主生成生产优化方案。
2026年3月,该工厂接到一批紧急订单,要求在48小时内调整产线生产一种新型传感器,传统模式下,工程师需花费数小时手动修改参数、测试验证,且存在试错风险,而数字孪生系统通过分析过去类似订单的生产数据,结合当前设备状态、物料库存和人员排班,仅用12分钟就生成了最优生产方案,包括设备参数调整、物料配送路径和质检节点优化,订单提前6小时完成,不良率从0.8%降至0.3%。
这一案例揭示了数字孪生的核心价值:它不再是被动反映现实的“镜子”,而是主动参与决策的“大脑”,这种转变背后,是正则化逻辑的深度渗透——通过将工业知识、经验规则和优化算法编码为数字模型,使系统能在复杂场景中快速生成合规、高效的解决方案。
数据“清洗”与“增强”:正则化在数字孪生中的隐形战场
数字孪生的运行依赖海量数据,但2026年的工业实践表明,数据质量比数量更关键,在波音公司位于南卡罗来纳州的787梦想飞机总装厂,数字孪生系统曾因数据问题陷入困境:传感器采集的振动数据包含大量噪声,导致模型预测的设备故障时间与实际偏差超过30%。
为解决这一问题,波音团队引入了“数据正则化”流程,通过时域分析、频域滤波等技术去除原始数据中的噪声;利用历史故障数据训练生成对抗网络(GAN),生成与真实数据分布一致的“合成数据”,补充稀疏场景下的数据样本;通过特征选择算法筛选出与故障预测最相关的特征,减少冗余信息干扰。
经过三个月的优化,数字孪生系统的预测准确率从72%提升至91%,2026年5月,系统提前48小时预警了一台关键设备的轴承磨损,维修团队及时更换部件,避免了产线停机,直接节省成本超过200万美元,这一案例表明,数据正则化不是简单的“清洗”,而是通过技术手段增强数据的“表达能力”,使数字孪生模型更贴近真实物理世界。

模型“约束”与“进化”:正则化平衡精度与泛化能力
数字孪生模型的精度与泛化能力是一对矛盾:模型越复杂,对训练数据的拟合越好,但在新场景下的适应性越差;模型越简单,泛化能力越强,但可能遗漏关键特征,2026年,工业界通过正则化技术找到了平衡点。
在特斯拉上海超级工厂,数字孪生系统用于优化电池模组焊接工艺,初始模型采用深度神经网络,能精确预测焊接缺陷,但在更换供应商后,由于新材料特性不同,模型准确率骤降至65%,特斯拉团队没有重新训练模型,而是引入了“L2正则化”技术——在损失函数中添加权重参数的平方和项,限制模型复杂度,防止过拟合;结合贝叶斯优化算法动态调整正则化系数,使模型在保留关键特征的同时适应新数据。
本周网络公益与瑜伽舞蹈热度飙升,相关产业迎来新机遇 调整后的模型仅用一周时间就适应了新材料,准确率回升至92%,更关键的是,它不再依赖大量标注数据,而是通过少量样本快速学习新场景的特征,2026年8月,当供应商再次调整材料配方时,模型在48小时内完成自适应,产线未因工艺调整停机,这一案例说明,正则化不仅是技术手段,更是模型“进化”的机制——通过约束与释放的动态平衡,使数字孪生具备持续学习的能力。
从“单点优化”到“全链协同”:正则化驱动的产业生态变革
数字孪生的应用正从单个设备、产线扩展到整个供应链,2026年,宝马集团联合供应商建立了“供应链数字孪生网络”,覆盖从原材料采购到整车交付的全流程,这一网络的运行依赖一套复杂的正则化规则:每个节点的数字孪生模型需遵循统一的数据标准、接口协议和决策逻辑,确保信息在不同系统间无缝流通;通过“联邦学习”技术,各节点可在保护数据隐私的前提下共享模型参数,提升整体预测精度。
 2026年直播电商与网络公益热度持续上升,相关产业迎来新机遇
2026年直播电商与网络公益热度持续上升,相关产业迎来新机遇
2026年10月,因极端天气导致某供应商的铝合金原料运输延迟,传统模式下,这一信息需通过人工沟通层层传递,可能导致产线停机,而在数字孪生网络中,供应商的模型自动将延迟信息输入联邦学习框架,系统结合宝马工厂的库存、生产计划和物流数据,生成最优调整方案:将另一供应商的原料优先调配至受影响产线,同时调整生产顺序,优先完成无需铝合金的车型,产线仅停机2小时,较传统模式减少80%的损失。
这一案例揭示了数字孪生应用的深层逻辑:正则化不仅是技术规则,更是产业协同的“语言”——通过统一的标准和协议,打破企业间的信息壁垒,使供应链从“线性串联”变为“网络协同”。
挑战与反思:正则化不是“万能药”
尽管数字孪生与正则化的结合带来了显著效益,但2026年的实践也暴露了挑战,在某化工企业的数字孪生项目中,团队为提升模型精度,过度添加正则化约束,导致模型“过于保守”——它虽能准确预测已知故障,但对新型异常的响应延迟超过30分钟,差点引发安全事故,这一案例提醒,正则化的参数选择需谨慎:过度约束会牺牲模型的敏感性,而约束不足则可能导致过拟合。
数字孪生的正则化逻辑也引发了伦理争议,2026年,某汽车零部件厂商的数字孪生系统因数据正则化偏差,对女性操作员的效率评估低于男性,导致晋升机会不均,调查发现,训练数据中男性样本占比过高,且模型未考虑生理差异因素,这一事件促使工业界重新审视正则化的“公平性”——技术规则需兼顾效率与公正,避免因数据偏差或算法歧视加剧社会不平等。
正则化逻辑下的工业未来
2026年的工业数字孪生应用表明,正则化已从数学概念演变为工业变革的核心逻辑,它不仅是技术优化的工具,更是重构生产关系、协调产业生态的“隐形之手”,从数据清洗到模型约束,从单点优化到全链协同,正则化逻辑正在重塑工业的每一个环节。
但需清醒认识到,技术从来不是中立的——正则化的参数选择、数据样本的代表性、模型决策的透明度,都可能隐含价值判断,工业界需在追求效率的同时,建立更完善的伦理框架,确保数字孪生的正则化逻辑真正服务于人类福祉,而非成为新的控制工具,这或许才是这场技术革命最值得深思的命题。