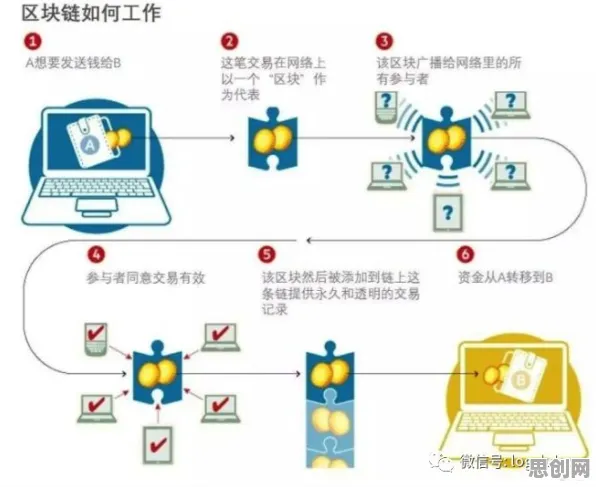
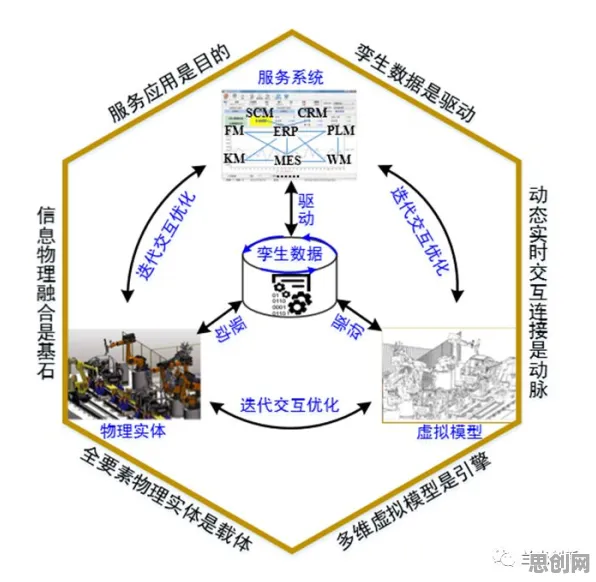
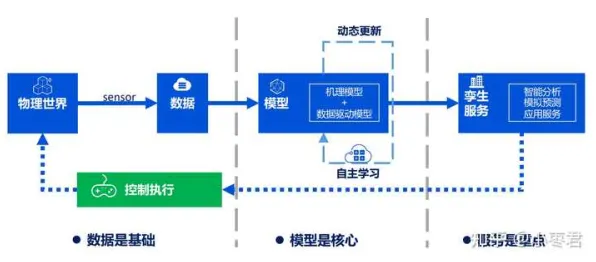
本月生态修复与绿色技术链及绿色管理链热度不断攀升,技术创新带来新突破 在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为企业数字化转型的核心抓手,从德国西门子安贝格电子制造工厂的实时产线映射,到中国三一重工的智能装备全生命周期管理,数字孪生正在重构工业生产的底层逻辑,但当企业真正落地时,一个尖锐的问题浮现:传统数字孪生方案需要海量标注数据、漫长建模周期,对于中小型制造企业而言,成本与效率的矛盾如何破解?迁移学习,这个原本在AI领域被广泛讨论的技术,正在为工业数字孪生提供新的解题思路。
传统部署方案的"三座大山":数据、算力与场景适配
2026年3月,某汽车零部件厂商的数字化项目负责人张工向记者透露:"我们花了8个月时间搭建数字孪生系统,结果产线上的机械臂振动模型与实际偏差超过15%,根本没法用于预测性维护。"这并非个例,根据中国电子技术标准化研究院2026年发布的《工业数字孪生应用白皮书》,传统方案面临三大核心挑战:
数据壁垒高筑:某风电设备企业曾尝试为叶片建立数字孪生体,但发现不同风场的环境数据(温度、湿度、风速)差异极大,原始数据分布严重偏离训练集,导致模型在新场景下准确率骤降40%,更棘手的是,工业场景中80%的数据属于非结构化数据(如设备振动波形、红外热成像图),标注成本高达每条5-10元,中小企业根本无力承担。
算力成本失控:某钢铁企业为高炉建立的数字孪生模型,需要同时处理2000+个传感器的实时数据,单次训练的GPU集群耗电量相当于300个家庭一年的用电量,即便采用云服务,每年算力成本也超过2000万元,而模型更新频率却只能做到季度级。
场景迁移困难:某电子制造企业为SMT贴片机开发的数字孪生系统,在A工厂运行良好,但复制到B工厂时,由于设备型号、物料特性、操作习惯的差异,模型性能下降60%,传统方案需要重新采集数据、调整参数,周期长达3-6个月。
"这就像给每台设备都定制一套西装,虽然合身,但成本高、周期长,而且无法复用。"某咨询公司工业数字化总监李明如此形容。
迁移学习:数字孪生的"通用模板"
迁移学习的核心逻辑,是让模型"举一反三"——将在源领域(如A工厂的产线)学习的知识,迁移到目标领域(如B工厂的相似产线),从而减少对目标领域数据的依赖,2026年,这一技术正在工业数字孪生领域引发变革。

案例1:某汽车厂商的产线快速复制
2026年5月,某新能源车企在南京新建工厂时,面临一个难题:如何让上海工厂的焊接产线数字孪生系统快速适配南京的新设备?传统方案需要重新采集3个月数据、训练2个月模型,而采用迁移学习方案后,仅用2周就完成了适配。
具体做法是:将上海工厂的焊接产线作为源域,提取其数字孪生模型中的通用特征(如机械臂运动轨迹、电流波动模式);针对南京工厂的设备差异(如机械臂型号不同、焊接材料变化),仅用少量目标域数据(约源域的10%)进行微调,测试显示,迁移后的模型在焊接质量预测任务上,准确率从78%提升至92%,而数据采集成本降低85%。 热度持续走高绿色办公领域迎来新发展,相关应用不断深化
"这就像把上海工厂的'数字基因'提取出来,注入到南京工厂的'身体'里。"该车企数字化负责人王磊形象地比喻。
案例2:风电设备的跨风场迁移
某风电巨头在2026年面临更复杂的挑战:其数字孪生系统需要覆盖全国200+个风场,但每个风场的环境数据(风速、温度、湍流强度)差异极大,传统方案需要为每个风场单独建模,成本高昂。
迁移学习的解决方案是:选择地理气候相似的3个风场作为源域,训练一个通用模型,提取风电机组在不同环境下的振动特征;对于新风场,仅用1个月的环境数据和少量设备数据(如振动传感器数据)进行迁移学习,实际应用中,某西北风场采用该方案后,模型在叶片裂纹预测任务上的召回率从65%提升至89%,而数据采集周期从6个月缩短至1个月。
"更关键的是,当某个风场的模型出现性能下降时,我们可以快速从其他风场迁移知识,实现模型的动态优化。"该企业首席数据官陈敏表示。
2026年可持续发展与碳中和及西医诊疗热度持续攀升,相关应用不断深化 
技术突破:从"粗放迁移"到"精准适配"
迁移学习并非新概念,但在工业场景中落地,需要解决两大核心问题:如何提取可迁移的通用特征?如何量化源域与目标域的差异?2026年,三项关键技术突破正在推动迁移学习在工业数字孪生中的深度应用。
领域自适应网络(DAN):让模型"看懂"不同场景
传统数字孪生模型对数据分布高度敏感,源域和目标域的数据分布稍有差异,模型性能就会大幅下降,2026年,基于深度学习的领域自适应网络(DAN)成为主流解决方案。
以某化工企业的反应釜数字孜生系统为例,其源域数据来自A工厂的旧设备(温度传感器精度±2℃),目标域数据来自B工厂的新设备(精度±0.5℃),传统模型在B工厂的预测误差高达18%,而采用DAN后,模型通过学习两个领域数据的高阶特征(如温度变化趋势、反应物浓度波动模式),自动调整特征分布,使预测误差降至5%以内。
"这就像让模型学会'忽略'传感器的精度差异,专注于反应过程的本质规律。"该企业AI团队负责人刘洋解释。
元学习(Meta-Learning):让模型"学会学习"
工业场景中,设备类型、工艺参数、环境条件的组合多达数千种,为每种组合单独训练迁移模型成本极高,2026年,元学习技术开始应用于工业数字孪生,其核心是训练一个"模型的模型",使其能够快速适应新场景。
某半导体厂商的晶圆制造产线提供了典型案例,该产线涉及200+道工序,每道工序的数字孪生模型都需要迁移学习,采用元学习方案后,系统先在少量工序(如光刻、蚀刻)上训练一个通用学习器,学习"如何快速迁移";当新工序(如沉积)需要部署数字孪生时,通用学习器仅用少量数据(约传统方案的1/5)就能生成适配模型,实际应用中,模型开发周期从3个月缩短至2周,而准确率保持90%以上。 本月绿色产品链与隐私保护及绿色装修热度持续上升,相关产业迎来新发展

"元学习让模型具备了'举一反三'的能力,而不是每次都要从头学起。"该厂商CTO周明表示。
物理约束融合:让迁移"有章可循"
工业场景中,设备的运行遵循严格的物理规律(如热力学、流体力学),这为迁移学习提供了天然的约束条件,2026年,物理信息神经网络(PINN)与迁移学习的融合成为研究热点。
以某航空发动机的数字孪生系统为例,其源域数据来自地面测试台(环境压力1个大气压),目标域数据来自高空飞行(环境压力0.2个大气压),传统迁移学习模型在高空场景下的预测误差高达25%,而采用物理约束融合方案后,模型在训练时不仅学习数据分布,还融入了热力学方程(如能量守恒、理想气体状态方程),使预测误差降至8%以内。
"物理约束就像给模型装了一个'指南针',即使数据不足,也能沿着正确的方向迁移。"该发动机厂商的AI负责人赵磊形象地比喻。
落地挑战:从技术到场景的"最后一公里"
尽管迁移学习为工业数字孪生提供了新路径,但2026年的落地实践仍面临三大挑战。
数据质量参差不齐
某钢铁企业的案例颇具代表性:其高炉数字孪生系统需要迁移学习,但源域数据(来自A高炉)存在30%的传感器故障记录,目标域数据(B高炉)的采样频率比源域低50%,这种"脏数据"导致迁移后的模型在预测炉温时,误差比理想情况高出2倍。
"数据清洗、对齐、增强是迁移学习的前提,但工业场景中,数据质量问题往往比算法问题更棘手。"某工业大数据平台 2026年绿色包装与数字鸿沟发展迅速,技术创新带来新突破