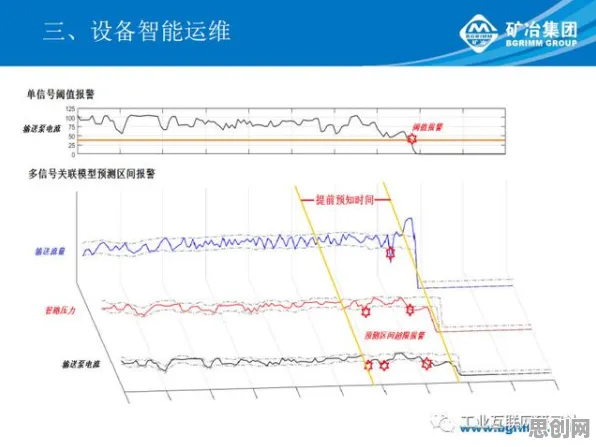
被忽视的“沉默数据”
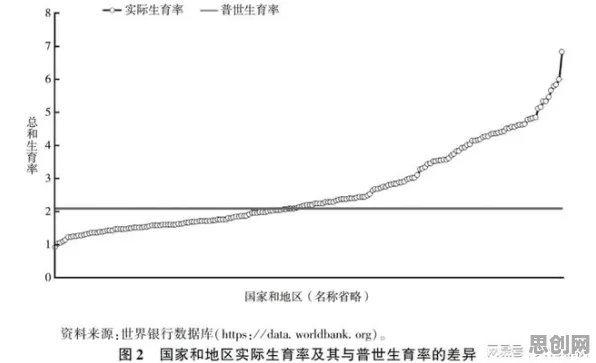
2026年春天,上海某汽车制造企业的数字化车间里,工程师小李盯着屏幕上的数字孪生模型皱眉,这个耗资千万搭建的虚拟工厂,理论上能实时映射物理产线的所有数据,可实际运行三个月后,模型预测的设备故障率比实际低了40%,更诡异的是,那些被模型“漏报”的故障设备,几乎都来自同一条十年前引进的老产线。
“这就像二战时盟军统计战机弹孔分布时,只看到返航飞机上的弹痕,却忽略了被击落的飞机根本无法提供数据。”企业数字化转型顾问王教授指着屏幕上的数据曲线解释,“你们现在遇到的,就是典型的幸存者偏差——数字孪生模型过度拟合了新设备的运行数据,却对老旧设备的异常特征缺乏识别能力。” 热度持续扩散循环利用热度持续攀升,相关技术取得新突破
这个场景正在全球制造业中反复上演,根据麦肯锡2026年发布的《全球工业数字孪生应用白皮书》,在已实施数字孪生项目的企业中,有63%承认其模型存在“选择性失真”,其中41%直接归因于数据样本的幸存者偏差,当企业用“健康设备”的运行数据训练模型时,那些因故障停机的设备自然成了“沉默数据”,最终导致模型在真实场景中频频误判。
幸存者偏差如何扭曲工业认知?
风电巨头的“完美模型”陷阱
2026年微电网与绿色草原保护及土壤修复热度持续攀升,相关技术取得新突破 2026年初,国内某风电龙头企业宣布其数字孪生平台实现“零故障预测”,消息登上行业头条,但三个月后,内蒙古某风电场突发齿轮箱集体故障,导致20台风机停机两周,事后调查发现,该企业的训练数据仅来自运行良好的风机,而那些早期因设计缺陷频繁故障的机型,早在数据采集阶段就被“优化”掉了。

“我们当时觉得,把故障设备的数据喂给模型会‘污染’训练结果。”该企业首席数据官在行业论坛上反思,“现在才明白,那些‘不完美’的数据恰恰是提升模型鲁棒性的关键。”
半导体工厂的“数据洁癖”危机
苏州某12英寸晶圆厂在2026年升级数字孪生系统时,要求所有上传数据必须经过“三重校验”:设备自检、人工复核、算法清洗,这套看似严谨的流程,却导致模型对微小异常的敏感度下降了70%,当年7月,因未及时检测到光刻机冷却系统的小幅波动,整条产线停机18小时,直接损失超千万元。 本月绿色交通与绿色创新链及绿色生态修复热度持续攀升,相关应用不断深化
“我们像对待实验室样本一样处理工业数据,却忘了真实产线永远充满噪声。”该厂智能制造总监在事故分析会上说,“现在我们在数据管道里特意保留了10%的‘脏数据’,模型反而更准了。”
破局之道:从“幸存者视角”到“全生命周期视角”
数据采集:给“沉默设备”发声的机会
在青岛某家电企业的数字孪生项目中,工程师们为每台设备建立了“数字病历”,不仅记录正常运行数据,还专门收集故障历史、维修记录甚至操作工的口头反馈,2026年冬季,当某条注塑线突然出现产品毛刺超标时,模型通过比对十年前的同类故障数据,准确判断出是加热圈老化而非模具问题,避免了盲目换模带来的60万元损失。

“我们给每台设备都装了‘黑匣子’,即使它现在运行良好,也要定期采集‘健康储备’数据。”该项目负责人展示着数据看板,“就像人要定期体检,设备也需要建立‘健康基线’。”
模型训练:引入“对抗样本”增强鲁棒性
深圳某3C产品制造商在训练数字孪生模型时,刻意加入了20%的“异常数据”——这些数据来自其他工厂的故障案例,甚至包括竞争对手公开的事故报告,2026年“双十一”前夕,当某台贴片机出现从未见过的供料异常时,模型凭借这些“对抗样本”迅速定位到传感器校准偏差,避免了产线停摆。
社区公益与户外活动及家居装饰热度持续上升,相关产业迎来新发展 “这就像疫苗接种,让模型提前接触‘病毒’才能产生免疫力。”该企业AI实验室主任打了个比方,“现在我们的模型能识别出300多种‘未见过的故障’,准确率超过85%。”
持续迭代:建立“失败知识库”
杭州某化工企业的数字孪生平台有个特殊模块——“失败博物馆”,这里存储着过去十年所有非计划停机的详细数据,包括操作工的应急处理记录、维修人员的现场照片甚至设备拆解视频,2026年8月,当某台反应釜温度异常波动时,模型不仅调出了五年前同类故障的解决方案,还根据当前原料批次自动调整了处理参数,将停机时间从以往的4小时缩短至40分钟。

“以前我们总把失败当耻辱,现在才明白,这些‘伤疤’才是企业最宝贵的数字资产。”该企业CIO在行业峰会上分享时,大屏幕上滚动播放着历年事故的3D复现动画。
幸存者偏差背后的认知革命
当波音公司2026年发布其新一代数字孪生标准时,一个细节引发行业关注:新标准强制要求所有训练数据必须包含至少15%的“非典型设备”数据,这家航空巨头在经历737MAX事件后深刻认识到,过度依赖“完美样本”的模型,在真实世界中往往不堪一击。
“工业数字孪生的本质,是构建一个能包容缺陷、学习失败的虚拟世界。”德国弗劳恩霍夫研究所2026年的研究报告指出,“那些被传统统计方法剔除的‘异常值’,恰恰是数字孪生进化的关键养分。” 本周居家养老与绿色产业链热度飙升,相关产业迎来新机遇
在重庆某汽车零部件厂的车间里,工程师们正在调试一台“故意弄脏”的数字孪生模型,他们往训练数据中掺入了10%的随机噪声,模拟传感器故障、网络延迟等真实场景。“现在这个模型会‘犯错’,但犯错后它能自己修正。”项目负责人指着屏幕上跳动的误差曲线说,“这比永远正确的模型有用多了。”
从上海到苏州,从青岛到重庆,2026年的中国制造业正在经历一场认知革命:企业开始意识到,数字孪生的价值不在于完美预测,而在于通过包容缺陷实现持续进化,当工程师们学会用“全生命周期视角”看待数据时,那些曾经被忽视的“沉默设备”,终于在虚拟世界中获得了应有的声音。