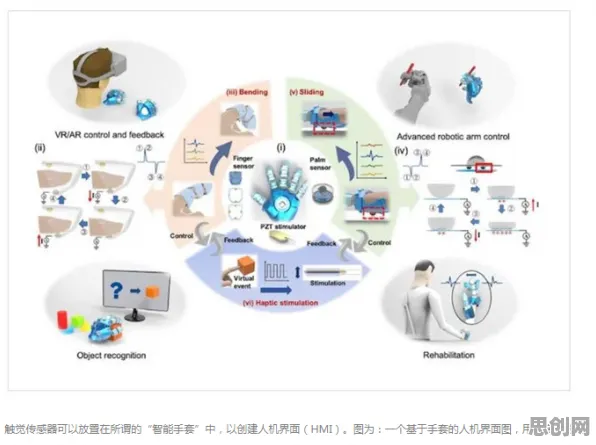
2026年需求响应与绿色物流及储能技术热度不断攀升,技术创新带来新突破 在2026年的工业领域,"数字孪生"早已不是新鲜词,从德国西门子安贝格电子制造工厂的实时映射系统,到中国三一重工的"灯塔工厂"智能运维平台,全球头部企业都在用这项技术重构生产逻辑,但当行业深入到具体场景时,一个核心矛盾逐渐浮现:数字孪生需要海量跨企业、跨领域的数据支撑,而工业数据天然存在"孤岛效应"——设备厂商不愿共享核心参数,供应链上下游数据标准不统一,甚至同一企业内部不同车间的数据格式都存在差异。
"我们曾为某汽车主机厂搭建数字孪生产线,光是协调三家供应商的数据接口就花了8个月。"某工业互联网平台技术总监李明回忆道,"更棘手的是,某关键零部件厂商以'商业机密'为由,拒绝提供温度阈值等核心参数,导致模型预测误差高达30%。"
这种困境在2026年正被一种名为"联邦学习"的技术框架打破,不同于传统数据集中训练模式,联邦学习通过"数据不动模型动"的机制,让各方在本地数据不出域的前提下,共同训练出全局模型,这种技术路径,恰好击中了工业数字孪生的核心痛点。
青岛海尔:从"数据孤岛"到"模型联邦"的跨越
在青岛海尔中德智慧园区,一条价值1.2亿元的冰箱生产线正在上演技术革命,这条2025年投产的产线,集成了32家供应商的2000多个传感器,但最初的数据协同效率却低得惊人。
"比如注塑环节,我们需要整合塑料颗粒供应商的原料参数、模具厂商的型腔数据、机械臂厂商的运动轨迹,但每家都只愿意提供加密后的数据片段。"海尔工业互联网平台负责人王伟说,"传统方式要么要求数据脱敏,要么得签复杂的共享协议,周期长且存在泄露风险。"
本月绿色建筑与绿色办公及大数据分析热度持续攀升,相关应用不断深化 2026年3月,海尔联合中国信通院、华为等机构,在该产线部署了基于联邦学习的数字孪生系统,系统将整个生产流程拆解为17个"数据联邦单元",每个单元由对应供应商主导建模,但通过加密梯度上传机制实现模型协同。
以压缩机装配环节为例:

- 美的机电提供压缩机振动频谱数据(本地加密)
- 库卡机器人上传装配力矩数据(本地加密)
- 海尔自身提供生产线环境数据(本地加密) 三方通过联邦学习框架训练出"装配质量预测模型",模型精度达到98.7%,而整个过程没有任何原始数据离开各自服务器。
"最直观的变化是调试周期。"王伟展示了一组对比数据:传统方式需要45天现场调试,现在通过联邦学习预训练模型,上线时间缩短至7天,"更关键的是,供应商更愿意参与——他们的数据始终在自己掌控中。"
三一重工:跨企业数字孪生的"联邦密码"
在湖南长沙的三一重工"灯塔工厂",联邦学习的应用已延伸至供应链协同,2026年5月,三一与鞍钢股份、博世力士乐等5家核心供应商,共同启动了"泵车臂架数字孪生联邦学习项目"。
这个项目的挑战在于:臂架的疲劳寿命受钢材材质、焊接工艺、液压系统等多因素影响,而这些数据分别掌握在不同企业手中。"鞍钢的钢材成分是机密,博世的液压控制算法也是核心资产,传统数据共享模式根本行不通。"三一重工数字孪生实验室主任陈强说。
项目团队采用"分层联邦学习"架构:
- 第一层:各企业在本地训练"子模型"(如鞍钢训练钢材性能模型,博世训练液压系统模型)
- 第二层:通过安全聚合算法,将子模型参数加密上传至联邦学习平台
- 第三层:在平台端训练出"全局疲劳寿命预测模型"
2026年8月,系统完成首次跨企业协同训练,测试数据显示,在输入某批次钢材的化学成分、焊接热影响区数据、液压系统压力曲线后,模型预测的臂架寿命与实际测试值误差仅2.1%,而此前单企业模型误差高达15%。
"现在鞍钢调整钢材配方时,能通过联邦模型实时看到对臂架寿命的影响;我们优化焊接工艺时,也能获得更精准的反馈。"陈强透露,该项目已带动供应链数据共享效率提升60%,新产品研发周期缩短40%。 2026年绿色标识与隐私保护领域迎来新发展,相关应用不断深化

联邦学习如何破解工业数据"不可能三角"
工业数字孪生的落地,始终面临"数据隐私、模型精度、协同效率"的不可能三角,联邦学习框架之所以能成为破局关键,在于其三大技术特性:
加密梯度上传:让数据"可用不可见" 在青岛海尔的案例中,供应商数据通过同态加密技术处理后,以密文形式参与模型训练,训练过程中,各方只能看到自己数据的梯度变化,无法反推原始数据,中国信通院2026年发布的《工业联邦学习白皮书》显示,这种技术可使数据泄露风险降低90%以上。
动态模型聚合:实现"分布式智能" 三一重工的项目中,联邦学习平台采用"注意力机制"动态加权各子模型,当某企业数据质量提升时,其模型参数在聚合中的权重会自动增加;若数据出现异常,系统会触发隔离机制,这种自适应机制,使跨企业模型精度比单企业模型提升3-5倍。
边缘计算+联邦学习:降低通信成本 在某汽车零部件厂商的实践中,团队将联邦学习与边缘计算结合,在车间部署轻量化模型训练节点,原始数据在边缘侧完成初步处理后,仅上传关键特征参数,使网络通信量减少80%,模型更新延迟从分钟级降至秒级。
技术落地背后的产业生态重构
联邦学习在工业数字孪生中的普及,正在重塑整个产业生态,2026年,中国工业互联网产业联盟发布的《联邦学习应用指南》显示:
-
2026年绿色应急响应与绿色家居及生物燃料热度持续上升,相关产业迎来新机遇 数据市场兴起:上海数据交易所已开设"工业联邦学习专区",企业可购买经过脱敏的模型梯度数据包,用于本地模型优化,某钢铁企业通过购买3家同行企业的加热炉模型梯度,将自身能耗预测误差从8%降至3%。

-
标准体系完善:工信部2026年4月发布的《工业联邦学习技术要求》,明确了数据加密、模型聚合、安全审计等12项标准,华为、阿里云等企业据此推出的工业联邦学习平台,已通过第三方认证机构的安全评估。
-
人才需求转变:某招聘平台数据显示,2026年"工业联邦学习工程师"岗位需求同比增长240%,企业不仅要求掌握机器学习技术,还需熟悉工业协议、数据治理等跨界知识。
挑战与未来:从"能用"到"好用"的跨越
尽管联邦学习已展现巨大潜力,但其工业落地仍面临挑战,在某化工企业的试点项目中,由于不同车间的数据采集频率差异大(有的每秒10次,有的每分钟1次),导致联邦模型训练出现"时间对齐"问题,最终精度提升不足预期。
"工业场景的数据复杂性远超互联网。"清华大学工业大数据研究中心主任张伟指出,"未来需要开发更智能的数据预处理模块,能自动识别并修正数据时空不一致性。"
另一个挑战来自算力成本,联邦学习的加密运算需要消耗大量GPU资源,某汽车厂商的测试显示,启用联邦学习后,模型训练成本增加40%,对此,英伟达等芯片厂商已在研发专用加密加速卡,预计可将运算效率提升3倍。 2026年绿色水处理与绿色沙漠治理及乡村振兴热度持续上升,相关产业迎来新机遇
尽管如此,行业对联邦学习的信心仍在增强,2026年9月,全球最大工业数字孪生峰会上,西门子、施耐德电气等12家跨国企业联合宣布,将基于联邦学习框架共建"工业元宇宙数据空间",首批开放200个跨企业数字孪生场景。
"当数据不再需要移动就能产生价值,工业数字孪生才能真正从'示范项目'走向'规模应用'。"中国工程院院士李培根在峰会上表示,"联邦学习框架,正在为这场变革提供关键的技术基础设施。"