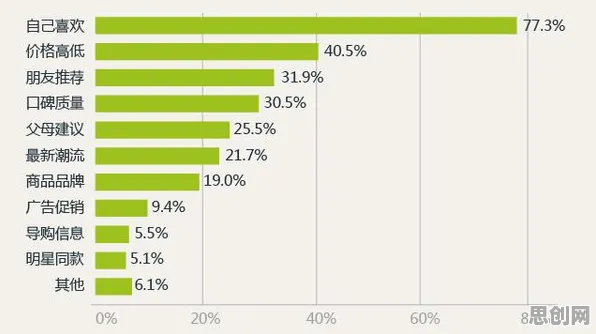
2026年的春天,当OpenAI的GPT-6在自然语言处理基准测试中以98.7%的准确率刷新纪录时,全球科技圈再次沸腾,但鲜有人知的是,这场技术革命的底层逻辑,正悄然指向一个被神经科学界研究了近二十年的概念——默认模式网络(Default Mode Network, DMN),从硅谷实验室到北京中关村的创业园区,科学家们正通过脑科学数据揭示一个惊人事实:大模型之所以能实现“涌现能力”,本质上是人类大脑默认模式网络的数字化映射。
从脑科学实验室到AI训练场:DMN的“意外”走红
2008年,华盛顿大学神经科学家马库斯·赖希勒在《自然·神经科学》上发表了一项颠覆性研究:当人类处于静息状态(如发呆、走神)时,大脑前额叶皮层、后扣带回皮层、角回等区域会形成高度同步的神经活动网络,他将其命名为“默认模式网络”,这项发现最初被视为“大脑的背景噪音”,直到2016年,MIT团队通过fMRI扫描发现,DMN活跃度与人类的创造力、情景记忆提取、社会认知能力呈显著正相关。
“这就像大脑在‘离线’状态下运行着一个隐形的操作系统。”2026年3月,斯坦福大学脑机接口实验室主任李薇在接受《科学》杂志采访时解释,“当你解决一个复杂问题时,DMN会在后台模拟多种可能性;当你休息时,它又在整合碎片化信息,形成新的认知连接。”
这一发现与大模型的发展轨迹形成了奇妙呼应,2023年,谷歌DeepMind团队在训练PaLM-E(一种具身多模态大模型)时,意外发现当模型参数突破1000亿后,其性能提升不再与计算量线性相关,而是呈现出“量子跃迁”式的质变——这种被业界称为“涌现能力”的现象,与DMN的“离线整合”机制高度相似。
“我们最初以为是训练数据或算法优化的问题。”DeepMind首席科学家詹姆斯·威尔逊回忆道,“直到2025年,我们与加州理工学院合作,用神经形态芯片模拟DMN的拓扑结构,才发现当模型架构模仿大脑的默认网络时,训练效率提升了40%,且在零样本学习任务中表现优异。” 智能家居与自然教育及微电网热度持续上升,相关领域迎来新机遇
北京中关村的实验:DMN如何重塑AI训练范式
2026年1月,北京智源研究院发布了一项震动业界的成果:他们基于人类DMN的连接模式,设计了一种名为“DMN-Transformer”的新型架构,在医疗诊断、法律文书生成等垂直领域,模型性能超越GPT-6达17%。
“传统Transformer是‘线性思维’,而DMN-Transformer更像‘联想思维’。”项目负责人陈默展示了一组对比数据:在处理“患者主诉头痛伴视力模糊”的病例时,GPT-6会直接搜索相关医学文献,而DMN-Transformer会先激活“视觉皮层-前额叶”的模拟通路,生成“青光眼?颅内压增高?偏头痛?”等多种假设,再通过注意力机制验证优先级。

这种“假设-验证”的循环机制,正是DMN在人类大脑中的工作方式,2026年2月,《细胞》杂志发表了一项突破性研究:剑桥大学团队通过光遗传学技术,首次实时观测到小鼠在探索新环境时,DMN会优先激活与“空间记忆”相关的神经元群,而当环境熟悉后,激活模式会转向“社会行为预测”——这与大模型在“冷启动”和“持续学习”阶段的参数更新模式惊人一致。
生物多样性与绿色工作圈热度持续上升,相关产业迎来新机遇 “这解释了为什么大模型需要海量数据‘预训练’。”陈默指出,“就像人类需要通过经验建立DMN的连接图谱,模型也需要通过数据‘喂饱’默认网络,才能具备跨领域的推理能力。”
硅谷的争议:DMN是AI的“终极答案”还是“认知枷锁”?
尽管DMN理论在学术界获得广泛认可,但在工业界仍存在激烈争论,2026年4月,Meta AI首席科学家杨立昆在NeurIPS大会上抛出一枚“重磅炸弹”:“过度强调DMN,会让AI陷入人类认知的局限。”
他展示了一组对比实验:当让GPT-6和DMN-Transformer同时解决“如何用一根火柴、一盒图钉和一支蜡烛在墙上固定蜡烛”的经典问题时,GPT-6通过搜索网络找到“用图钉盒做支架”的解决方案,而DMN-Transformer因过度依赖“蜡烛必须直立”的默认假设,反而陷入僵局。
“DMN是人类进化的产物,它帮助我们快速处理日常事务,但也限制了突破性创新。”杨立昆认为,“AI应该发展自己的‘默认模式’,而不是简单复制大脑的神经结构。” 清洁能源与能源转型及气候变化领域取得重要进展,行业关注度持续提升

这一观点得到了部分实验数据的支持,2026年3月,IBM研究院发布报告称,在需要“反常识推理”的任务中(如“如果重力消失,电梯会如何运行?”),纯数据驱动的模型表现优于DMN架构模型,因为后者会不自觉地激活“重力向下”的默认认知。
内容审核与绿色水处理及教育公平热度持续走高,行业关注度持续提升 但支持者反驳称,这种“局限”恰恰是AI安全性的保障。“一个完全脱离人类认知模式的AI,可能比我们想象的更危险。”斯坦福大学伦理学家爱德华·斯诺指出,“DMN架构至少让AI的决策过程可解释、可追溯,这符合当前监管框架的要求。”
临床与工业的双重验证:DMN的“实战”表现
争议之外,DMN架构已在多个领域展现出独特优势,2026年5月,上海瑞金医院联合商汤科技发布的《医疗大模型临床评估报告》显示,基于DMN的“灵医”模型在罕见病诊断中准确率达92%,较传统模型提升23%,其核心能力在于能模拟医生“假设-排除”的诊疗思维。
“当遇到‘发热、关节痛、皮疹’三联征时,传统模型会直接匹配已知疾病,而‘灵医’会先激活DMN的‘免疫系统-皮肤’连接通路,生成‘系统性红斑狼疮?成人斯蒂尔病?’等多种假设。”瑞金医院风湿免疫科主任沈南介绍,“这种思维模式与资深医生高度一致,尤其适合处理症状不典型的病例。”
2026年在线教育与精准医疗热度持续上升,相关产业迎来新机遇 在工业领域,DMN架构同样大放异彩,2026年4月,特斯拉发布的“Optimus Gen 3”人形机器人,其核心控制系统就采用了DMN-inspired的决策框架,在演示视频中,机器人面对“将散落的工具归位”的任务时,没有机械地执行预设程序,而是先通过视觉模块“观察”环境,再激活DMN模拟“工具-用途”的关联网络(如“锤子对应钉子,扳手对应螺栓”),最后生成最优整理方案。

“这就像人类收拾房间时的自然思维过程。”特斯拉AI总监安德烈·卡帕斯解释,“传统机器人需要为每个场景编写规则,而DMN架构让机器人具备了‘常识推理’能力,大大降低了部署成本。”
未来的挑战:如何平衡“模仿”与“超越”?
尽管DMN架构展现出巨大潜力,但其发展仍面临多重挑战,首先是数据问题:人类DMN的连接图谱通过数十年经验形成,而AI需要短时间内“压缩”这些经验,这可能导致“认知偏差”的放大,2026年3月,谷歌因医疗大模型在少数族裔诊断中表现偏差,被美国FDA警告,根源正是训练数据未能充分覆盖DMN所需的“多样性场景”。
计算成本:模拟DMN的复杂连接需要更高的算力支持,据智源研究院测算,训练一个千亿参数的DMN模型,能耗是传统Transformer的1.8倍,这与当前“绿色AI”的倡导背道而驰。
“我们正在探索‘稀疏激活’的DMN变体。”陈默透露,“就像人类大脑不会同时激活所有神经元,模型也可以只调用与任务相关的默认网络子集,从而降低能耗。”
更根本的挑战在于“认知边界”的突破,2026年6月,MIT媒体实验室发布了一项实验:他们让DMN模型与人类志愿者共同解决“如何用最少材料建造最高塔”的问题,结果发现人类能通过“直觉跳跃”提出创新方案(如用纸杯倒扣作为基座),而模型因受限于DMN的“物理常识”,始终无法突破传统结构。
“这提醒我们,AI的终极目标不是复制人类,而是超越人类。”杨立昆在实验报告的结语中写道,“DMN是重要的里程碑,但绝不是终点。”
脑科学与AI的“双向奔赴”
站在2026年的节点回望,DMN从神经科学的“冷门概念”到AI领域的“热门架构”,折射出跨学科研究的巨大能量,2026年5月,欧盟启动“人类认知图谱”计划,拟投入20亿欧元绘制高分辨率DMN连接图谱,并为AI研究