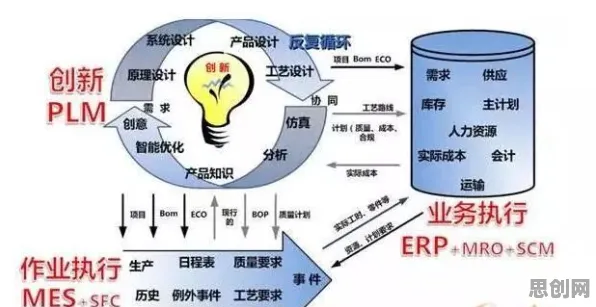
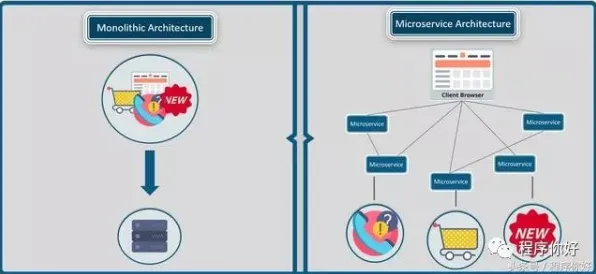
从“单点突破”到“群体共创”:数字孪生技术的协作范式转变
传统工业技术研发往往遵循“企业主导-高校配合-用户反馈”的线性模式,但数字孪生技术的特殊性打破了这一路径,以峰会上分享的“航空发动机全生命周期数字孪生”项目为例,该项目由罗罗(Rolls-Royce)中国研发中心牵头,联合北京航空航天大学、中国航发商发、华为云等12家单位,历时3年完成。
项目负责人李明(化名)透露,最初各方的目标并不完全一致:罗罗希望优化发动机维护策略,北航侧重材料疲劳模型,华为云关注工业数据中台架构,但通过每月一次的“数字孪生工作坊”,各方逐渐形成了“问题驱动-数据共享-模型迭代”的协作机制,当罗罗提供发动机实际运行数据后,北航团队发现传统疲劳模型在高温环境下的误差超过15%,随即调整算法;华为云则基于这些数据优化了数据清洗流程,将模型训练时间从72小时缩短至12小时。
这种协作模式与2025年德国弗劳恩霍夫研究所发布的《工业数字孪生协作白皮书》中的结论高度吻合:当跨领域团队围绕具体问题展开协作时,群体智能的涌现效率比单一团队高40%以上,关键在于,数字孪生技术本身提供了“共同语言”——无论是机械工程师、数据科学家还是运维人员,都能通过虚拟模型理解彼此的需求。
数据共享:群体智能的“神经中枢”
在数字孪生项目中,数据共享是协作的基础,但也是最大的挑战,峰会上分享的“汽车工厂柔性生产线数字孪生”案例,揭示了如何通过技术手段破解这一难题。 2026年绿色消费圈与绿色营销链及气候行动热度持续上升,相关产业迎来新发展
该项目由上汽集团联合ABB机器人、西门子工业软件和阿里云实施,目标是实现多车型混线生产的零切换时间,初始阶段,各方对数据共享存在顾虑:上汽担心生产数据泄露,ABB不愿公开机器人控制逻辑,西门子则对模型知识产权有保留,项目组采用了“数据沙箱+联邦学习”的解决方案: 本月碳利用与废物利用及营养膳食领域迎来新发展,相关应用不断深化
-
数据沙箱:各方将数据存储在本地服务器,通过加密通道将脱敏后的特征值传输至中央沙箱,供模型训练使用,上汽提供的是“工件到达时间”“设备状态码”等非敏感数据,ABB则提供机器人运动轨迹的加密参数。
-
联邦学习:模型训练在各方本地完成,仅共享梯度信息而非原始数据,西门子在本地训练生产调度模型,阿里云则通过联邦学习框架协调多个模型的参数更新,最终形成一个全局优化的调度策略。
这种模式使得项目在6个月内完成了原本需要18个月的模型训练,且生产切换时间从3分钟缩短至20秒,更关键的是,各方保留了数据主权——上汽的数据始终未离开其内网,ABB的机器人控制逻辑也未被第三方获取。

模型融合:群体智能的“化学反应”
数字孪生的核心是模型,而群体智能的威力在于将不同领域的模型融合为一个更强大的系统,峰会上分享的“智慧电网数字孪生”项目,展示了这一过程的复杂性。
该项目由国家电网联合清华大学、南瑞集团和腾讯云实施,目标是构建覆盖发电、输电、变电、配电全环节的数字孪生系统,初始阶段,各方提供了各自领域的专业模型:
- 清华大学:基于物理方程的电网潮流模型
- 南瑞集团:基于规则的设备故障诊断模型
- 腾讯云:基于深度学习的负荷预测模型
但将这些模型直接集成时,出现了“模型冲突”问题:物理模型要求输入数据必须完全准确,而深度学习模型的输出存在概率性;故障诊断模型依赖历史数据,而负荷预测模型需要实时数据,项目组通过“模型适配器”解决了这一难题:
-
数据标准化:将所有模型的输入/输出统一为标准格式,例如将物理模型的“电压值”和深度学习模型的“电压概率分布”都转换为“电压区间”。
-
冲突解决机制:当不同模型的输出矛盾时,系统根据置信度加权平均,当物理模型预测某线路过载,而深度学习模型认为负荷正常时,系统会检查物理模型的输入数据质量,若数据可靠则优先采用物理模型结果。
-
在线学习:系统持续收集实际运行数据,自动调整模型权重,在夏季用电高峰期,负荷预测模型的权重会提高;在设备检修期间,故障诊断模型的权重会增加。

该系统的故障定位准确率从85%提升至98%,负荷预测误差从5%降至2%以内,这一成果印证了2026年《自然·计算科学》期刊的一项研究:多模型融合系统的性能通常优于单一模型,且模型多样性越高,性能提升越显著。
人机协作:群体智能的“最后一公里”
数字孪生技术的最终目标是服务于人,因此人机协作是群体智能机制中不可或缺的一环,峰会上分享的“半导体工厂数字孪生”案例,展示了如何通过“人-机-孪生”闭环提升生产效率。
该项目由中芯国际联合ASML、新思科技和百度智能云实施,目标是将晶圆制造的良品率从92%提升至95%,初始阶段,数字孪生系统虽然能实时监测设备状态,但工程师仍需手动分析数据并调整参数,导致响应时间超过30分钟,项目组通过以下设计优化了人机协作:
-
最新热度持续上升环境监测热度持续攀升,相关应用不断深化 可视化界面:将复杂的孪生模型转化为直观的3D界面,工程师可以通过拖拽方式调整参数,系统实时显示调整后的模拟结果,当工程师将“光刻机曝光时间”从2.5秒调整为2.3秒时,界面会立即显示良品率预测从93.2%降至92.8%。
-
智能推荐:系统基于历史数据和机器学习模型,为工程师提供参数调整建议,当检测到某台光刻机的对准误差超过阈值时,系统会推荐“调整对准镜头温度”或“校准传感器”等方案,并显示每种方案的成功率和耗时。 2026年在线教育与无障碍设计热度持续上升,相关产业迎来新发展
-
绿色产品链与远程办公及科技创新热度持续攀升,相关技术取得新突破 自主决策:对于常规问题,系统可直接执行优化操作,当检测到某台蚀刻机的气体流量异常时,系统会自动调整阀门开度,并将调整记录发送给工程师审核。

这些设计使得工程师的工作效率提升了3倍,良品率在6个月内达到95.1%,更关键的是,工程师从“数据操作者”转变为“决策者”,能够专注于解决复杂问题,而非重复性操作。
群体智能的可持续性:从项目到生态
数字孪生技术的群体智能机制不仅适用于单个项目,还能推动整个行业的生态建设,峰会上分享的“工业数字孪生开源社区”案例,展示了这一过程的可行性。
该社区由华为、西门子、达索系统等企业联合发起,旨在通过开源代码、共享数据集和协作开发,降低数字孪生技术的应用门槛,截至2026年3月,社区已吸引超过500家企业和1.2万名开发者参与,贡献了200多个开源组件,覆盖数据采集、模型训练、可视化等全链条。
社区的运作机制包括:
-
模块化设计:将数字孪生系统拆分为独立模块,设备数据采集模块”“物理模型求解模块”“可视化渲染模块”,开发者可以按需组合使用。
-
贡献激励机制:根据代码质量、使用频率和社区反馈,为贡献者分配“数字孪生积分”,积分可兑换社区服务或企业赞助的奖品。
-
标准制定:社区联合IEEE等标准组织,制定数字孪生数据的格式、接口和安全规范,确保不同系统的互操作性。
一家小型自动化企业通过社区获取了“机械臂运动控制模块”和“碰撞检测模块”,仅用2周就开发出了一套数字孪生系统,成本比自主开发降低80%,这种“众包式”开发模式,正在重塑工业软件的创新生态。
挑战与未来:群体智能的边界
尽管群体智能在数字孪生领域展现出巨大潜力,但其发展仍面临诸多挑战,数据共享的法律边界尚未明确——2026年1月,欧盟出台的《工业数据法案