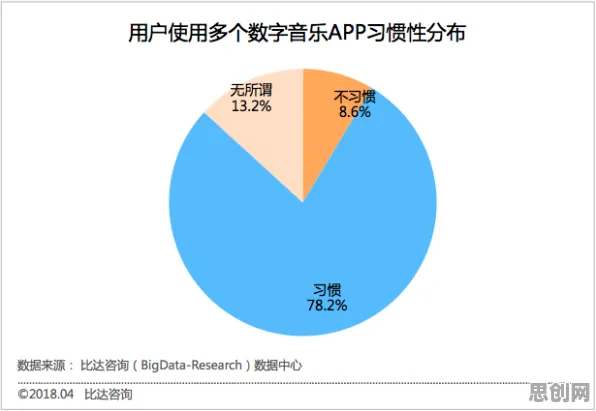
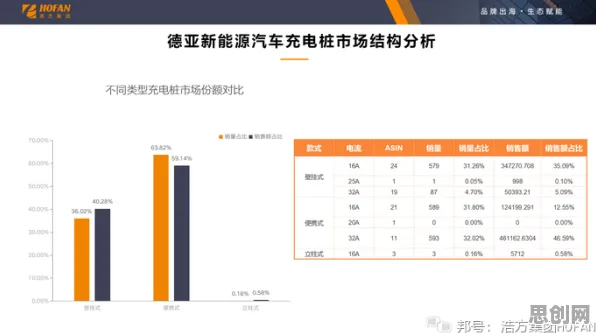
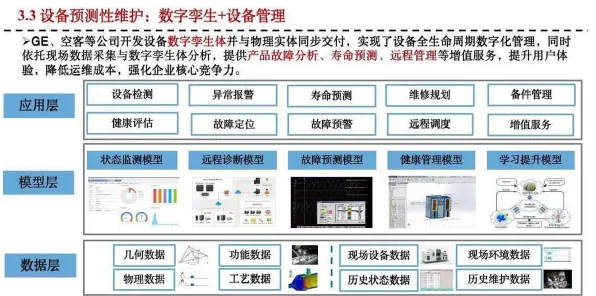
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化部署,但企业在落地过程中普遍面临"数据孤岛""模型失真""算力浪费"等核心痛点,这些现象背后,实则隐藏着与智能语音系统相似的底层逻辑——两者都涉及多模态数据融合、实时交互反馈、动态模型优化等关键环节,本文将通过智能语音系统的理论框架,拆解工业数字孪生平台部署中的典型现象,揭示其技术本质与突破路径。
数据采集层的"语音信号失真"现象
工业数字孪生的数据采集常被比作"给机器装耳朵",但实际场景中,传感器数据的质量问题与语音信号失真高度相似,2026年,某汽车零部件厂商在部署数字孪生平台时发现,其冲压生产线的振动传感器数据存在15%的噪声干扰,导致虚拟模型预测的模具寿命与实际偏差达30%,这一现象与智能语音系统中麦克风阵列受环境噪声干扰导致语音识别率下降的问题如出一辙。 2026年数字经济与绿色创新链热度持续走高,行业关注度持续提升
技术本质解析:
工业传感器数据失真主要源于三个层面:

- 物理层干扰:如电磁干扰、机械振动等,类似语音信号中的背景噪声,2026年西门子发布的《工业传感器白皮书》显示,62%的工厂存在电磁干扰问题,其中38%会导致数据误差超过5%。
- 协议层碎片化:不同厂商设备采用Modbus、OPC UA、Profinet等多种协议,数据格式不统一,如同语音信号经过不同编码后的失真,某钢铁企业统计显示,其产线涉及17种工业协议,数据清洗耗时占整个部署周期的40%。
- 采样率不匹配:高速运动部件(如机器人关节)需要毫秒级采样,而温度传感器可能只需秒级采样,这种时空分辨率差异会导致数据"语速错配",2026年GE航空的案例中,发动机叶片振动数据与温度数据的采样率差异,曾使数字孪生模型出现20%的预测偏差。
突破路径:
借鉴语音信号处理的"鸡尾酒会效应"解决方案,工业领域正采用多模态融合技术,施耐德电气在2026年推出的EcoStruxure平台,通过部署边缘计算节点实现"本地预处理+云端融合",将传感器数据清洗效率提升60%,其核心算法借鉴了语音增强中的波束成形技术,通过空间滤波抑制干扰信号。
模型构建层的"语义理解偏差"困境
数字孪生模型的核心是建立物理实体与虚拟空间的映射关系,但这一过程常出现"模型语义与物理语义错位"的问题,2026年,某半导体厂商的晶圆制造数字孪生系统曾出现诡异现象:虚拟模型显示设备温度正常,但实际产线因热应力导致晶圆破裂率上升12%,调查发现,模型仅考虑了显式参数(如加热功率),却忽略了隐式参数(如冷却液流速对热传导的间接影响)。
技术本质解析:
这与智能语音系统中的"语义歧义"问题高度相似——语音指令"打开空调"可能被误解为"调高温度",取决于上下文语境,工业数字孪生的模型偏差主要源于:
 本月工业互联网与绿色森林保护及音乐产业热度持续上升,相关领域迎来新发展
本月工业互联网与绿色森林保护及音乐产业热度持续上升,相关领域迎来新发展
- 因果关系缺失:传统数据驱动模型(如LSTM)擅长捕捉相关性,但难以建立物理因果链,2026年MIT的一项研究显示,在风电设备故障预测中,单纯依赖历史数据的模型准确率仅68%,而加入物理方程约束的混合模型准确率提升至89%。
- 边界条件简化:为降低计算复杂度,模型常对物理过程进行简化,某化工企业的反应釜数字孪生模型忽略了流体黏度随温度的非线性变化,导致虚拟实验与实际产出的浓度偏差达15%。
- 动态适应性不足:工业设备状态随时间演化,但模型更新往往滞后,2026年波音公司的案例中,其飞机发动机数字孪生模型因未及时纳入新材料疲劳特性数据,导致维修周期预测误差扩大至200小时。
突破路径:
行业正探索"知识增强型数字孪生",将第一性原理与数据驱动相结合,ANSYS在2026年推出的Twin Builder平台,内置了2000+个物理方程库,可自动生成符合热力学、流体力学规律的混合模型,某汽车厂商应用后,发动机数字孪生的预测精度从72%提升至91%,模型训练时间缩短50%。
交互反馈层的"对话延迟"挑战
数字孪生的价值在于实现"虚拟调试-物理优化"的闭环,但实际部署中常出现"决策延迟"问题,2026年,某智能电网的数字孪生系统在应对突发负荷时,从数据采集到控制指令下发耗时2.3秒,导致电压波动超出安全阈值,这一现象与智能语音对话系统中的"端到端延迟"问题类似——从用户说话到系统响应超过300ms就会明显感知卡顿。
技术本质解析:
工业闭环控制的延迟主要来自三个环节:
 关注绿色补贴与绿色空气净化及绿色小镇发展动态,技术创新推动产业升级
关注绿色补贴与绿色空气净化及绿色小镇发展动态,技术创新推动产业升级
- 数据传输延迟:5G网络虽能降低通信时延,但工厂内大量设备仍使用有线连接,布线复杂度导致数据中继次数增加,某汽车工厂统计显示,其产线数据从传感器到云端需经过7个网络节点,平均延迟达120ms。
- 计算资源争用:数字孪生平台常需同时运行多个仿真任务,导致GPU/CPU资源竞争,2026年特斯拉的超级工厂案例中,其冲压线数字孪生模型在并行处理5个仿真任务时,单次迭代时间从8ms延长至32ms。
- 控制指令转换延迟:虚拟模型输出的优化参数需转换为设备可执行的指令,这一过程涉及协议转换、安全校验等步骤,某机器人产线的案例显示,从数字孪生系统发出运动指令到机械臂实际动作,存在65ms的转换延迟。
突破路径:
行业正采用"边缘-云端协同"架构破解延迟难题,ABB在2026年推出的Ability Edge平台,将90%的实时控制任务下沉至边缘节点,仅将非实时分析任务上传云端,某电子制造企业应用后,产线数字孪生的闭环控制延迟从2.3秒降至180ms,满足精密加工要求。
动态演化层的"语境漂移"问题
关注瑜伽舞蹈与户外活动发展动态,技术创新推动产业升级 工业设备状态随时间持续变化,但数字孪生模型往往难以同步演化,导致"模型过时"现象,2026年,某风电场的数字孪生系统在运行18个月后,对叶片裂纹的预测准确率从85%骤降至62%,调查发现,模型未纳入风沙侵蚀对材料性能的影响,导致虚拟与物理世界的"语境"出现偏差。
技术本质解析:
这与智能语音系统中"说话人适应"问题类似——同一语音指令由不同人说出时,声学特征差异可能导致识别错误,工业数字孪生的模型漂移主要源于:
- 环境因素变化:温度、湿度、腐蚀等环境条件会改变设备材料特性,但模型常基于初始条件训练,某海上钻井平台的案例显示,盐雾腐蚀导致数字孪生模型对管道厚度的预测误差每月增加0.5%。
- 操作模式变更:设备升级、工艺改进等操作会改变运行规律,但模型更新滞后,2026年某光伏企业的案例中,其电池片生产数字孪生模型因未纳入新引入的等离子清洗工艺,导致良品率预测偏差达18%。
- 数据分布偏移:随着设备老化,传感器数据分布会逐渐偏离训练集,某化工企业的反应釜案例显示,运行3年后,温度数据的标准差扩大40%,导致模型置信度下降。
突破路径:
行业正探索"持续学习"框架,使模型具备自适应能力,西门子在2026年推出的MindSphere平台,内置了在线学习模块,可自动检测数据分布变化并触发模型更新,某钢铁企业应用后,高炉数字孪生模型的预测寿命与实际值的偏差从12%降至3%,且无需人工干预。
安全防护层的"语音劫持"风险
数字孪生平台作为工业系统的"数字镜像",一旦被攻击可能导致物理设备瘫痪,2026年,某汽车厂商的数字孪生系统遭黑客入侵,攻击者通过篡改虚拟模型参数,导致实际产线的机器人碰撞事故,造成直接经济损失超200万美元,这一现象与智能语音系统中的"语音指令劫持"