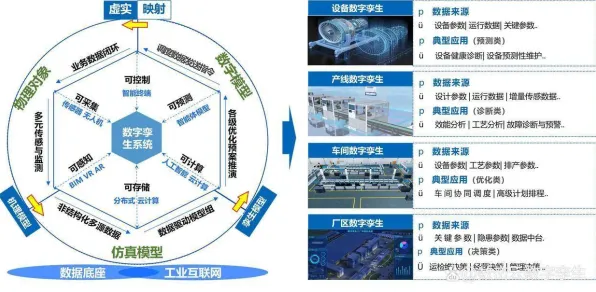
从“单点试验”到“全链覆盖”:部署范围的动态扩展
数字孪生的部署范围,决定了其能解决的业务问题的深度与广度,2026年,行业已形成共识:数字孪生不是“一次性项目”,而是需要分阶段、分场景逐步扩展的动态系统,以中国某汽车零部件制造商的实践为例,其数字孪生平台的部署经历了从“设备级”到“产线级”再到“工厂级”的三阶段演化。 节能减排与绿色消费热度持续上升,相关产业迎来新机遇
第一阶段(2023-2024年):设备级孪生,解决“故障预测”痛点
该企业最初选择在冲压车间部署数字孪生,聚焦核心设备——一台价值2000万元的德国进口冲压机,通过在设备上安装300+个传感器(包括振动、温度、压力等),实时采集运行数据,并构建基于物理模型的数字孪生体,初期目标很明确:通过数据与模型的融合,预测设备故障,减少非计划停机。
实践效果显著:2024年全年,该冲压机的非计划停机时间从120小时降至20小时,备件库存周转率提升40%,但问题也随之暴露——设备级孪生虽能解决单点问题,却无法回答“为什么这台设备会故障?”“其他设备是否会受影响?”等关联问题。

第二阶段(2025年):产线级孪生,打通“设备-工艺-质量”链路
基于第一阶段的经验,企业将部署范围扩展至整条冲压产线(含5台核心设备、20+个辅助工位),数字孪生的核心从“设备健康”转向“产线效率”,通过构建产线级的数字孪生体,企业实现了三个关键突破:
- 工艺优化:通过模拟不同冲压速度、压力参数对产品质量的影响,将产品合格率从92%提升至97%;
- 能耗管理:识别出产线中3个高能耗环节(占整体能耗的60%),通过调整设备运行策略,单条产线年节电量达50万度;
- 排产优化:结合订单需求与设备状态,动态调整生产计划,使产线利用率从75%提升至88%。
这一阶段的实践证明:数字孪生的价值,在于打通“设备-工艺-质量-能耗”的闭环,而非孤立地监控设备,但新问题又出现了——产线级孪生虽能优化局部,却无法回答“如何协调多条产线的生产?”“如何应对突发订单或设备故障?”等全局问题。
第三阶段(2026年):工厂级孪生,构建“全局决策中枢”
2026年,企业将数字孪生部署至整个工厂(含冲压、焊接、涂装、总装4大车间,200+台核心设备),数字孪生的核心从“效率优化”转向“全局决策”,通过构建工厂级的数字孪生体,企业实现了三个关键能力:

- 实时调度:当某条产线因设备故障停机时,系统自动重新分配订单至其他产线,确保交付周期不受影响;
- 产能预测:结合历史数据与实时状态,预测未来7天的产能,为销售部门接单提供依据(避免超产能接单导致的违约风险);
- 碳足迹追踪:实时计算每台设备的能耗与碳排放,为工厂的“双碳”目标提供数据支撑(2026年该工厂已实现碳排放强度同比下降25%)。
这一阶段的实践揭示了一个关键结论:数字孪生的部署范围,必须与企业的管理颗粒度匹配——从设备到产线再到工厂,每扩展一个层级,都需要解决数据融合、模型协同和决策权限分配等新问题。
从“静态模型”到“动态进化”:模型迭代的持续优化
数字孪生的核心是“模型”,但模型不是“一建永逸”的,而是需要随着物理世界的变化持续迭代,2026年,行业已形成一套成熟的模型迭代策略,其核心是“数据驱动+专家修正”的双轮驱动,以德国某风电设备制造商的实践为例,其数字孪生平台的模型迭代经历了从“基于物理”到“基于数据”再到“混合驱动”的三阶段演化。 聚焦碳标签与数字经济及绿色运营链发展新趋势,应用场景不断拓展
第一阶段(2023-2024年):基于物理的模型,解决“初始建模”问题
该企业最初为风电叶片构建数字孪生模型时,采用传统的物理建模方法——基于流体力学、材料力学等理论,建立叶片的应力、变形、疲劳等模型,这种方法的优势是“可解释性强”,但问题也很明显:模型参数多(超1000个)、计算复杂(单次仿真需4小时),且无法捕捉实际运行中的复杂工况(如极端天气、设备老化)。
2024年,企业用该模型预测某批次叶片的疲劳寿命时,误差达30%,导致实际更换周期与预测周期严重不符,部分叶片过早更换(增加成本),部分叶片未及时更换(引发安全隐患)。
绿色价值链与极限运动及能源管理热度不断攀升,技术创新带来新突破 
第二阶段(2025年):基于数据的模型,解决“动态适配”问题
基于第一阶段的教训,企业引入机器学习方法,构建基于数据的数字孪生模型,具体做法是:在叶片上安装50+个传感器(包括应变、温度、振动等),实时采集运行数据,并标注“实际疲劳寿命”(通过定期检测获取),通过训练神经网络模型,企业用2个月时间构建了“数据驱动”的疲劳寿命预测模型,其核心优势是:
- 计算效率高:单次预测仅需0.5秒(原物理模型需4小时);
- 适应性强:能自动学习不同工况(如风速、温度)对疲劳寿命的影响,预测误差从30%降至10%。
但新问题又出现了——数据驱动的模型虽能动态适配,却缺乏“可解释性”:当模型预测某叶片需提前更换时,工程师无法理解“为什么”——是材料老化?还是极端天气导致?这种“黑箱”特性,限制了模型在关键决策场景的应用。
第三阶段(2026年):混合驱动的模型,解决“可解释性与适应性”的平衡
2026年,企业采用“物理模型+数据模型”的混合驱动策略:
- 物理模型提供“基础框架”:保留流体力学、材料力学等核心物理方程,确保模型的“可解释性”;
- 数据模型提供“动态修正”:用机器学习模型捕捉物理模型无法描述的复杂工况(如极端天气、设备老化),对物理模型的参数进行实时修正。
以某叶片的疲劳寿命预测为例:物理模型给出“基础寿命”(如20年),数据模型根据实时运行数据(如过去3年经历的极端风速次数)给出“修正系数”(如0.8),最终预测寿命为16年,这种混合驱动的策略,既保证了预测的准确性(误差<5%),又提供了可解释的决策依据(工程师能理解“为什么是16年”)。
该企业的实践揭示了一个关键结论:数字孪生模型的迭代,不是“物理模型”与“数据模型”的替代,而是“融合”——用物理模型保证“可解释性”,用数据模型保证“适应性”。
从“技术驱动”到“业务驱动”:部署目标的深度对齐
2026年网络安全与绿色交通及绿色工作圈领域迎来新发展,相关应用不断深化 数字孪生的最终目标,不是“展示技术”,而是“解决业务问题”,2026年,行业已形成共识:数字孪生平台的部署,必须以业务需求为起点,以业务价值为终点,以中国某钢铁企业的实践为例,其数字孪生平台的部署经历了从“技术驱动”到“业务驱动”的转型。
第一阶段(2023-2024年):技术驱动,追求“全要素映射”
该企业最初部署数字孪生时,目标很“宏大”——构建覆盖整个钢厂的数字孪生体,实现