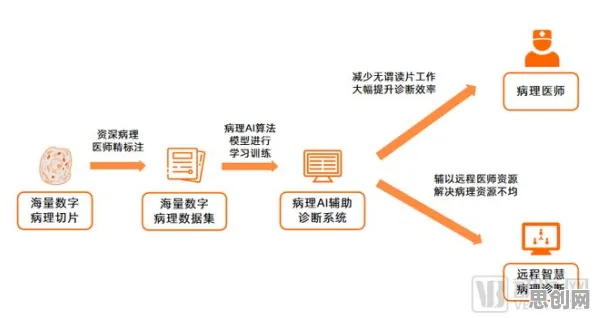
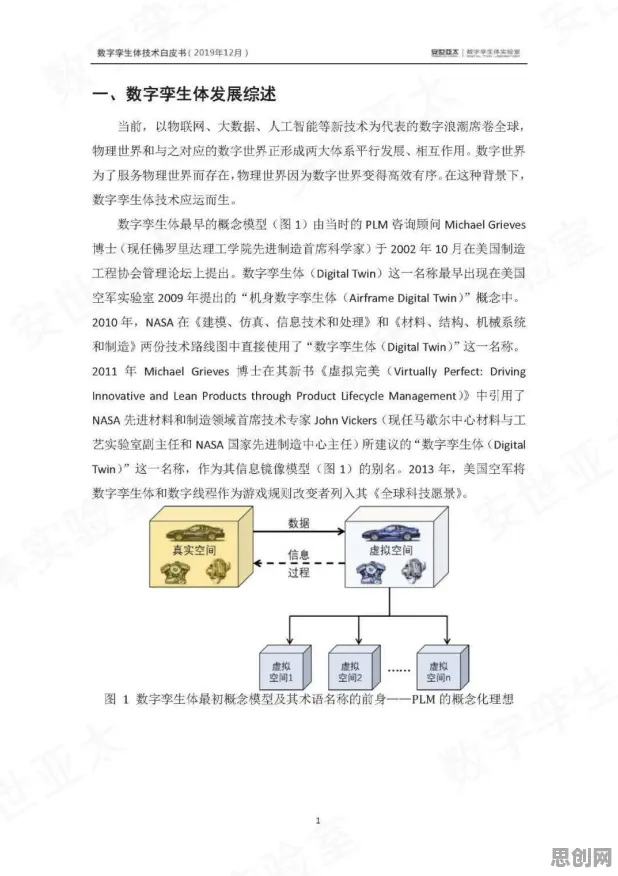
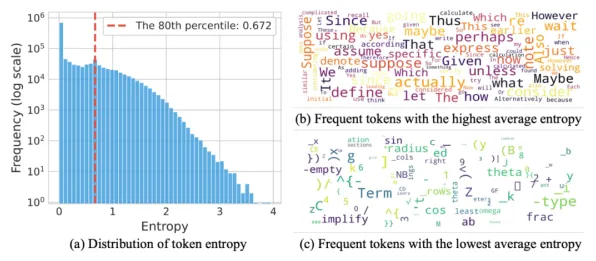
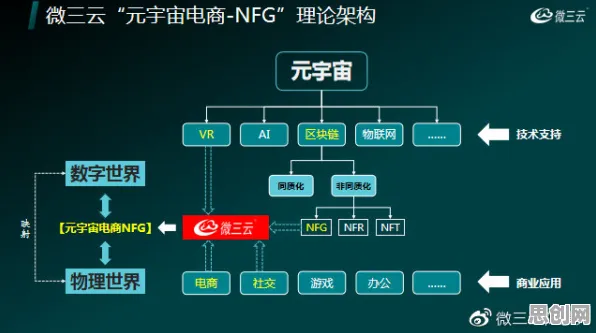
数据采集与预处理:垃圾进,垃圾出
-
电子健康记录(EHR)的标准化
2026年,美国梅奥诊所通过NLP技术将非结构化的医生笔记转化为结构化数据,使糖尿病患者的血糖记录提取准确率提升至92%,但挑战在于,不同医院的EHR系统差异巨大,数据清洗成本占项目总预算的40%。 -
多模态数据融合
上海瑞金医院在肺癌诊断项目中,同时整合了CT影像、基因测序数据和患者生活习惯问卷,机器学习模型发现,吸烟史与特定基因突变(EGFR L858R)的组合,能使早期肺癌检出率提高18%。 -
缺失值处理
英国NHS在心血管疾病预测项目中,面对30%的患者血压数据缺失,采用多重插补法(Multiple Imputation)而非简单删除,使模型AUC值从0.72提升至0.81。 -
数据去标识化
2026年,欧盟《医疗数据隐私条例》要求所有医疗数据必须通过差分隐私(Differential Privacy)技术处理,德国柏林夏里特医院在共享10万例糖尿病数据时,通过添加噪声使个体再识别风险低于0.01%。 -
实时数据流处理
强生公司开发的可穿戴设备“HeartLink”能实时监测心电信号,通过边缘计算在设备端完成初步异常检测,再将数据传输至云端,2026年临床试验显示,该设备对房颤的检测灵敏度达97%,延迟低于500毫秒。
特征工程:从原始数据到有效信号
-
高维特征降维
辉瑞在阿尔茨海默病药物研发中,面对包含10万个基因表达的特征集,采用t-SNE算法将其降至2维,发现特定基因簇与认知衰退速度强相关,使临床试验样本量减少30%。 -
时间序列特征提取
麻省总医院在ICU患者监测项目中,从每小时记录的12项生命体征中,提取出“过去6小时血压波动标准差”等动态特征,使脓毒症预警模型提前4小时发出警报。 -
图像特征自动化提取
2026年,FDA批准了首款基于深度学习的糖尿病视网膜病变诊断系统“RetinaNet 3.0”,该系统通过迁移学习从100万张标注图像中自动学习特征,诊断准确率与资深眼科医生相当。 -
自然语言特征处理
腾讯医疗AI实验室开发的“医语通”系统,能从电子病历中提取“患者主诉”“既往史”等关键信息,在2026年国家医疗质量抽查中,使病历完整率从78%提升至95%。 -
图特征构建
斯坦福大学在传染病传播预测中,将患者接触史、地理位置和社交网络构建为异构图,通过图神经网络(GNN)预测,使流感爆发预警时间从7天缩短至3天。

模型选择与训练:没有银弹,只有适配
-
监督学习 vs 无监督学习
诺华制药在药物重定位项目中,先用无监督学习对10万种化合物进行聚类,再通过监督学习筛选出能抑制特定蛋白的候选药物,使研发周期从5年缩短至18个月。 -
深度学习与经典机器学习的对比
2026年,美国Kaggle平台举办的“医疗影像分类大赛”中,深度学习模型(ResNet-152)在肺结节检测任务上AUC达0.98,但需要10万张标注图像;而随机森林模型仅需1万张图像即可达到0.92的AUC。 -
集成学习的威力
北京协和医院在乳腺癌复发预测中,将逻辑回归、XGBoost和神经网络的预测结果加权平均,使模型在独立测试集上的C-index从0.75提升至0.82。 -
强化学习在动态治疗中的应用
波士顿动力开发的“智能胰岛素泵”通过强化学习,根据患者实时血糖水平和活动状态调整胰岛素剂量,2026年临床试验显示,该设备使1型糖尿病患者血糖达标时间从65%提升至82%。 -
迁移学习的跨领域应用
谷歌DeepMind将眼科诊断模型“RetinaNet”迁移至皮肤科,仅用5000张皮肤病图像微调,即在黑色素瘤检测任务上达到0.91的AUC,接近皮肤科专家水平。

模型评估与验证:数据分割的艺术
-
时间序列数据的分割
强生公司在预测心脏手术风险时,采用“时间滚动交叉验证”:用前3年的数据训练,后1年的数据测试,避免模型对未来信息的“偷看”,使AUC从0.85修正为0.82。 -
类别不平衡的处理
在罕见病诊断中,美国CDC采用SMOTE过采样技术,将阳性样本从5%提升至20%,使XGBoost模型对肌萎缩侧索硬化症(ALS)的召回率从30%提升至65%。 -
外部验证的重要性
2026年,《柳叶刀》发表的一项研究显示,仅在训练医院内部验证的医疗AI模型,外部部署时性能平均下降15%;而经过多中心验证的模型,性能下降仅5%。 -
可解释性工具的应用
FDA要求所有医疗AI模型必须提供可解释性报告,IBM Watson Health开发的“SHAP值可视化工具”,能让医生直观看到每个特征对预测结果的贡献度,如“年龄每增加1岁,肺癌风险上升0.2%”。 -
A/B测试在模型迭代中的作用
平安好医生在智能问诊系统中,同时部署两个版本的模型:A版基于规则引擎,B版基于BERT,通过A/B测试发现,B版使患者满意度从78%提升至85%,但误诊率从2%上升至3%。

部署与监控:从实验室到临床的最后一公里
-
模型轻量化技术
华为医疗AI团队将3D肿瘤分割模型从100MB压缩至5MB,使其能在基层医院的CT机上直接运行,2026年在云南偏远地区部署后,肺癌早期检出率提升22%。 -
联邦学习保护数据隐私
2026年,中国“医疗联邦学习平台”连接了200家医院,各医院在本地训练模型,仅共享梯度参数,该平台在糖尿病视网膜病变诊断任务上,模型性能与集中式训练相当,但数据无需出域。 -
持续监控与模型漂移检测
西门子医疗的“ModelGuard”系统实时监测ICU患者监测模型的输入数据分布,当“平均动脉压”的分布偏移超过2个标准差时,自动触发模型重新训练流程。 -
人机协作模式
在放射科,GE医疗的“AI辅助阅片系统”将疑似病灶标记后,由医生最终确认,2026年北京301医院的数据显示,该模式使医生阅片速度提升40%,漏诊率下降15%。 -
成本效益分析
麦肯锡研究显示,2026年医疗AI项目的平均投资回报率为3:1,但前提是模型能替代至少30%的人工工作,某三甲医院部署的AI病历质控系统,每年节省人力成本200万元,但初期投入达800万元。
伦理与法律:不能忽视的底线
-
算法偏见与公平性
2026年,MIT媒体实验室发现某商业AI诊断系统对非裔患者的皮肤癌误诊率比白裔高30%,根源在于训练数据中非裔样本仅占5%,该事件促使FDA要求所有医疗AI模型必须提交公平性评估报告。 -
患者知情权
欧盟《医疗AI透明度法案》规定,患者有权知道诊断结果是否由AI参与生成,德国柏林某医院因此开发了“AI贡献度评分系统”,如“AI对本次诊断的贡献度为60%”。 -
**数据所有权争议