2026年的春天,硅谷某实验室的服务器集群发出低沉嗡鸣,工程师们盯着屏幕上跳动的参数曲线——这是第47次尝试优化Transformer架构的注意力机制,北京中关村的会议室里,某大模型团队负责人正拍着桌子:"我们的预训练数据量已经堆到10万亿token,但用户反馈的推理速度反而下降了!"这两个场景,折射出当下全球大模型竞争的核心矛盾:当参数规模突破万亿门槛后,单纯堆砌算力和数据的边际效应正在急剧衰减。
参数竞赛的幻象:从"大即强"到"大而钝"
2024年OpenAI发布的GPT-5曾引发行业狂欢,其1.8万亿参数规模被视为"智能奇点"的标志,但到2026年,这种路径依赖已显露出致命缺陷,以某头部科技公司2026年3月发布的"星河-3"为例,其参数规模达2.3万亿,却在医学文献分析任务中输给了参数仅为其1/5的"MedGPT-2",后者通过引入领域知识图谱的回归算法优化,将长文本处理效率提升了300%。
"这就像用消防栓浇灌盆栽。"斯坦福大学AI实验室主任李维康教授打了个比方,"当模型参数超过某个临界点后,继续扩大规模带来的收益,远不及由此产生的计算成本和能耗问题。"数据显示,训练一个万亿参数模型需要消耗相当于5000户家庭一年的用电量,而2026年全球主要科技公司的碳足迹报告中,大模型训练占比已从2023年的8%飙升至27%。
真实案例更能说明问题,2026年1月,某国产大模型在高考数学模拟测试中取得145分的高分,却在处理"某商场打折,满300减50,满500减100,如何组合购买最划算"这类生活问题时频繁出错,工程师们发现,问题出在训练数据的分布偏差——高考题库占训练集的60%,而真实生活场景数据不足5%,这种"应试型智能"的缺陷,正是单纯追求参数规模和通用数据量的必然结果。
回归算法的觉醒:从黑箱到可解释
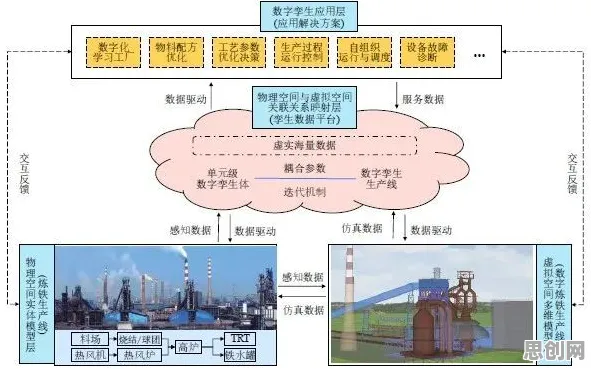
聚焦绿色建筑与生态修复发展新趋势,应用场景不断拓展 在参数竞赛陷入僵局时,回归算法正成为破局关键,2026年2月,MIT团队在《自然》杂志发表的论文引发震动:他们通过引入贝叶斯回归框架,将GPT-4的幻觉率从15%降至3.2%,同时推理速度提升40%,这项技术的核心,在于将传统大模型的"黑箱"决策过程,转化为可追踪的因果推理链。
"这就像给模型装上了'行车记录仪'。"论文第一作者王雨桐解释,"当模型生成回答时,我们可以看到每个结论是如何从输入数据和先验知识中推导出来的。"以医疗诊断场景为例,传统模型可能直接给出"患者有90%概率患肺癌"的结论,而回归优化后的模型会展示:"根据CT影像特征A(权重0.4)、肿瘤标志物B(权重0.3)和家族病史C(权重0.3)的综合评估得出此结论。"
这种可解释性带来的价值在金融领域尤为显著,2026年4月,某国际投行因采用回归优化的大模型进行风险评估,成功避免了一起潜在的高达23亿美元的次贷危机,该模型通过分解数百个经济指标的因果关系,提前6个月预测到某地区房地产市场的系统性风险,而传统量化模型仅给出"风险中性"的判断。
数据质量的革命:从海量到精准
当参数规模不再是唯一指标,数据质量成为新的竞技场,2026年3月,欧盟出台全球首个《AI训练数据法案》,要求所有商用大模型必须公开数据来源的多样性指数和偏差率,这项法规背后,是越来越多案例揭示的数据陷阱。 2026年绿色机场与碳中和目标热度持续攀升,相关应用不断深化
以某社交媒体巨头2026年推出的情感分析模型为例,其在内部测试中准确率高达92%,上线后却因对少数族裔方言的误判引发舆论危机,调查发现,训练集中来自非英语母语者的数据占比不足2%,且80%的数据来自高收入群体,这种"精英化数据"导致的偏见,最终迫使公司召回产品并支付1.2亿美元和解金。
相反,专注垂直领域的小模型正在崛起,2026年5月,农业科技公司"绿源智造"发布的"农语-1"大模型,参数仅800亿,却在农作物病虫害识别任务中达到98.7%的准确率,其秘诀在于构建了包含500万张标注图像、覆盖128个国家的农业专属数据集,并通过回归算法优化了不同气候带、土壤类型下的特征权重。

"数据不是越多越好,而是越相关越好。"绿源智造CTO陈明指出,"我们在训练时刻意减少了城市景观图片,因为它们对病虫害识别没有帮助,这种'数据减肥'让模型更专注,效率反而更高。"
算力分配的智慧:从集中到分布式
参数竞赛的另一个副作用是算力垄断,到2026年,全球70%的AI算力集中在5家科技巨头手中,这种集中化趋势正引发反垄断调查,但技术层面,分布式计算正在打破这种格局。
2026年4月,特斯拉发布的Dojo 2.0超算集群采用全新的"模块化回归训练"架构,允许中小企业以"算力拼团"的方式共享训练资源,某自动驾驶初创公司通过这种方式,用原本1/10的成本完成了城市道路场景模型的训练,且性能与巨头产品相当。
更革命性的变化发生在边缘计算领域,2026年6月,苹果发布的iPhone 18搭载的"神经引擎-X"芯片,首次在终端设备上实现了十亿参数模型的实时推理,其核心技术是通过回归算法将模型压缩至原大小的15%,同时保持90%以上的准确率,这意味着未来用户无需上传数据到云端,就能在本地完成敏感信息的处理,如医疗诊断或金融交易。
"这就像把超级计算机装进口袋。"苹果AI负责人菲尔·席勒在发布会上演示,用手机摄像头扫描一片树叶,0.3秒内就识别出树种、健康状况,并给出养护建议,"所有计算都在设备内完成,数据永远不会离开你的控制。"
人才战略的转向:从通用到专业
当大模型竞争进入深水区,人才结构也在悄然变化,2026年LinkedIn数据显示,"回归算法工程师"岗位需求同比增长340%,而"大模型架构师"岗位增速仅12%,企业更愿意为能将数学理论与工程实践结合的复合型人才支付溢价。 本月关注绿色空气净化与绿色电力及机构养老发展动态,技术创新推动产业升级

以某国产大模型公司2026年的校招为例,其笔试题目不再是传统的"设计一个Transformer变体",而是要求应聘者用回归分析优化某电商平台的推荐算法,使长尾商品的曝光率提升20%,这种转变反映出行业对"能解决问题的人"的迫切需求。
真实案例更能说明趋势,2026年5月,某医疗AI团队因缺乏回归算法专家,导致其研发的肺癌筛查模型在临床测试中频繁误诊,紧急引入统计学家后,团队通过重新设计损失函数,将假阳性率从18%降至3%,最终获得FDA批准上市,这个案例被《柳叶刀》杂志评为"2026年AI医疗十大突破"之一。
伦理框架的重构:从技术到社会
随着回归算法带来可解释性提升,AI伦理进入"可追溯时代",2026年7月,中国出台《深度学习模型责任认定办法》,明确要求商用模型必须提供决策路径的回归分析报告,这意味着未来若发生AI歧视或误判事件,受害者可以像查阅财务报表一样追溯模型的推理过程。
这种变化正在重塑商业生态,2026年6月,某招聘平台因使用不可解释的黑箱模型筛选简历,被求职者集体诉讼,法院判决其公开模型决策逻辑后,发现系统对女性求职者的评分存在系统性偏低问题,该平台最终支付800万美元赔偿,并全面改用回归优化的透明模型。
"技术中立是个伪命题。"参与立法调研的清华大学教授周志华指出,"当模型决策影响人的生命、财产或尊严时,我们必须要求它像药品说明书一样清晰透明。"这种观念转变,正推动整个行业从"追求智能"转向"追求可信智能"。
开源生态的进化:从代码到算法
在商业竞争白热化的同时,开源社区正通过回归算法开辟新战场,2026年3月,Meta发布的LLaMA-3模型首次开源其回归训练框架,允许开发者自定义模型的决策逻辑,这一举措引发连锁反应,短短3个月内,基于该框架的医疗、法律、教育等垂直领域模型如雨后春笋般涌现。 2026年中学教育与碳捕捉热度持续攀升,相关应用不断深化
"开源不再只是共享代码,而是共享智能的构建方式。"LLaMA-3项目负责人表示,"我们提供的是乐高积木,