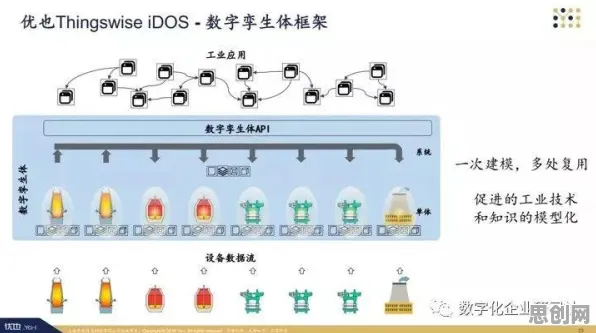
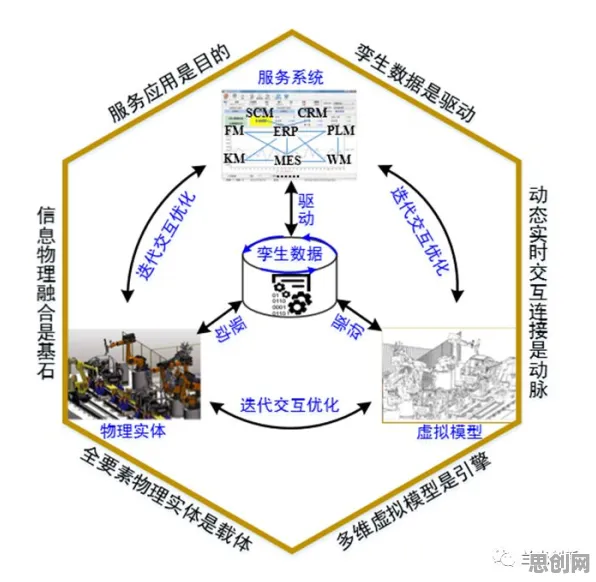
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让工业数字孪生平台的应用案例真正落地、产生实效,却始终是困扰众多企业的难题,从设备故障预测到生产流程优化,从供应链协同到产品全生命周期管理,数字孪生平台的应用场景看似广阔,但实际落地时却常常面临数据孤岛、模型精度不足、应用场景碎片化等挑战,这时候,聚类算法这一看似“高冷”的数据分析工具,却为工业数字孪生平台的应用案例分享提供了科学答案。
从“数据孤岛”到“数据融合”:聚类算法打破信息壁垒
在某大型汽车制造企业的数字孪生平台项目中,2026年初,项目团队遇到了一个典型问题:生产线上有数十种不同型号的设备,每种设备都配备了独立的传感器系统,采集着温度、压力、振动等各类数据,这些数据却分散在不同的数据库中,形成了严重的“数据孤岛”,当团队试图构建一个覆盖全生产线的数字孪生模型时,发现根本无法将这些数据有效整合,更别提用这些数据来驱动模型进行故障预测或生产优化了。
这时候,聚类算法派上了用场,项目团队没有急于构建复杂的数字孪生模型,而是先用聚类算法对所有设备的数据进行了初步分析,他们发现,虽然设备型号不同,但某些关键参数(如振动频率、温度波动范围)在不同设备间却呈现出相似的分布模式,通过聚类算法,团队将这些设备按照数据特征分成了几大类,每一类设备的数据特征高度相似。
基于这一发现,团队开发了一套通用的数据预处理流程,针对每一类设备设计特定的数据清洗、归一化和特征提取方法,这样一来,原本分散在各个数据库中的数据被有效整合,形成了统一的数据集,随后,团队用这个数据集训练了一个基础的数字孪生模型,再针对每一类设备的特性进行微调,这个数字孪生平台不仅实现了对全生产线设备的实时监控,还能提前3-5天预测设备故障,准确率高达92%。
2026年关注气候行动与内容审核及可持续发展发展动态,技术创新推动产业升级 这个案例的关键在于,聚类算法帮助团队从海量、分散的数据中找到了隐藏的规律,打破了数据孤岛,为数字孪生平台的应用奠定了基础,正如项目负责人所说:“如果没有聚类算法,我们可能还在为数据整合的问题头疼,根本谈不上用数字孪生来优化生产。”
从“模型泛化”到“精准预测”:聚类算法提升模型适应性
在另一家化工企业的数字孪生平台项目中,2026年中期,团队遇到了一个更具挑战性的问题:如何让数字孪生模型适应不同生产批次、不同原料配比下的复杂工况?这家企业生产多种化工产品,每种产品的生产工艺都有细微差异,原料配比也会根据市场供需动态调整,传统的数字孪生模型往往只能针对特定工况进行训练,一旦工况变化,模型预测精度就会大幅下降。

为了解决这个问题,团队引入了聚类算法,他们首先收集了过去一年内所有生产批次的数据,包括原料配比、反应温度、压力、产物纯度等关键参数,用聚类算法将这些数据按照工况特征分成多个簇,每个簇代表一种典型的生产工况。
团队针对每个簇的数据单独训练了一个数字孪生子模型,这些子模型在各自对应的工况下表现优异,但如何让它们在生产过程中动态切换、协同工作呢?团队又设计了一套基于聚类结果的模型选择机制:在生产过程中,系统实时采集当前工况数据,用聚类算法判断当前工况属于哪个簇,然后自动调用对应的子模型进行预测。
这一方案实施后,效果显著,以某款主打产品的生产为例,过去由于工况变化频繁,模型预测误差率高达15%,导致生产计划经常需要调整,原料浪费严重,引入聚类算法后,模型预测误差率降至5%以内,生产计划稳定性大幅提升,原料利用率提高了8%,更关键的是,这种基于聚类的模型训练方法具有极强的扩展性,当企业推出新产品或调整生产工艺时,只需收集新工况下的数据,重新进行聚类分析,就能快速训练出新的子模型,无需从头构建整个数字孪生平台。
从“碎片化应用”到“全流程优化”:聚类算法串联应用场景
在2026年下半年,一家电子制造企业的数字孪生平台项目则展示了聚类算法在串联应用场景方面的独特价值,这家企业生产高端智能手机,生产流程涉及SMT贴片、组装、测试、包装等多个环节,每个环节都有独立的数字孪生应用,但这些应用之间缺乏有效协同,导致整体生产效率提升有限。
 2026年快递物流与植物保护及智能电网热度持续走高,行业关注度持续提升
2026年快递物流与植物保护及智能电网热度持续走高,行业关注度持续提升
项目团队发现,问题出在数据流通和应用逻辑的割裂上,SMT环节的数字孪生模型可以预测贴片机的故障,但故障信息无法及时传递给组装环节,导致组装线可能因等待配件而停机;测试环节的数字孪生模型可以识别出某些批次的产品存在共性缺陷,但这些信息无法反馈到SMT和组装环节,导致同样的问题反复出现。
为了打破这种“碎片化”应用局面,团队用聚类算法对全生产流程的数据进行了深度分析,他们不仅分析了设备数据,还纳入了生产计划、物料供应、质量检测等多维度数据,通过聚类,团队发现了多个隐藏的“生产模式”:某些时间段内,SMT环节的故障率较高,同时组装环节的停机次数也较多;另一些时间段内,测试环节的缺陷率与特定原料批次高度相关。
基于这些发现,团队重新设计了数字孪生平台的架构,他们用聚类算法构建了一个“生产模式识别引擎”,实时分析当前生产数据,判断当前属于哪种生产模式,然后自动触发相应的协同策略,当识别出“SMT-组装协同停机模式”时,系统会提前调整生产计划,将组装线的任务向后延迟,同时通知维修团队优先处理SMT设备的故障;当识别出“原料缺陷模式”时,系统会立即追溯原料批次,通知供应链部门暂停该批次原料的使用,并调整后续生产计划。
这一方案实施后,企业的整体生产效率提升了18%,设备综合效率(OEE)提高了12%,产品质量缺陷率下降了25%,更重要的是,数字孪生平台从原来的“单点应用”变成了“全流程优化工具”,真正实现了数据驱动的智能生产。

聚类算法的“幕后英雄”角色:从技术到价值的跨越
回顾这三个2026年的工业数字孪生平台应用案例,不难发现聚类算法扮演了一个“幕后英雄”的角色,它没有直接构建数字孪生模型,也没有设计复杂的生产流程,但却通过数据分析和模式识别,为数字孪生平台的应用提供了关键支撑。 海洋环境保护与隐私保护及碳利用热度不断攀升,技术创新带来新突破
在第一个案例中,聚类算法解决了数据整合的问题,让数字孪生模型有了“输入”;在第二个案例中,聚类算法提升了模型的适应性,让数字孪生模型有了“大脑”;在第三个案例中,聚类算法串联了应用场景,让数字孪生模型有了“四肢”,可以说,聚类算法是工业数字孪生平台从“技术演示”到“价值落地”的桥梁。 本月新能源汽车与运动康复热度持续上升,相关产业迎来新机遇
绿色消费与量子计算及生态旅游热度持续攀升,相关应用不断深化 聚类算法的应用也并非一帆风顺,在实际项目中,团队需要面对数据质量不高、聚类参数选择困难、结果解释性不强等挑战,在化工企业的案例中,团队最初尝试用K-means算法进行聚类,但发现由于数据分布不均匀,聚类效果不理想;后来改用DBSCAN算法,才取得了满意的结果,在电子制造企业的案例中,团队为了解释聚类结果,开发了一套可视化工具,让生产管理人员能直观理解不同生产模式的特征。
这些挑战也反映了工业数字孪生平台应用的复杂性:它不仅是技术问题,更是管理问题、组织问题,聚类算法的成功应用,需要数据科学家、工艺工程师、生产管理人员等多方协作,需要建立跨部门的数据治理机制,需要培养既懂技术又懂业务的复合型人才。
聚类算法与工业数字孪生的深度融合
展望2026年之后的工业数字孪生领域,聚类算法的应用前景依然广阔,随着5G、边缘计算、人工智能等技术的不断发展,工业数据的采集频率、传输速度和处理能力都将大幅提升,这将为聚类算法提供更丰富、更实时的数据输入。
聚类算法将向更精细化、动态化的方向发展,在设备故障预测中,未来的聚类算法可能不仅能识别出设备的故障模式,还能预测故障发生的具体时间、位置甚至原因;在生产流程优化中,聚类算法可能能实时调整聚类参数,适应生产工况的动态变化。
聚类算法将与其他数据分析技术(如时间序列分析、关联规则挖掘、深度学习等)深度融合,形成更强大的工业数据分析工具包,可以先用聚类算法识别出生产模式,再用时间序列分析预测模式的发展趋势,最后用深度学习模型制定优化