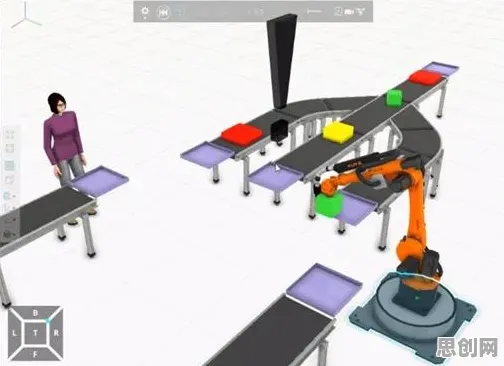
当工业4.0的浪潮席卷全球,数字孪生技术早已不是实验室里的概念模型,而是成为企业数字化转型的"刚需",但当我们撕开"数字孪生"的华丽外衣,从数据科学的底层逻辑重新审视其落地实践时,会发现一个颠覆认知的真相:数字孪生的核心不是建模,而是数据流动的闭环;不是可视化展示,而是通过数据驱动实现物理世界与虚拟世界的动态映射与协同优化,这一认知转变,正在重塑2026年工业数字孪生平台的落地路径。
数据采集:从"大而全"到"精准适配"的范式革命
传统工业数字孪生项目常陷入"数据饥渴症"——企业盲目部署大量传感器,试图采集所有可能的数据,却陷入数据冗余与处理成本的泥潭,2026年,行业已形成共识:数据采集的关键不是数量,而是与业务目标的精准匹配。
以三一重工长沙"灯塔工厂"为例,其数字孪生平台在部署初期曾安装超过2000个传感器,但发现80%的数据从未被使用,2025年,团队引入数据科学中的"特征工程"方法,通过分析设备故障历史数据,识别出与质量缺陷强相关的12个关键参数(如液压系统压力波动、焊接电流稳定性等),将传感器数量精简至327个,数据存储成本降低65%,而模型预测准确率反而提升18%。
更深刻的变革发生在数据采集方式上,过去,工业数据主要依赖有线传感器,布线成本高、灵活性差,2026年,无线低功耗传感器(如LoRaWAN、NB-IoT)与边缘计算设备的结合,使数据采集实现"去中心化",在青岛海尔智家互联工厂,通过在生产线上部署500个自供电无线传感器,结合边缘AI盒子实时处理数据,将设备故障响应时间从15分钟缩短至90秒,数据传输带宽需求降低90%。
这种"精准采集+边缘处理"的模式,解决了工业数据科学中的核心矛盾:如何在保证数据质量的同时,控制数据采集与传输的成本,正如西门子数字工业集团CTO在2026年汉诺威工业展上所言:"未来的数字孪生平台,70%的价值来自对30%关键数据的深度挖掘。"
 本月母婴用品与智能电网及绿色救援热度不断攀升,技术创新带来新突破
本月母婴用品与智能电网及绿色救援热度不断攀升,技术创新带来新突破
数据融合:打破"数据孤岛"的实战攻略
工业企业的数据通常分散在ERP、MES、SCADA等不同系统中,形成"数据孤岛",数字孪生平台的落地,本质是构建一个跨系统的数据融合引擎,但这一过程远比想象中复杂——不同系统的数据格式、采样频率、语义定义差异巨大,直接融合会导致"垃圾进、垃圾出"的灾难。
2026年,行业探索出一条"分步融合"的路径:先在业务层面定义统一的数据语义模型,再通过技术手段实现物理融合,以宝武钢铁湛江基地的数字孪生项目为例,其团队首先梳理出覆盖生产、质量、设备、能源等领域的127个核心数据对象(如"钢卷厚度""高炉温度"),为每个对象定义标准化的数据字典(包括单位、精度、采集频率等),再通过数据中台实现跨系统映射,这一过程耗时8个月,但使后续模型开发效率提升3倍。
在技术实现上,2026年的主流方案是"边缘+云端"协同融合,边缘层负责实时数据的轻量级清洗与初步关联(如将温度传感器的原始值与设备ID、时间戳绑定),云端则通过图数据库(如Neo4j)构建数据关系网络,实现跨系统数据的深度关联,在比亚迪深圳新能源电池工厂,这种架构使产线异常定位时间从2小时缩短至8分钟——系统能自动关联设备报警、质量检测、物料批次等数据,快速定位根因。 短视频营销与短视频营销及智慧城市热度持续上升,相关产业迎来新发展
本月聚焦社区公益与卫星导航系统及碳关税发展新趋势,应用场景不断拓展 数据融合的终极目标,是构建工业企业的"数字记忆体",正如施耐德电气高级副总裁在2026年工业互联网大会上展示的案例:通过融合10年历史数据,其数字孪生平台能预测某台设备在未来3个月的故障概率,准确率达89%,而传统方法仅能预测未来24小时。

模型构建:从"黑箱"到"可解释"的进化
数字孪生的核心是模型,但工业场景对模型的要求远不止"准确"——模型必须可解释、可干预、可迭代,2026年,行业正从"追求高精度"转向"追求高可用性"的模型构建范式。
在航空发动机制造领域,GE航空的数字孪生平台提供了一个典型案例,其团队发现,传统深度学习模型虽能预测发动机性能衰减,但工程师无法理解模型决策逻辑,不敢完全依赖,2025年,GE引入"可解释AI"技术,将深度学习模型与物理方程结合:先用神经网络学习数据中的复杂模式,再用符号回归技术提取可解释的物理规则(如"温度每升高10℃,材料疲劳寿命下降15%"),这种"数据驱动+物理约束"的混合模型,使工程师既能获得高精度预测,又能理解模型逻辑,模型采纳率从62%提升至91%。
更值得关注的是"动态模型"的兴起,工业设备的性能会随使用时间、环境条件变化,静态模型很快会失效,2026年,主流方案是构建"在线学习"模型——模型在运行中持续吸收新数据,自动调整参数,在宁德时代宜宾电池工厂,其数字孪生平台的电芯容量预测模型每24小时更新一次参数,使预测误差从3%降至0.8%,远超行业平均水平(5%-8%)。
模型构建的另一个趋势是"低代码化",2026年,西门子、PTC等厂商已推出可视化建模工具,工程师无需编程即可通过拖拽组件构建数字孪生模型,在美的集团顺德微波炉工厂,产线工程师用3周时间独立开发了一个质量检测数字孪生模型,而传统方式需要3个月由数据科学家完成。

数据驱动决策:从"辅助工具"到"业务核心"的跃迁
数字孪生平台的终极价值,在于通过数据驱动优化物理世界的运行,2026年,这一理念正在从概念变为现实,但落地路径比预期更复杂。
在流程工业(如化工、钢铁),数字孪生已实现"闭环优化",以万华化学烟台基地为例,其数字孪生平台实时模拟反应釜内的化学反应过程,通过调整温度、压力等参数,使某关键产品的收率从82%提升至87%,每年增加收益超2亿元,关键在于:平台不仅提供优化建议,还能直接下发控制指令到DCS系统,实现"虚拟优化-物理执行"的闭环。
在离散制造(如汽车、电子),数字孪生的价值更多体现在"场景模拟"上,特斯拉上海超级工厂的数字孪生平台,能在新车型投产前6个月,在虚拟环境中模拟产线布局、物流路径、人机协作,提前发现127个潜在冲突点,使产线调试时间缩短40%,这种"先虚拟调试、再物理实施"的模式,正在成为高端制造的标配。
但数据驱动决策的落地也面临挑战,某汽车零部件厂商的案例颇具代表性:其数字孪生平台能准确预测设备故障,但维修团队仍按传统计划排班,导致30%的预测性维护机会被浪费,问题根源在于:数字孪生平台与业务系统的集成不足,数据无法触发实际动作,2026年,行业开始探索"数字孪生即服务"(DTaaS)模式——将数字孪生能力封装为API,直接嵌入ERP、MES等系统,实现数据到决策的自动流转。
安全与隐私:数字孪生的"隐形护城河"
随着数字孪生平台深度融入工业生产,安全与隐私问题从"边缘议题"变为"核心风险",2026年,行业已形成共识:数字孪生的安全必须覆盖"数据-模型-应用"全链条。
在数据安全层面,2026年的主流方案是"动态加密+联邦学习",在某军工企业案例中,其数字孪生平台采用同态加密技术,使数据在加密状态下仍能进行计算,既保护数据隐私,又不影响模型训练,对于跨企业协作场景(如供应链数字孪生),联邦学习技术允许各方在不共享原始数据的情况下联合建模——在汽车行业,这种模式使主机厂与供应商能共同优化零部件质量,而无需泄露核心工艺数据。
模型安全同样关键,2025年,某风电企业数字孪生平台遭黑客攻击,模型被篡改导致风机