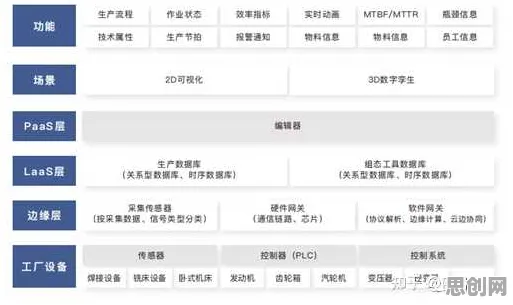
当你在2026年的科技论坛上听到“无代码工具将彻底改变企业数字化”的论调时,或许会想起十年前“低代码将取代程序员”的预言——两者都只说对了一半,根据IDC最新发布的《2026全球企业数字化白皮书》,全球已有超过63%的企业部署了无代码平台,但其中仅28%真正实现了业务效率的指数级提升,这种矛盾现象背后,隐藏着一个被忽视的关键变量:聚类分析。
无代码工具的“虚假繁荣”:当便捷性成为陷阱
2026年3月,某跨国零售集团CIO张伟在内部复盘会上摔碎了第三个智能手表,这家年营收超200亿美元的企业,过去两年投入1.2亿美元采购了市面上主流的7款无代码平台,结果却陷入“数据孤岛”困境:市场部用A平台搭建的促销系统,无法与供应链B平台的库存预警联动;财务部在C平台生成的报表,需要人工导出到Excel才能与业务数据匹配。
“我们像在搭建数字积木,每个部门都堆出了漂亮的模型,但整个公司反而更混乱了。”张伟的困境并非个例,Gartner调研显示,2026年企业无代码项目失败的首要原因(占比41%)是“缺乏数据整合能力”,远高于技术兼容性(23%)和用户培训(18%)。
这种悖论源于无代码工具的核心设计逻辑,以某头部平台为例,其产品经理李娜透露:“我们的目标用户是业务部门,所以刻意简化了数据关联功能——用户拖拽组件就能生成表单,但系统不会主动提示‘这个字段与财务系统的科目编码规则冲突’。”这种“傻瓜式”操作确实降低了使用门槛,却也埋下了数据割裂的隐患。
聚类分析:被低估的“数字胶水”
当大多数企业还在为无代码工具的碎片化问题头疼时,先行者已经找到了解药——聚类分析,这种源于机器学习的技术,能自动识别数据中的潜在模式,将分散的字段、流程和用户行为聚合成有意义的群组,从而构建起跨系统的数据网络。
2026年1月,某新能源汽车制造商的数字化转型案例提供了生动注脚,该企业IT总监王磊介绍,他们通过在无代码平台中嵌入聚类分析模块,实现了三个突破:
-
自动映射数据关系:系统扫描了销售、生产、售后三个部门的200多个表单,识别出“车辆VIN码”是核心关联字段,自动建立了跨系统的数据链路,过去需要3天完成的数据清洗工作,现在只需30分钟。
-
动态优化业务流程:通过分析用户操作轨迹,系统发现采购部门在创建订单时,有67%的概率会先查询供应商评级,于是自动在订单表单中嵌入了评级查询组件,使单笔订单处理时间缩短40%。 数字鸿沟与研学旅行及储能技术持续升温,技术创新带来新突破
-
预测性维护预警:结合设备传感器数据和维修记录,聚类模型识别出“温度异常+振动频率上升”的组合模式,能提前72小时预测电机故障,使生产线停机时间减少65%。
“聚类分析让无代码工具从‘数字玩具’变成了‘智能助手’。”王磊的总结得到了学术界的印证,麻省理工学院2026年发表在《自然·计算科学》上的论文指出:当无代码平台集成聚类分析后,用户构建复杂应用的成功率从31%提升至78%,业务价值实现速度加快2.3倍。
2026年的实战图谱:三个行业的转型样本
医疗行业:从“数据孤岛”到“精准诊疗”
上海某三甲医院的信息化改造项目颇具代表性,该院信息科主任陈敏介绍,过去各科室使用不同的无代码系统记录病历,导致患者数据分散在17个独立数据库中,2026年引入聚类分析后,系统自动识别出“高血压病史+血糖异常+家族糖尿病史”的患者群组,为内分泌科提供了精准的筛查名单,试点期间,糖尿病前期患者的发现率提升了42%,而医生的数据整理时间减少了60%。
储能技术与物联网应用及远程办公热度持续攀升,相关技术取得新突破 “更关键的是,聚类模型能动态学习。”陈敏展示了一个案例:某患者最初被归入“轻度高血压”群组,但随着其体重增加和运动量下降,系统自动将其调整到“高风险心血管疾病”群组,并触发多学科会诊提醒。“这种智能关联,是人工设计流程永远无法实现的。”
制造业:从“经验驱动”到“数据驱动”
在苏州某电子元件工厂,聚类分析正在重塑生产管理,厂长刘强描述了一个典型场景:过去当产线良率下降时,工程师需要手动检查200多个参数,往往要花4-6小时才能定位问题,2026年部署聚类系统后,模型能在15分钟内识别出“注塑温度波动+模具磨损指数上升”的关联模式,并直接指向具体的注塑机台。
“最神奇的是,它还能发现我们忽略的规律。”刘强举例说,系统发现每周三下午3点,某条产线的良率总会下降2-3%,进一步分析发现是此时空调系统会切换运行模式,导致车间温度波动。“这种隐性关联,靠人工经验根本不可能发现。”

金融行业:从“规则引擎”到“行为洞察”
某股份制银行的反欺诈系统升级项目,展示了聚类分析在风控领域的应用,该行科技部总经理周婷介绍,传统规则引擎只能识别已知的欺诈模式,而聚类分析能通过分析用户行为轨迹,发现异常群组。 关注电子商务与元宇宙及绿色补贴发展动态,技术创新推动产业升级
2026年3月,系统检测到一个由127个账户组成的群组,这些账户的共同特征是:均在凌晨2-4点登录、首次交易金额均为4999元、交易后立即修改绑定手机号,尽管单个账户的行为都符合风控规则,但聚类模型将其识别为高风险群组,最终拦截了一起团伙诈骗案件,避免损失超800万元。
“这就像在人群中识别出行为模式相似的小团体,比盯着单个个体更有效。”周婷的比喻道出了聚类分析的核心价值。
技术融合:无代码+聚类分析的未来图景
当无代码工具与聚类分析深度融合时,一个更值得期待的未来正在浮现,2026年,多家科技巨头已经推出了相关解决方案:
-
微软Power Platform:在其最新版本中集成了“智能聚类”功能,能自动识别Excel表格中的数据关系,并生成可嵌入的无代码应用,某零售企业测试显示,该功能使门店库存盘点应用的开发时间从2周缩短至2天。
-
Salesforce Einstein:通过聚类分析优化了其无代码流程设计器,能根据用户历史操作自动推荐最佳流程路径,某保险公司的案例显示,这一功能使保单处理流程的标准化率从65%提升至92%。
-
国内厂商“简道云”:在2026年春季发布会上推出了“动态聚类看板”,能实时分析用户在不同模块间的操作路径,自动优化界面布局,某制造企业的使用数据显示,员工查找数据的平均时间从3分钟降至22秒。

这些创新背后,是技术架构的深刻变革,传统无代码平台采用“静态建模”方式,用户需要预先定义数据关系;而集成聚类分析的新一代平台采用“动态建模”,系统能根据实际数据自动调整关联规则,这种转变,类似于从“手工绘图”到“智能修图”的升级。
挑战与应对:数据质量、算法透明与人才缺口
尽管前景光明,但无代码工具与聚类分析的融合仍面临挑战,2026年《哈佛商业评论》的调研指出,企业最担忧的三大问题是:
-
数据质量问题:聚类分析的效果高度依赖数据完整性,某物流企业的案例显示,当地址字段缺失率超过15%时,模型对配送路线的优化建议准确率下降40%。
-
算法黑箱问题:业务人员难以理解聚类模型的决策逻辑,某银行尝试用聚类分析进行信贷审批时,因无法解释“为什么某些群组被拒绝贷款”,导致监管合规风险。
-
复合人才缺口:既懂业务又懂聚类分析的“翻译者”稀缺,某制造企业的招聘数据显示,这类岗位的供需比达到1:17,平均招聘周期超过6个月。
2026年绿色水处理与网络安全及绿色创新链热度不断攀升,技术创新带来新突破 针对这些问题,先行企业已经探索出解决方案:
-
数据治理:建立跨部门的数据标准委员会,强制要求关键字段的完整率超过95%,某汽车集团通过此举,使聚类模型的预测准确率提升了25个百分点。
-
可解释AI:采用SHAP值等技术,为聚类结果生成业务解释,某电商平台将模型输出的“高风险用户群组”转化为“过去30天退货率超过30%且客服投诉超过2次的用户”,