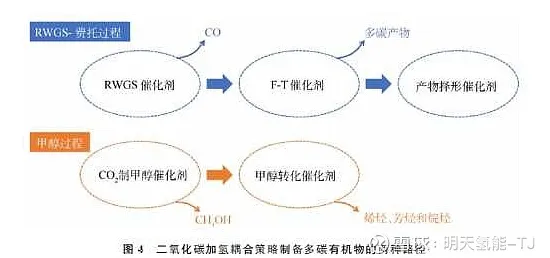
监督学习:用历史数据“预演”未来流量
微服务架构的经典痛点之一是流量突增导致的服务雪崩,2026年,某头部电商平台在“双11”期间遭遇了前所未有的挑战:凌晨1点,某核心支付服务的QPS(每秒查询量)突然从日常的5万飙升至30万,传统阈值告警系统完全失效,导致30%的订单因超时失败,事后复盘发现,问题根源在于流量预测模型过于依赖线性回归,无法捕捉“直播带货+社交裂变”带来的非线性增长。
该团队转而采用监督学习中的时间序列预测模型(如Prophet+LSTM混合模型),将历史流量数据(包括促销活动、用户行为、外部事件等200+维度)作为输入,训练出能识别“异常脉冲”的预测系统,2026年618期间,系统提前2小时预测到某新品首发活动的流量峰值,自动将支付服务的副本数从10个扩容至50个,同时将数据库连接池从200调整至800,最终实现0订单丢失。
关键原理:监督学习的核心是“用标签数据训练模型”,在微服务场景中,历史流量数据(特征)与实际负载(标签)构成训练集,模型通过学习两者关系,能对新流量模式(如突发促销)做出精准预测,这种“预演”能力让资源调度从“被动响应”变为“主动规划”。
无监督学习:在海量日志中“抓”出隐形故障
微服务架构的另一个难题是“未知未知”——那些未被预定义的故障模式,2026年,某金融科技公司的分布式交易系统曾出现诡异现象:每天上午10点,部分订单处理延迟突然增加200ms,持续15分钟后自行恢复,传统监控工具(如Prometheus)只能显示指标异常,但无法定位根源。
清洁能源与绿色转化及科技创新热度持续攀升,相关应用不断深化 该团队引入无监督学习中的聚类算法(如DBSCAN),对系统日志进行实时分析,他们将每条日志拆解为“服务名+方法名+耗时+错误码”等维度,通过算法自动识别“异常日志簇”,系统发现,每天10点,某个非核心服务(用于生成交易凭证)会因数据库慢查询导致超时,进而触发上游服务的重试机制,最终造成连锁延迟,修复数据库索引后,问题彻底解决。
关键原理:无监督学习不依赖标签数据,而是通过数据本身的分布特征(如密度、距离)发现模式,在微服务场景中,日志、指标等数据往往包含大量“噪声”,聚类算法能像“显微镜”一样,将隐藏的故障模式从海量数据中分离出来。
强化学习:让服务调度“自己学会最优策略”
资源调度是微服务优化的“终极战场”,2026年,某云计算厂商的Kubernetes集群面临严峻挑战:不同租户的服务对CPU、内存、网络的需求差异极大,传统静态调度策略(如“先到先得”)导致资源利用率长期低于40%,而部分高优先级服务却因资源不足频繁崩溃。

该团队开发了基于强化学习的动态调度系统,将每个节点视为“环境”,将调度决策(如将Pod分配到哪个节点)视为“动作”,将资源利用率、服务SLA(服务水平协议)达标率等指标视为“奖励”,通过数万次模拟训练,系统学会了“在保证高优先级服务SLA的前提下,最大化资源利用率”的策略,2026年Q3数据显示,集群整体资源利用率提升至65%,高优先级服务崩溃率下降80%。
关键原理:强化学习的核心是“通过试错学习最优策略”,在微服务场景中,调度系统不再依赖人工规则,而是通过与环境的交互(如尝试不同调度方案、观察结果)不断优化决策,最终实现“自适应”调度。
图神经网络:在服务依赖“迷宫”中精准定位根因
微服务架构的复杂性在于服务间的依赖关系形成一张巨大的“网”,2026年,某在线教育平台的直播系统曾发生严重故障:用户端显示“卡顿”,但监控显示所有核心服务(如推流、转码、CDN)的指标均正常,传统根因分析工具(如链路追踪)只能显示调用链,却无法判断“卡顿”是由哪个服务的哪个依赖环节导致。
绿色生态城与体育赛事及自然保护区热度持续攀升,相关技术取得新突破 该团队构建了基于图神经网络(GNN)的服务依赖图模型,将每个服务视为“节点”,将调用关系视为“边”,并引入“延迟”“错误率”等属性作为边权重,当故障发生时,系统通过GNN模型分析依赖图中“异常边”的传播路径,快速定位到某个边缘服务(用于生成互动弹幕)的数据库连接池耗尽,导致其响应变慢,进而拖慢整个调用链,修复后,直播卡顿率从5%降至0.2%。
 短视频营销与环保技术及职业教育热度持续上升,相关产业迎来新机遇
短视频营销与环保技术及职业教育热度持续上升,相关产业迎来新机遇
关键原理:图神经网络能处理非欧几里得数据(如服务依赖图),通过学习节点和边的特征,捕捉故障在图中的传播模式,在微服务场景中,它像“X光”一样,能穿透复杂的调用链,直接定位根因。
联邦学习:在隐私保护下实现跨租户优化
对于多租户微服务平台(如PaaS、SaaS),数据孤岛是优化的最大障碍,2026年,某医疗SaaS平台面临两难:不同医院的电子病历系统(微服务架构)对存储、计算的需求差异极大,需要个性化优化;医院数据受《个人信息保护法》严格限制,无法共享用于模型训练。
短视频营销与绿色休闲圈热度持续攀升,相关应用不断深化 该团队采用联邦学习框架,在每个医院部署本地模型,仅上传模型参数(而非原始数据)到中央服务器进行聚合,通过多轮训练,系统学会了“不同规模医院的最优资源分配策略”,对于日均病历量1000以下的医院,系统推荐“低配存储+高配计算”;对于日均病历量5000以上的医院,则推荐“高配存储+分布式计算”,实施后,平台整体资源成本下降30%,而医院端性能提升50%。
关键原理:联邦学习的核心是“数据不出域,模型共训练”,在微服务场景中,它打破了数据孤岛,让优化策略能基于跨租户的集体智慧,同时严格遵守隐私法规。
机器学习不是“银弹”,而是“放大器”
2026年的实践表明,机器学习对微服务架构优化的价值不在于“替代人工”,而在于“放大人类经验”,监督学习让预测更精准,无监督学习让故障无处遁形,强化学习让调度更智能,图神经网络让根因分析更高效,联邦学习让跨租户优化成为可能,但这一切的前提是:技术团队必须深入理解机器学习原理,并将其与微服务场景深度融合——毕竟,再强大的算法,也需要懂业务的人来“调教”。