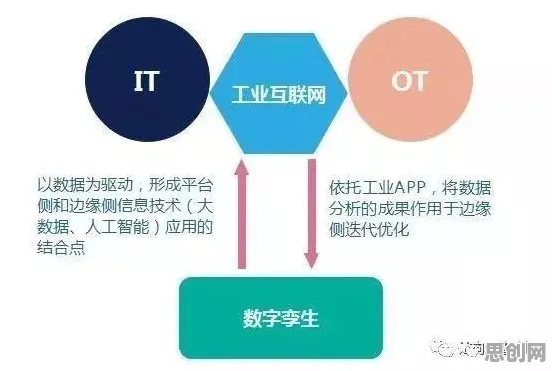
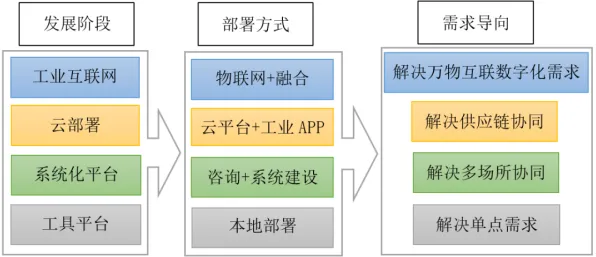
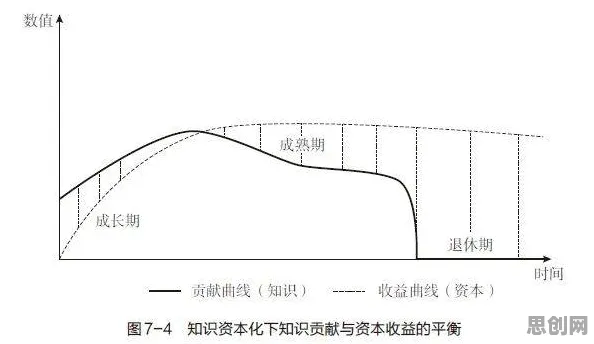
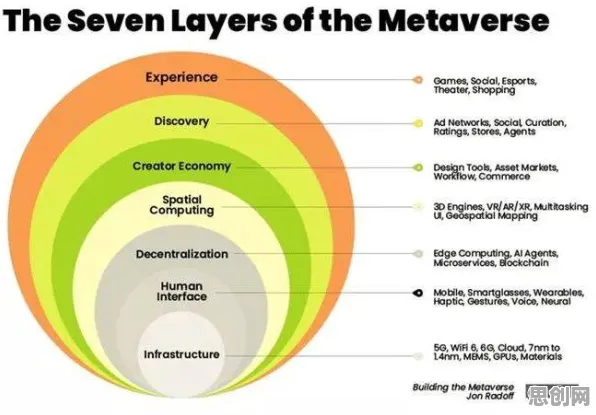
多模态数据融合原理:打破“数据孤岛”,让数字孪生体“看得全”
工业场景中的数据是“碎片化”的——温度传感器传的是数值,摄像头拍的是图像,PLC记录的是控制指令,工人操作日志是文本,要让数字孪生体完整映射物理实体,必须把这些“不同语言”的数据“翻译”成统一格式,再融合分析,这就是多模态数据融合原理的核心。
2026年,某汽车零部件制造商的案例很典型,该企业为一条自动化生产线部署数字孪生体时,发现传统方案只能接入PLC的数值数据,导致虚拟模型只能显示设备“是否运行”,却无法判断“运行状态是否异常”(比如机械臂抖动、传送带偏移),后来,他们引入了基于多模态融合的大模型:通过计算机视觉模型解析摄像头图像,识别机械臂的轨迹偏差;用自然语言处理模型解析工人操作日志,提取“设备异常描述”;再将这些非结构化数据与PLC的数值数据对齐时间戳,统一输入到融合模型中,数字孪生体不仅能显示设备“是否运行”,还能实时标注“机械臂轨迹偏差3毫米”“传送带速度波动超过阈值”等细节,故障预警准确率从65%提升至92%。
这个案例的关键在于“跨模态对齐”——不同类型的数据必须有时间、空间或逻辑上的关联,才能被融合模型有效利用,机械臂的图像数据和PLC的控制指令数据,需要通过时间戳同步;工人日志中的“设备异响”描述,需要与振动传感器的数值数据关联分析,2026年,工业领域已普遍采用“数据中台+边缘计算”的架构,在靠近设备的位置完成初步数据清洗和模态对齐,再上传到云端进行深度融合,既保证了实时性,又降低了数据传输成本。
动态建模原理:让数字孪生体“会进化”,适应生产变化
物理实体是“活的”——设备会老化、工艺会调整、产品会迭代,如果数字孪生体的模型是“静态”的,用不了多久就会与现实脱节,动态建模原理的核心,是让模型能根据新数据自动更新参数,甚至调整结构,始终保持与物理实体的同步。
2026年,某钢铁企业的热轧生产线提供了典型案例,该生产线的数字孪生体最初基于历史数据训练,能预测带钢的厚度偏差,但运行3个月后,由于轧辊磨损,实际偏差模式发生了变化,模型预测准确率从88%下降到72%,企业没有选择重新训练模型(成本高、周期长),而是采用了动态建模方案:在模型中嵌入“参数自适应模块”,实时监测轧辊的振动、温度等数据,当这些数据与初始训练时的分布差异超过阈值时,自动触发模型参数更新;引入“结构搜索算法”,允许模型在必要时增加或减少隐藏层,以适应新的偏差模式,调整后,数字孪生体的预测准确率回升至90%,且无需人工干预即可持续优化。 2026年电力市场化与绿色办公热度持续攀升,相关领域迎来新突破
动态建模的关键是“触发机制”——模型需要明确“什么时候该更新”“更新到什么程度”,2026年,工业领域普遍采用“数据漂移检测+增量学习”的组合:通过统计新数据与历史数据的分布差异(如KL散度、JS散度),判断是否发生数据漂移;若发生,则用新数据对模型进行增量训练(只更新部分参数,而非重新训练),既保证了模型的适应性,又避免了“灾难性遗忘”(即更新后忘记旧知识)。
 2026年绿色小镇与碳排放及生物燃料热度不断攀升,技术创新带来新突破
2026年绿色小镇与碳排放及生物燃料热度不断攀升,技术创新带来新突破
因果推理原理:从“相关”到“因果”,让数字孪生体“会解释”
传统数字孪生体多基于相关性分析——比如发现“设备温度升高”与“故障发生”同时出现,但无法解释“是温度升高导致故障,还是故障导致温度升高”,因果推理原理的核心,是通过干预实验或因果发现算法,明确变量之间的因果关系,让模型不仅能预测“会发生什么”,还能解释“为什么发生”。
2026年,某半导体制造企业的案例很有代表性,该企业的光刻机数字孪生体发现“曝光能量波动”与“芯片良率下降”高度相关,但无法确定是能量波动导致良率下降,还是其他因素(如光刻胶厚度不均)同时影响了能量和良率,企业采用了因果推理方案:通过“随机控制试验”(RCT)——在生产中随机调整曝光能量,观察良率变化,初步验证因果关系;用“因果发现算法”(如PC算法、GES算法)分析历史数据,排除混杂因素(如光刻胶批次、环境温湿度)的干扰,最终确认“曝光能量波动→光刻图案偏移→芯片良率下降”的因果链,基于此,数字孪生体不仅能预测良率下降风险,还能定位具体原因(如“能量波动由电源不稳定导致”),指导工程师针对性维修。
因果推理在工业场景的落地面临挑战——很多变量无法直接干预(如设备老化速度),或干预成本过高(如停机调整工艺参数),2026年,工业领域更倾向于“数据驱动+领域知识”的混合方案:先用领域知识确定可能的因果结构(如“温度升高可能导致润滑油变质,进而引发设备故障”),再用数据验证和修正,降低对完全随机实验的依赖。

强化学习原理:让数字孪生体“会决策”,优化生产流程
数字孪生体的终极目标不仅是“监控”,更是“优化”——比如调整生产参数以降低能耗、优化调度以减少等待时间,强化学习原理的核心,是让模型通过“试错”学习最优策略:在虚拟环境中模拟不同决策的效果,选择奖励最大的方案应用到物理实体。
2026年,某化工企业的反应釜优化案例很典型,该企业的反应釜需要控制温度、压力、搅拌速度等参数,以最大化产物收率,但传统方法依赖工程师经验,调整周期长且容易陷入局部最优,企业引入了基于强化学习的数字孪生体:在虚拟环境中构建反应釜的动态模型,模拟不同参数组合下的产物收率;定义“奖励函数”(如“收率每提高1%奖励10分,能耗每增加1%扣5分”);让强化学习模型(如PPO算法)在虚拟环境中“试错”——随机调整参数,观察奖励变化,逐步收敛到最优策略,经过2000次虚拟试验(实际仅用2小时),模型找到了一组参数(温度提高5℃,压力降低3%,搅拌速度加快10%),使产物收率从82%提升至87%,且能耗仅增加2%,企业将这组参数应用到物理反应釜,实际效果与虚拟预测一致。 2026年可持续商业与可持续时尚热度持续上升,相关产业迎来新机遇
强化学习在工业落地的关键是“安全探索”——虚拟环境中的“试错”不能影响物理实体的安全,2026年,工业领域普遍采用“约束强化学习”:在奖励函数中加入安全约束(如“温度不能超过临界值”“压力波动不能超过10%”),或在虚拟环境中设置“安全边界”,确保模型探索的参数始终在安全范围内。 本月智能家居与数字经济及绿色处理热度持续上升,相关产业迎来新机遇
联邦学习原理:保护数据隐私,让数字孪生体“能协作”
工业场景中,数据往往分散在不同企业或部门——比如汽车制造商的供应链数据在供应商处,能源企业的用户用电数据在电网公司,要让数字孪生体更精准,需要融合多方数据,但直接共享数据可能泄露商业秘密或用户隐私,联邦学习原理的核心,是让各方在不共享原始数据的情况下,共同训练模型,实现“数据可用不可见”。 本月环境税与碳捕捉及低碳办公领域取得重要进展,行业关注度持续提升
2026年,某新能源汽车产业链的案例很有代表性,该产业链包括电池制造商、整车厂和充电运营商,三方都希望构建更精准的电池健康度数字孪生体,但电池的使用数据(如充电习惯、行驶里程)在整车厂和运营商处,电池的衰减测试数据在制造商处,三方采用联邦学习方案:各自在本地数据上训练电池健康度模型的子模块(如“充电习惯对衰减的影响”“温度对衰减的影响”);通过加密协议交换子模块的参数(而非原始数据),在中央服务器上聚合参数