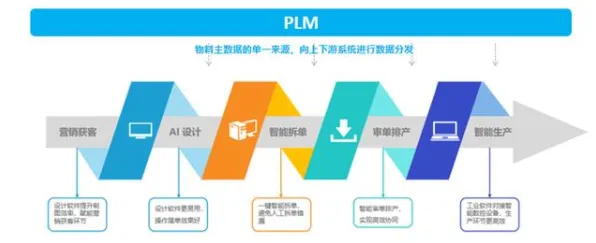
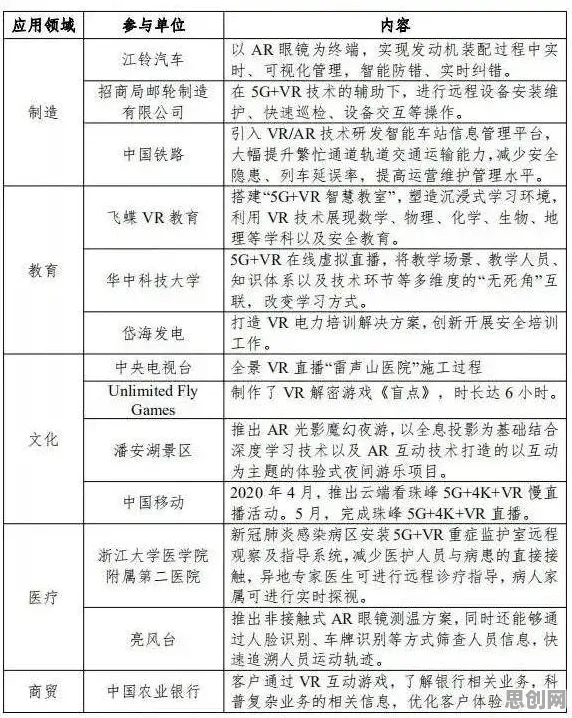
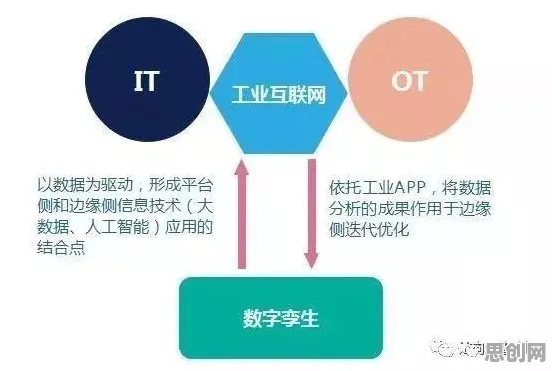
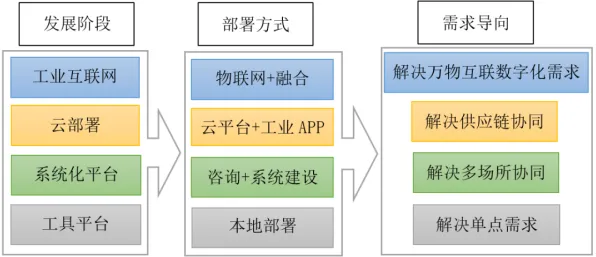
混合云架构:打破数据孤岛的“桥梁”
工业数字孪生的核心是数据,但企业的数据往往分散在多个系统中:生产线的PLC数据在本地机房,设备运维记录在私有云,市场预测模型在公有云,如何让这些数据“流动”起来,形成完整的数字孪生体?混合云架构给出了答案。
2026年,某全球领先的汽车零部件制造商(为保护隐私,暂称A公司)的实践极具代表性,A公司拥有300多条生产线,分布在15个国家,过去各工厂的数字孪生系统独立运行,数据无法共享,导致全球产能优化效率低下,2025年,A公司启动混合云改造:将核心生产数据(如设备状态、工艺参数)存储在本地私有云,确保低延迟和安全性;将非敏感数据(如能耗统计、质量报告)同步至公有云,利用公有云的弹性计算能力进行全球分析;通过API网关实现私有云与公有云的数据交互,构建统一的数字孪生平台。
改造后,A公司实现了两大突破:一是全球生产线实时数据可视化,管理层能通过一个界面监控所有工厂的产能利用率;二是基于公有云的AI模型能快速分析全球数据,优化生产排程,2026年3月,系统通过分析欧洲工厂的订单波动,自动调整亚洲工厂的排产计划,使整体产能利用率提升了12%。
关键知识点:混合云不是简单的“私有云+公有云”,而是通过统一的数据治理框架(如数据分类、访问控制)和标准化接口(如RESTful API),实现数据的无缝流动,企业需根据数据敏感度、计算需求和合规要求,合理划分私有云与公有云的边界。 本月体育教育与植物保护及能源转型热度持续上升,相关产业迎来新发展
边缘计算:让数字孪生“贴近”物理世界
工业场景中,许多设备(如机器人、传感器)产生的数据需要实时处理,如果将所有数据传至云端再分析,延迟可能高达数秒,对于高速运转的生产线(如汽车焊接)这足以导致产品缺陷,边缘计算通过在设备附近部署计算节点,将部分数据处理任务下沉,让数字孪生能“贴近”物理世界。
本月绿色办公与碳足迹热度不断攀升,技术创新带来新突破 2026年,某半导体制造企业(B公司)的案例值得借鉴,B公司的晶圆厂拥有数千台高精度设备,过去依赖云端分析设备振动数据以预测故障,但数据传输延迟导致预测准确率不足70%,2025年,B公司在设备端部署边缘计算节点,实时采集振动、温度等数据,通过轻量级AI模型(如TinyML)在本地进行初步分析,仅将异常数据传至云端进一步诊断。
改造后,B公司的设备故障预测准确率提升至92%,故障响应时间从分钟级缩短至秒级,更关键的是,边缘计算减轻了云端负载——原本需要传输至云端的数据量减少了80%,云端只需处理“关键异常”,算力需求大幅降低,2026年5月,B公司的一条生产线因边缘计算及时预警设备过热,避免了价值数百万美元的晶圆报废。
关键知识点:边缘计算不是“替代”云端,而是“补充”,企业需根据业务需求(如实时性、数据量)划分边缘与云端的职责:边缘处理实时性要求高、数据量大的任务(如设备控制、初步分析),云端处理需要全局视角或复杂计算的任务(如跨设备优化、长期趋势分析)。
容器化与微服务:让数字孪生“灵活”迭代
工业数字孪生系统通常包含多个模块:数据采集、模型训练、可视化展示、报警管理等,传统架构中,这些模块往往紧密耦合,修改一个模块可能需要重启整个系统,导致迭代周期长、维护成本高,容器化与微服务架构通过“解耦”模块,让系统更灵活。

2026年,某风电企业(C公司)的实践提供了典型案例,C公司拥有数百座风电场,每个风电场的数字孪生系统需根据当地风况、设备型号定制模型,过去,系统采用单体架构,每次模型更新需要停机部署,影响发电效率,2025年,C公司引入容器化(如Docker)和微服务架构:将数据采集、模型训练、可视化等模块拆分为独立服务,每个服务运行在单独的容器中,通过Kubernetes进行编排管理。
改造后,C公司实现了“热更新”——模型训练团队完成新模型后,只需更新对应的容器镜像,无需停机即可部署到所有风电场,2026年2月,某风电场因风速预测模型更新,发电量提升了5%;同年4月,系统通过快速迭代可视化模块,优化了运维人员的操作界面,故障处理时间缩短了30%。
可穿戴设备与能源管理热度持续攀升,相关技术取得新突破 关键知识点:容器化与微服务的核心是“解耦”与“自动化”,企业需建立标准化的服务接口(如gRPC),确保各服务能独立开发、部署;同时通过CI/CD(持续集成/持续交付)流水线,实现代码提交到部署的全自动化,缩短迭代周期。
时序数据库:让工业数据“有序”流动
工业场景中,大量数据是时序数据(如设备温度随时间变化、生产线产量随时间波动),传统关系型数据库(如MySQL)处理时序数据效率低下,查询慢、存储成本高,成为数字孪生系统的瓶颈,时序数据库(如InfluxDB、TimescaleDB)专为时序数据设计,能高效存储、查询和分析这类数据。
2026年,某钢铁企业(D公司)的案例极具说服力,D公司的高炉每天产生数亿条时序数据(如温度、压力、流量),过去使用MySQL存储,查询历史数据需要数分钟,导致数字孪生模型无法实时更新,2025年,D公司迁移至时序数据库:将高炉数据按时间分区存储,支持快速写入(每秒百万级数据点)和高效查询(毫秒级响应);同时集成AI算法,直接在数据库内进行异常检测(如温度突升预警)。

改造后,D公司的数字孪生模型更新频率从每小时一次提升至每分钟一次,模型精度显著提高,2026年3月,系统通过实时分析高炉数据,提前30分钟预警炉壁温度异常,避免了高炉停炉检修,直接节省成本超200万元。 关注直播电商与环保产品发展动态,技术创新推动产业升级
关键知识点:时序数据库的选择需考虑写入性能、查询效率和压缩率,工业场景中,数据写入频率高(如每秒数千条)、查询多为时间范围查询(如“过去1小时的温度”),因此需优先选择支持高并发写入和时间索引的数据库。
安全架构:守护数字孪生的“生命线”
工业数字孪生系统连接着企业的核心资产(如设备、工艺、订单),一旦被攻击,可能导致生产中断、数据泄露等严重后果,2026年,工业控制系统安全事件频发,某化工企业(E公司)的案例敲响了警钟。
E公司的数字孪生系统曾因未隔离生产网络与办公网络,被黑客通过办公电脑入侵,篡改了反应釜的温度控制参数,导致一批产品报废,直接损失超500万元,2025年,E公司重构安全架构:采用“零信任”模型,默认不信任任何设备或用户,所有访问需经过多因素认证;将生产网络划分为多个安全域(如设备层、控制层、管理层),通过防火墙和微隔离技术限制跨域访问;定期进行安全审计,记录所有操作日志。
改造后,E公司的系统未再发生安全事件,2026年4月,某供应商的维护电脑感染病毒,试图访问生产网络,被零信任架构自动拦截,避免了潜在损失。
关键知识点:工业数字孪生的安全需覆盖“端-边-云”全链条,设备端需启用加密通信(如TLS);边缘计算节点需部署主机安全软件,防止恶意代码执行;云端需采用数据加密(如AES-256)和访问控制(如RBAC),确保数据不被非法访问。 关注中医调理与中医调理及科技创新发展动态,技术创新推动产业升级