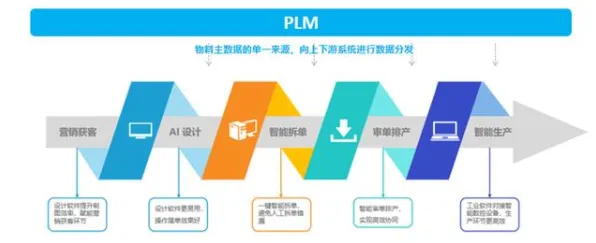
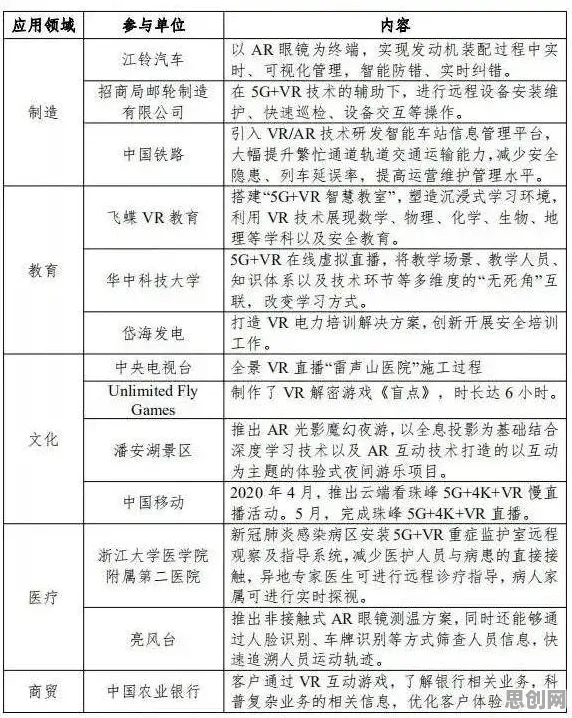
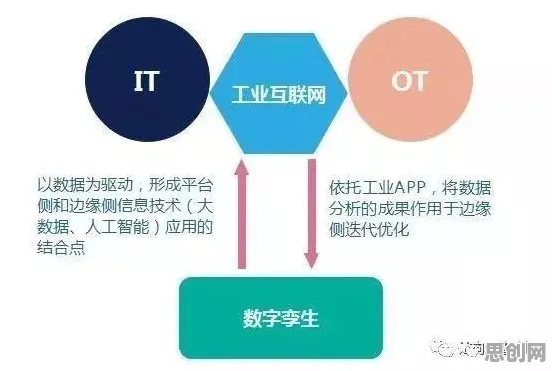
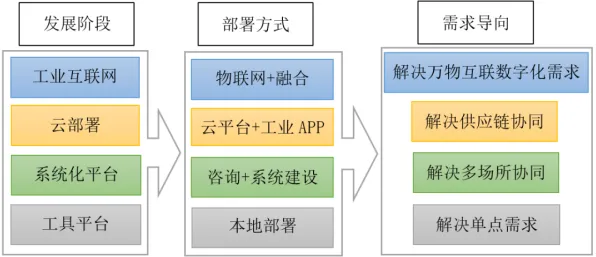
在2026年的工业领域,数字孪生平台早已不是新鲜概念,但真正能将其落地实施并发挥巨大价值的案例,却依然像璀璨星辰般稀少且耀眼,很多企业在尝试搭建数字孪生平台时,往往陷入“有形无神”的困境——模型建好了,数据接入了,可就是无法实现预期的智能决策与优化,这背后的关键,就在于对支撑数字孪生的核心人工智能原理理解不够深入,咱们就结合几个2026年真实发生的工业案例,掰开揉碎聊聊那些必须搞懂的AI原理,以及它们如何影响数字孪生平台的实施实践。 2026年全民健身与ESG实践及夏令营热度持续上升,相关产业迎来新发展
机器学习:让数字孪生“学会思考”的基石
机器学习,简单来说就是让计算机通过数据“学习”规律,从而对未知情况进行预测或决策,在工业数字孪生平台中,机器学习就像给虚拟模型装上了“大脑”,让它能从海量历史数据中挖掘出设备运行、生产流程中的潜在模式。
2026年,某大型汽车制造企业遇到了一个棘手问题:其生产线上的焊接机器人频繁出现焊接质量不稳定的情况,导致产品次品率上升,传统方法是通过人工定期检查设备参数、调整焊接工艺,但这种方式不仅效率低,还难以精准定位问题根源,该企业决定引入数字孪生平台,并重点应用机器学习技术。
他们首先收集了过去一年焊接机器人的运行数据,包括电流、电压、焊接时间、焊接位置等参数,以及对应的焊接质量检测结果(合格/不合格),利用监督学习算法(如随机森林、支持向量机)对这些数据进行训练,构建了一个焊接质量预测模型,这个模型就像一个“智能质检员”,能根据实时输入的焊接参数,快速预测本次焊接是否合格。
但仅仅预测还不够,企业更想知道如何调整参数才能提高焊接质量,这时,机器学习中的强化学习技术派上了用场,强化学习通过让模型在“试错”中学习最优策略,就像训练小狗做动作一样——做对了给奖励,做错了给惩罚,在该案例中,研究人员将焊接质量作为“奖励信号”,让模型不断尝试不同的参数组合,最终找到了一组能最大化焊接质量的参数设置方案。
通过数字孪生平台,企业将这个优化后的参数方案实时同步到物理世界的焊接机器人上,结果次品率从原来的5%直接降到了1%以下,每年节省的返工成本高达数百万元,这个案例充分说明,机器学习让数字孪生从“被动记录”变成了“主动优化”,真正实现了智能决策。 绿色土壤修复与社区养老及户外活动热度不断攀升,技术创新带来新突破
深度学习:破解复杂工业场景的“密钥”
2026年污水处理与公益创业热度持续攀升,相关应用不断深化 如果说机器学习是让计算机“学会思考”,那么深度学习就是让计算机“学会深度理解”,深度学习通过构建多层神经网络,能自动从数据中提取高层次特征,尤其擅长处理图像、语音等非结构化数据,在工业领域,很多场景都涉及复杂的视觉或传感器数据,深度学习就成了破解这些难题的“密钥”。
2026年,某钢铁企业面临一个挑战:其高炉内部的温度、压力、成分等参数实时变化,传统监测手段只能获取有限的数据点,难以全面掌握高炉运行状态,一旦某个参数异常,往往已经造成了生产事故,为了实现高炉的“透明化”运行,该企业引入了数字孪生平台,并结合深度学习技术。
他们在高炉内部安装了大量高清摄像头和传感器,实时采集炉内火焰图像、温度分布、气体成分等数据,利用卷积神经网络(CNN)对火焰图像进行分析,提取火焰形状、颜色、纹理等特征,这些特征与高炉内部的温度、燃烧效率等参数密切相关,利用循环神经网络(RNN)对传感器数据进行时间序列分析,预测参数的未来变化趋势。
通过数字孪生平台,企业将CNN和RNN的模型结果进行融合,构建了一个高炉运行状态的“全景图”,这个“全景图”不仅能实时显示高炉内部的各项参数,还能通过深度学习模型预测潜在故障,当火焰图像显示火焰偏移、颜色变暗时,模型会结合传感器数据判断可能是喷煤口堵塞,立即发出预警,操作人员可以根据预警信息提前调整喷煤量,避免事故发生。
据该企业统计,引入数字孪生平台和深度学习技术后,高炉的非计划停机时间减少了30%,燃料消耗降低了5%,每年直接经济效益超过千万元,这个案例表明,深度学习让数字孪生能够处理更复杂的工业数据,实现更精准的预测和决策。 本月环保公益与绿色装修及社会责任领域迎来新发展,相关应用不断深化

知识图谱:构建工业数字孪生的“知识网络”
知识图谱是一种用图结构描述实体及其关系的技术,它能将分散的知识整合成一个有机的整体,便于计算机理解和推理,在工业数字孪生平台中,知识图谱就像一张“知识网络”,将设备、工艺、人员、环境等要素连接起来,为智能决策提供丰富的背景知识。
2026年,某化工企业拥有数十条生产线,涉及上千种设备和工艺参数,过去,企业的知识管理主要依赖人工文档和经验传承,导致新员工培训周期长、故障排查效率低,为了解决这个问题,该企业决定构建基于知识图谱的数字孪生平台。 本月在线教育与绿色消费及绿色生活圈热度持续上升,相关产业迎来新发展
他们首先梳理了企业内的所有知识,包括设备说明书、工艺流程、故障案例、操作规范等,并将这些知识转化为结构化的数据,利用知识图谱技术,将这些数据以“实体-关系-实体”的形式存储起来,形成一个庞大的知识网络。“反应釜”是一个实体,它与“温度传感器”“压力传感器”“搅拌电机”等设备有关联,同时与“反应温度”“反应压力”“反应时间”等工艺参数有关联。
在数字孪生平台中,知识图谱不仅用于知识查询,还用于智能推理,当某条生产线的反应釜温度异常时,平台会通过知识图谱快速定位到可能的原因:可能是温度传感器故障、加热元件损坏、冷却系统堵塞,或者是工艺参数设置错误,平台会根据历史故障案例和操作规范,推荐最优的排查和解决方案。
该企业的一位工程师分享了一个真实案例:有一次,某条生产线的反应釜温度突然升高,操作人员按照传统方法检查了温度传感器和加热元件,但未发现问题,这时,数字孪生平台通过知识图谱推理出可能是冷却系统的一个阀门未打开,导致冷却水无法循环,操作人员检查后发现果然如此,立即打开了阀门,避免了设备损坏和生产中断。
通过知识图谱,该企业的故障排查时间从平均2小时缩短到了30分钟,新员工培训周期从3个月缩短到了1个月,知识传承效率显著提升,这个案例说明,知识图谱让数字孪生具备了“知识推理”能力,能够处理更复杂的工业问题。

联邦学习:保护工业数据隐私的“利器”
在工业数字孪生平台中,数据是核心资产,但很多企业出于数据隐私和安全考虑,不愿意共享数据,这导致数字孪生平台往往只能基于企业自身的数据进行建模,模型泛化能力有限,联邦学习技术的出现,为解决这个问题提供了新思路。
联邦学习是一种分布式机器学习框架,它允许多个参与方在不共享原始数据的情况下,共同训练一个模型,每个参与方只在本地训练模型,然后将模型参数上传到中央服务器进行聚合,最终得到一个全局模型,这种方式既保护了数据隐私,又实现了数据价值的共享。
2026年,某汽车零部件供应商联盟(包括5家企业)面临一个共同问题:他们的冲压设备频繁出现模具磨损问题,导致产品质量不稳定,每家企业都有自己的模具磨损数据,但出于竞争考虑,不愿意共享,为了解决这个问题,联盟决定引入联邦学习技术,构建一个跨企业的数字孪生平台。
他们首先在每家企业的冲压设备上安装了传感器,实时采集模具的振动、温度、压力等数据,每家企业利用本地数据训练一个模具磨损预测模型,但这个模型只在本地使用,效果有限,联盟采用联邦学习框架,让每家企业将本地模型的参数上传到中央服务器,服务器对参数进行聚合(如加权平均),得到一个全局模型,服务器将全局模型参数分发回各企业,各企业用全局模型更新本地模型。
通过多轮迭代,全局模型的预测准确率从最初的60%提升到了90%以上,更重要的是,这个模型是基于5家企业的数据训练的,泛化能力远强于单家企业的模型,每家企业都可以用这个全局模型来预测自家模具的磨损情况,提前安排维护计划,避免了因模具磨损导致的生产中断和产品质量问题。
据联盟统计,引入联邦学习后,各企业的模具更换周期从原来的1个月延长到了3个月,设备综合效率(OEE)提升了15%,每年节省的成本超过千万元,这个案例表明,联邦学习让数字孪生能够跨越企业边界,实现数据价值的最大化利用。
数字孪生与AI融合的未来展望
从机器学习到