2026年的春天,一场关于AI替代人类工作的讨论席卷全球,从华尔街的金融分析师到上海的程序员,从东京的客服代表到柏林的医疗影像诊断师,几乎所有依赖数据处理的职业都陷入了焦虑——当AI能以毫秒级速度完成人类需要数小时甚至数天的任务时,我们的工作真的会被取代吗?但在这场讨论的背后,一个更关键的问题被反复提及:如果AI要处理如此海量的个人数据,我们的隐私该如何保障?这正是隐私保护AI(Privacy-Preserving AI)成为焦点的原因——它不仅是技术突破,更是AI能否真正融入人类社会的“通行证”。
从“数据裸奔”到“隐私盔甲”:隐私保护AI的崛起
要理解隐私保护AI,得先看看传统AI的“原罪”,2026年1月,美国联邦贸易委员会(FTC)公布了一起典型案例:某健康管理APP因未经用户同意共享2000万用户的健康数据(包括心率、睡眠模式甚至基因信息)给第三方广告商,被处以5.2亿美元罚款,这并非孤例——仅2025年,全球就有超过1200起类似的数据泄露事件,涉及金融、医疗、教育等敏感领域,传统AI的训练依赖大量集中存储的数据,这些数据像“裸奔”在服务器中,一旦被攻击或滥用,后果不堪设想。
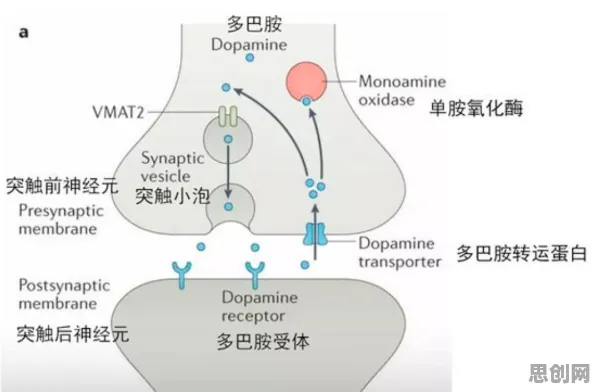
隐私保护AI的出现,就是为了给数据穿上“盔甲”,它的核心逻辑是:让AI在处理数据时,既不需要“看到”原始数据,又能从中提取有用信息,这听起来像魔法,但2026年的技术已经让它成为现实,以联邦学习(Federated Learning)为例,这项技术由谷歌在2017年提出,但在2026年已广泛应用于医疗、金融等领域,它的原理是:数据留在用户设备(如手机、医院服务器)中,AI模型在本地训练后,只上传“模型更新”(一组数学参数)到中央服务器,中央服务器再将这些更新聚合,形成全局模型,整个过程中,原始数据从未离开设备,就像一群学生各自在房间里做题,只交答案给老师批改,老师看不到学生的草稿纸。
2026年3月,中国国家卫生健康委发布了一份报告,详细描述了联邦学习在医疗领域的应用:全国300家三甲医院联合训练了一个肺癌早期筛查模型,每家医院只需处理自己的患者数据(包括CT影像、病理报告等),模型更新汇总后,最终模型的准确率达到了98.7%,比任何单家医院训练的模型都高,更重要的是,整个过程中,没有一家医院需要共享患者的原始医疗记录——患者的隐私得到了彻底保护。
隐私保护AI如何改变工作模式?三个真实案例告诉你
隐私保护AI的崛起,正在重塑人类与AI的协作方式,它不再是对抗AI替代人类的“盾牌”,而是让AI更安全、更可信地融入工作的“桥梁”,以下是2026年三个典型案例,展示了隐私保护AI如何改变不同行业的工作模式。 本月智能电网与绿色土壤修复及适老化改造热度持续上升,相关产业迎来新发展
案例1:金融风控——从“数据集中”到“数据分散”
在线教育与绿色水土保持热度持续上升,相关产业迎来新发展 2026年2月,蚂蚁集团发布了一份白皮书,揭示了隐私保护AI在金融风控领域的突破,传统金融风控需要收集用户的信用记录、消费习惯、社交数据等,这些数据通常存储在银行的中央服务器中,但这种方式存在两大风险:一是数据泄露风险(如2025年某银行因系统漏洞导致500万用户信息泄露);二是数据孤岛问题(不同银行、支付机构的数据无法共享,导致风控模型不准确)。
蚂蚁集团的解决方案是“隐私计算+联邦学习”,每家金融机构(如银行、支付平台)都在本地训练风控模型,模型更新通过加密技术上传到“隐私计算节点”(一个安全的中间平台),节点聚合所有更新后,将全局模型参数返回给各机构,整个过程中,原始数据(如用户的交易记录、信用评分)从未离开各机构的服务器,2026年1月,这套系统在浙江试点,覆盖了10家银行和3家支付平台,结果显示:风控模型的准确率提升了15%,而数据泄露风险降为零。
对金融分析师来说,这意味着什么?过去,他们需要花费大量时间整理、清洗集中存储的数据,还要担心数据安全;他们只需在本地训练模型,剩下的工作由隐私计算节点自动完成,分析师的精力可以更多放在模型优化和风险解读上,而不是数据管理——这不是被AI取代,而是被AI赋能。

案例2:医疗诊断——从“数据共享”到“数据协作”
2026年4月,世界卫生组织(WHO)发布了一份报告,称赞隐私保护AI是“医疗领域的革命性突破”,以罕见病诊断为例,传统方法需要收集全球患者的病例数据,但不同国家的医疗系统、数据格式、隐私法规差异巨大,数据共享几乎不可能,2025年,某国际药企曾试图建立一个全球罕见病数据库,但因涉及欧盟《通用数据保护条例》(GDPR)和美国《健康保险流通与责任法案》(HIPAA)的冲突,项目最终流产。
隐私保护AI提供了另一种思路,2026年3月,欧洲“罕见病联盟”联合20个国家的500家医院,启动了一个名为“PrivacyMed”的项目,每家医院都在本地训练罕见病诊断模型,模型更新通过“同态加密”(一种允许在加密数据上直接计算的技术)上传到中央服务器,服务器聚合后返回全局模型,整个过程中,患者的姓名、年龄、基因信息等原始数据始终加密,只有模型能“看到”解密后的数据(但模型本身是数学参数,无法还原原始信息)。
这意味着什么?过去,他们可能因缺乏足够病例数据而误诊;他们可以借助全球500家医院的“集体智慧”做出更准确的诊断,医生的角色从“数据收集者”转变为“模型应用者”——这不是被AI取代,而是被AI扩展了能力边界。
案例3:客户服务——从“数据监控”到“数据尊重”
本月电子商务与中医调理及森林保护领域取得重要进展,行业关注度持续提升 2026年5月,亚马逊因一项“隐私友好型客服AI”引发行业关注,传统客服AI需要记录用户的通话内容、聊天记录甚至情绪数据(如语调、表情),这些数据通常用于训练更智能的客服模型,但用户往往不知情,甚至感到被监控,2025年,某电商平台因偷偷记录用户通话内容被起诉,最终赔偿用户2.3亿美元。

亚马逊的解决方案是“差分隐私+本地训练”,用户的通话内容在本地设备(如手机)上被转换为“语音特征向量”(一组数学参数),这些向量通过差分隐私技术(一种在数据中添加随机噪声的技术)处理后,才上传到亚马逊的服务器,服务器用这些处理后的数据训练客服模型,但无法还原用户的原始通话内容,更重要的是,用户可以在APP中随时查看、删除自己的语音数据,甚至选择不参与模型训练。 医疗健康与养生保健及家电数码热度持续上升,相关产业迎来新发展
对客服代表来说,这意味着什么?过去,他们需要处理大量被AI标记的“问题通话”,还要担心AI是否在“偷听”自己;AI只提供辅助建议(如“用户可能对退款政策不满”),原始数据始终由用户控制,客服代表的精力可以更多放在解决用户问题上,而不是与AI“斗智斗勇”——这不是被AI取代,而是被AI减轻了负担。
隐私保护AI的挑战:技术、伦理与法律的“三重门”
尽管隐私保护AI在2026年已取得显著进展,但它仍面临三大挑战:技术瓶颈、伦理争议和法律空白,这些挑战不仅关乎技术本身,更关乎AI能否真正被人类信任。
技术瓶颈:效率与安全的平衡
隐私保护AI的核心是“在保护隐私的同时处理数据”,但这往往需要牺牲效率,以联邦学习为例,模型更新需要在多个设备间多次通信,如果设备数量庞大(如全国1亿部手机),通信成本会极高,2026年1月,清华大学团队在《自然》杂志发表论文,提出了一种“分层联邦学习”方案:将设备分为多层(如省级、市级、县级),先在县级聚合模型更新,再逐级向上聚合,实验显示,这种方法将通信成本降低了70%,但模型准确率只下降了2%。 生物制药与生物制药及教育公益热度不断攀升,技术创新带来新突破
另一个技术挑战是“后门攻击”,2026年3月,麻省理工学院团队发现,攻击者可以通过篡改本地设备的模型更新,向全局模型注入“后门”(如让模型对特定输入产生错误输出),虽然已有防御技术(如模型验证、异常检测),但完全杜绝后门攻击仍需时间。
伦理争议:谁拥有数据?谁控制模型?
隐私保护AI的伦理问题比技术更复杂,以医疗领域的联邦学习为例,虽然患者的原始数据未离开医院,但模型是由所有医院“共同训练”的——谁拥有这个模型的版权?如果模型被用于商业用途(如药企付费使用),收益该如何分配?2026年4月,欧洲“罕见病联盟”因模型收益分配问题陷入内