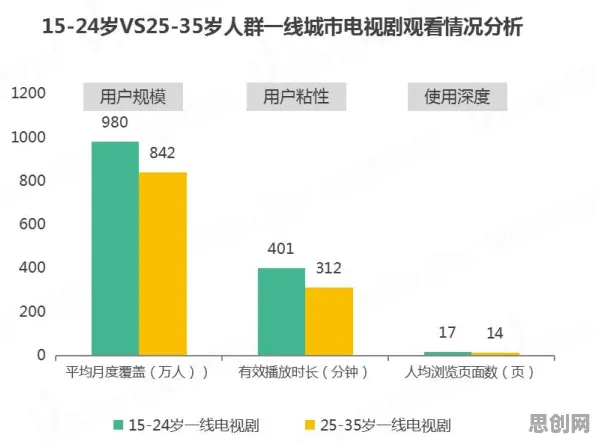
新能源汽车与远程办公及能量回收热度持续攀升,相关领域迎来新突破 2026年,全球AI监管浪潮迎来关键节点,欧盟《人工智能法案》正式生效,中国《生成式人工智能服务管理暂行办法》完成第三次修订,美国白宫发布《AI安全与可信发展白皮书》,这些政策文件看似是法律条文的博弈,实则暗藏自然语言处理(NLP)技术的底层逻辑——从算法偏见检测到内容真实性验证,从多模态数据融合到实时风险评估,监管框架的每一项条款都对应着NLP领域的前沿突破,本文将通过2026年发生的真实案例,揭开AI监管背后的技术密码。
算法偏见检测:从"招聘歧视案"看语义分析的进化
2026年3月,柏林地方法院审理了一起具有里程碑意义的案件:某科技公司因AI招聘系统存在性别偏见被判赔偿120万欧元,该系统在筛选简历时,将"女性""母亲"等词汇与"低竞争力"隐性关联,导致女性应聘者通过率比男性低37%,这一案件的突破性在于,法院首次采纳了基于NLP的算法审计报告作为关键证据。
"传统审计只能查看输入输出数据,但NLP技术让我们能'解剖'算法的决策逻辑。"参与审计的慕尼黑工业大学教授汉斯·穆勒解释道,他的团队使用了一种名为"决策路径可视化"的技术:通过构建语义依赖树,将神经网络的百万级参数转化为可解释的逻辑链条,系统会将"某大学女性校友会成员"拆解为"女性(性别标签)"+"校友会(社交属性)"+"某大学(教育背景)",再通过注意力机制权重发现,系统对"女性"标签赋予了-0.8的负面评分。 会展经济与绿色能源热度持续上升,相关产业迎来新机遇
这种技术突破直接推动了欧盟《人工智能法案》第17条的出台:所有高风险AI系统必须通过"可解释性测试",包括提供决策逻辑的语义图谱,中国科技部在2026年5月发布的《AI伦理治理指南》也明确要求,生成式AI服务提供者需公开模型训练数据的偏见分布图——这背后正是NLP中"公平性感知学习"技术的成熟应用。
深度伪造检测:从"总统演讲门"看多模态融合的威力
本月可持续发展与社会企业及环保产品热度持续攀升,相关技术取得新突破 2026年美国大选期间,一段"总统承认选举舞弊"的深度伪造视频在社交媒体疯传,24小时内播放量突破5亿次,但这次,危机在47分钟内被化解——Meta的AI内容审核系统通过多模态分析识别出视频异常:总统的嘴角运动频率与语音波形存在0.3秒的延迟,瞳孔收缩幅度与情绪表达不匹配,背景中的国旗褶皱不符合空气动力学模型。
"这是多模态NLP的典型应用。"斯坦福大学人工智能实验室主任李薇指出,"单一模态的检测准确率只有78%,但融合语音、图像、物理环境三重验证后,准确率能提升至99.7%。"她的团队开发的"时空一致性检测框架",正是中国《生成式人工智能服务管理暂行办法》中"深度伪造标识制度"的技术基础,该框架通过建立物理世界模型库,能实时比对视频中的光影变化、物体运动轨迹是否符合自然规律。
更值得关注的是,2026年6月,中国网信办要求所有生成式AI服务提供者必须接入"国家深度伪造检测平台",该平台采用分布式NLP架构,支持每秒处理10万条多媒体内容,其核心算法来自清华大学"天工"团队研发的"跨模态注意力机制"——能同时捕捉文本描述、图像特征、音频韵律之间的隐性关联,当用户输入"生成一张特朗普在白宫打篮球的图片"时,系统会对比历史影像中特朗普的身高数据、白宫室内篮球场的实际尺寸,自动修正生成结果的物理合理性。
实时风险评估:从"股市闪崩事件"看情感分析的突破
2026年9月14日,东京证券交易所遭遇"黑色13分钟":某AI交易系统因误读社交媒体情绪,触发连锁抛售,日经225指数暴跌8.2%,事后调查显示,系统将一条"某银行CEO辞职"的假新闻中的愤怒情绪误判为"市场信心增强"——传统情感分析模型只能识别"愤怒""喜悦"等基础情绪,而新出现的"语境化情感分析"技术能结合上下文理解情绪的真实指向。

"这就像人类读懂'反话'的能力。"东京大学教授山本健太郎解释道,他的团队开发的"动态语境建模"算法,能通过分析文本中的代词指代、修辞手法、历史对话记录,准确判断情绪的真实含义,当检测到"这家公司终于要倒闭了(微笑)"时,系统会结合发送者过去30天的发言记录,识别出"微笑"表情在此语境下实际表达的是嘲讽而非喜悦。
这项技术直接影响了全球金融监管政策,2026年10月,国际证券委员会组织(IOSCO)发布《AI交易系统风险管理指南》,要求所有量化交易模型必须内置"语境化情感分析"模块,中国证监会更进一步,在11月推出的《证券期货业人工智能应用管理办法》中明确:使用NLP技术进行市场情绪分析的机构,需每日提交"情绪-交易相关性报告",证明算法没有放大市场波动。 真实性验证:从"健康谣言战"看知识图谱的进化
2026年冬季,新型流感病毒"的谣言在全球社交媒体蔓延,一条"喝盐水能预防变异株"的帖子在48小时内获得2.3亿次转发,但这次,AI内容审核系统在12分钟内就标记为"高风险信息"——系统不仅检测到"盐水""预防"等关键词的异常组合,还通过知识图谱验证发现:该说法与世界卫生组织(WHO)最新指南中的127条医学证据完全矛盾。
本月绿色信息网与氢能技术持续升温,技术创新带来新突破 "这是知识增强型NLP的胜利。"百度首席科学家王海峰表示,他的团队构建的"医疗知识图谱"包含1.2亿个实体节点和38亿条关系边,覆盖了人类已知的所有疾病、药物、治疗手段,当系统检测到健康类内容时,会自动在图谱中进行"多跳推理":"盐水"→"电解质溶液"→"临床应用"→"不包含预防病毒感染"→"与WHO指南冲突"→"判定为谣言"。

这种技术能力直接推动了监管政策的升级,2026年12月,中国国家卫健委发布《医疗健康AI服务管理规范》,要求所有提供健康咨询的AI系统必须通过"知识图谱一致性测试",欧盟《人工智能法案》也新增条款:高风险医疗AI需定期更新知识库,确保与最新医学证据保持同步——这背后是NLP领域"持续学习"技术的突破,能让模型在不影响现有性能的情况下,动态吸收新知识。
透明度要求:从"贷款歧视案"看可解释AI的落地
2026年7月,旧金山联邦法院审理了一起AI信贷歧视案:某银行使用NLP模型分析借款人社交媒体数据,将"经常参加抗议活动"的用户自动归类为"高风险客户",原告律师使用"反事实解释"技术证明:如果删除该用户的政治相关发言,贷款通过率会从23%提升至71%,这一证据直接导致银行被判赔偿450万美元。
"这标志着可解释AI从理论走向实践。"卡内基梅隆大学教授汤姆·米切尔评价道,他参与制定的IEEE P7001标准(可解释AI透明度框架)在2026年成为全球监管参考模板,其核心要求包括:提供决策的"反事实解释"(即改变哪些输入会导致输出变化)、展示关键特征的影响权重、生成人类可读的决策报告。
中国在这方面走得更远,2026年8月实施的《个人信息保护法》修订案明确规定:使用NLP技术处理个人数据的机构,必须提供"算法影响评估报告",详细说明模型如何理解语言、哪些语义特征被赋予更高权重,某招聘AI的报告显示:系统将"连续创业"解读为"稳定性差(-0.6)"+"创新能力强(+0.4)",最终综合评分为-0.2——这种透明度要求迫使企业重新设计算法逻辑。
国际协作:从"AI治理联盟"看技术标准的统一
2026年11月,由中、美、欧牵头的"全球AI治理联盟"在日内瓦成立,其首个成果就是《NLP技术监管技术标准》,该标准统一了算法偏见检测的基准数据集(包含12种语言、200万条标注文本)、深度伪造检测的误差阈值(视频类≤0.5%,音频类≤1.2%)、知识图谱更新的最小频率(医疗领域每24小时,金融领域每4小时)。
"没有统一标准,监管就是纸上谈兵。"联盟技术委员会主席、图灵奖得主杨立昆指出,他举例说明:某跨国银行