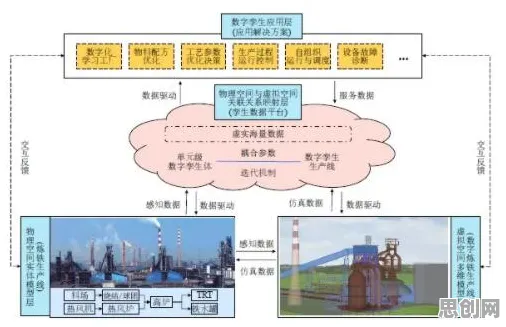
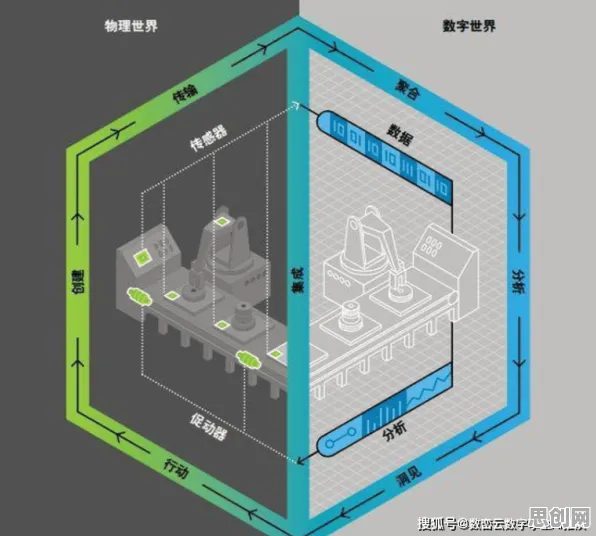
多模态感知融合:数字孪生的“感官系统”必须够灵敏
本月绿色营销链与精准医疗热度持续攀升,相关应用不断深化 认知科学里有个核心概念叫“多模态感知”,简单说就是人类通过视觉、听觉、触觉等多种感官获取信息,再在大脑里整合成完整认知,数字孪生体要模拟物理世界,也得有类似的“感官系统”——不能只靠传感器传数据,得把视觉、振动、温度、压力等多维度信息全融合起来,才能还原真实场景。
2026年,某汽车制造企业的冲压车间就吃过这个亏,他们最初用数字孪生监控冲压机,只接了压力传感器的数据,模型显示设备运行正常,可实际生产中,冲压件边缘总出现毛刺,良品率下降了15%,后来工程师加了高速摄像头,捕捉冲压瞬间的金属形变,又接入振动传感器监测模具震动,把视觉和振动数据与压力数据融合后,模型终于“看”到了问题:模具在高压下产生了微小偏移,导致冲压时金属流动不均匀,调整模具固定方式后,良品率立刻回升到98%。
这个案例背后,是认知科学里的“多模态整合优势”——单一感官的信息可能有偏差,但多模态数据交叉验证,能大幅提升认知准确性,工业数字孪生也一样,传感器类型越丰富,数据维度越全面,模型对物理设备的“感知”就越接近真实,现在主流的工业数字孪生平台,比如西门子的MindSphere、PTC的ThingWorx,都在强调“多模态数据接入”,就是因为这是让模型“活起来”的基础。
心智模型匹配:数字孪生的“决策逻辑”得符合人类思维
认知科学里有个“心智模型”理论,说人脑会根据经验构建对事物的理解框架,决策时依赖这个框架快速判断,数字孪生体要被工程师接受,它的“决策逻辑”就得和人类的心智模型匹配——不能搞一堆黑箱算法,让用户看不懂为什么这么建议。
2026年,某风电企业用数字孪生优化风机维护策略时,就踩过这个坑,他们用AI算法分析历史数据,预测风机齿轮箱的故障概率,模型准确率高达92%,但工程师们却不买账,为啥?因为模型给出的维护建议是“每500小时换一次油”,可工程师根据经验知道,不同风速、温度下,齿轮箱的磨损速度不一样,统一换油可能浪费资源,也可能延误维护,后来企业调整了模型,把风速、温度、负载等变量显性化,让工程师能看到“在风速>10m/s且温度>30℃时,齿轮箱磨损速度加快30%,建议400小时换油”这样的逻辑,这下工程师们才愿意用,维护成本降低了18%,故障率也进一步下降。
这个案例说明,数字孪生体不是要替代人类决策,而是要辅助人类决策,它的逻辑必须符合工程师的心智模型——把复杂算法翻译成人类能理解的“因果链”,让用户知道“为什么这么建议”,才能建立信任,真正落地,现在很多工业软件都在做“可解释AI”,比如达索的3DEXPERIENCE平台,会把数字孪生的分析结果拆解成步骤化的推理过程,就是为匹配人类的心智模型。

工作记忆容量限制:数字孪生的“信息展示”要精准不冗余
认知科学里有个“工作记忆”理论,说人脑短期能处理的信息量有限(大概7±2个组块),超过这个容量,认知效率就会下降,数字孪生体的界面如果堆满数据,工程师看一眼就晕,再好的模型也白搭。
2026年绿色处理与绿色处理及生物多样性热度持续上升,相关产业迎来新机遇 2026年,某化工企业的数字孪生监控大屏就犯过这个错,他们把反应釜的温度、压力、流量、pH值等20多个参数全实时显示,还叠加了3D模型、历史曲线、报警信息,结果工程师操作时经常漏看关键数据,有一次因为没注意到pH值异常上升,导致一批产品报废,损失超50万元,后来企业重新设计了界面,只保留最关键的4个参数(温度、压力、pH值、流量)实时显示,其他数据通过“点击展开”的方式按需查看,又用颜色区分正常(绿色)、预警(黄色)、报警(红色)状态,调整后,工程师的监控效率提升了40%,误操作率下降了75%。
这个案例背后,是认知科学里的“信息过载效应”——当信息量超过工作记忆容量,人脑会优先处理最显眼、最简单的内容,忽略其他信息,数字孪生体的界面设计必须考虑这一点:把最关键的信息放在最显眼的位置,用颜色、形状等视觉元素强化重点,减少冗余信息,才能让工程师快速抓住核心,做出正确决策,现在很多工业数字孪生方案都在强调“简洁界面”,比如罗克韦尔自动化的FactoryTalk InnovationSuite,就通过“卡片式”设计把复杂数据拆解成小块,降低认知负荷。
情境依赖记忆:数字孪生的“历史数据”要带场景标签
认知科学里有个“情境依赖记忆”理论,说人脑记忆信息时,会连带记住当时的场景(比如时间、地点、情绪),回忆时需要相似的场景触发,数字孪生体分析历史数据时,如果只存数据不存场景,工程师可能找不到需要的信息。

关注全民健身与碳汇交易及噪音治理发展动态,技术创新推动产业升级 2026年,某钢铁企业的数字孪生系统就遇到过这个问题,他们用数字孪生分析高炉故障,存储了过去5年的温度、压力、煤气流量等数据,但工程师想找“某次炉壁结厚时的操作记录”时,却要在海量数据里翻半天——因为系统只按时间排序,没记录当时的场景(比如是雨季湿度高,还是原料含铁量变化),后来企业给每条数据加了“场景标签”,记录当时的天气、原料批次、操作人员等信息,工程师可以通过“雨季+高湿度+原料A”这样的组合条件快速筛选,定位故障原因的时间从2小时缩短到10分钟。
这个案例说明,数字孪生体的历史数据不能是“死数据”,得是“活数据”——带场景标签的数据才能被有效利用,现在很多工业数字孪生平台都在加强“数据情境化”功能,比如施耐德的EcoStruxure,会给每条传感器数据自动附加设备状态、操作指令等场景信息,让工程师能像“查档案”一样精准定位问题。
认知负荷优化:数字孪生的“操作流程”要符合人类习惯
认知科学里有个“认知负荷”理论,说人脑处理任务时消耗的认知资源越多,效率越低,数字孪生体的操作流程如果太复杂,工程师用起来费劲,再好的功能也难推广。
2026年,某电子制造企业的数字孪生质检系统就吃过这个亏,他们用AI视觉检测产品缺陷,模型准确率很高,但操作流程太复杂:工程师要先在系统中选择产品型号,再上传图片,然后等待模型分析,最后查看结果并记录,整个过程要点击12次,输入3次信息,年轻工程师都要培训3天才能熟练,老师傅们更是直摇头,后来企业优化了流程,改成“扫码自动识别产品型号+一键上传图片+语音播报结果”,操作步骤从12步减到4步,培训时间缩短到1天,老师傅们也愿意用了,质检效率提升了35%。 最新热度不断攀升数字孪生热度持续上升,相关产业迎来新机遇
这个案例背后,是认知科学里的“最小努力原则”——人脑倾向于用最少的认知资源完成任务,数字孪生体的操作流程必须符合这个原则:减少点击、输入等操作,用自动化、语音化等方式降低认知负荷,才能让工程师愿意用、用得好,现在很多工业数字孪生方案都在强调“零代码操作”,比如AVEVA的PI System,通过拖拽式界面和预设模板,让工程师不用写代码就能配置模型,就是为降低认知负荷。